
آموزش رگرسیون لجستیک در یادگیری ماشین با پایتون

آموزش رگرسیون لجستیک در یادگیری ماشین با پایتون
در این درس از مجموعه آموزش برنامه نویسی سایت سورس باران، به آموزش رگرسیون لجستیک در یادگیری ماشین با پایتون خواهیم پرداخت.
پیشنهاد ویژه : پکیج آموزش طراحی وب سایت با پایتون و جنگو
مقدمه ای بر رگرسیون لجستیک در یادگیری ماشین با پایتون
رگرسیون لجستیک یک الگوریتم طبقه بندی یادگیری تحت نظارت است که برای پیش بینی احتمال یک متغیر هدف استفاده می شود. ماهیت متغیر هدف یا وابسته دوگانه است ، به این معنی که فقط دو کلاس ممکن وجود دارد.
به عبارت ساده، متغیر وابسته ماهیت دودویی دارد و داده ها را به صورت 1 کد می کند (مخفف موفقیت / بله) یا 0 (مخفف شکست / خیر).
از نظر ریاضی، یک مدل رگرسیون لجستیک P (1 = Y) را به عنوان تابعی از X پیش بینی می کند. این یکی از ساده ترین الگوریتم های ML است که می تواند برای مشکلات مختلف طبقه بندی مانند تشخیص هرزنامه ، پیش بینی دیابت ، تشخیص سرطان و غیره استفاده شود.
انواع رگرسیون لجستیک
به طور کلی، رگرسیون لجستیک به معنای رگرسیون لجستیک باینری است که متغیرهای باینری هدف دارد ، اما دو دسته دیگر از متغیرهای هدف وجود دارد که می تواند توسط آن پیش بینی شود. بر اساس تعداد این دسته ها ، رگرسیون لجستیک را می توان به انواع زیر تقسیم کرد –
دودویی یا دوجمله ای
در چنین نوع طبقه بندی، یک متغیر وابسته فقط دو نوع ممکن دارد 1 و 0. به عنوان مثال ، این متغیرها ممکن است موفقیت یا شکست را نشان دهند، بله یا نه، برد یا باخت و غیره.
چند جمله ای
در چنین نوعی از طبقه بندی ، متغیر وابسته می تواند 3 نوع یا بیشتر غیر مرتب داشته باشد یا انواع فاقد اهمیت کمی باشد. به عنوان مثال ، این متغیرها ممکن است “نوع A” یا “نوع B” یا “نوع C” را نشان دهند.
عادی
در چنین نوع طبقه بندی ، متغیر وابسته می تواند 3 یا بیشتر از انواع مرتب شده یا انواع دارای اهمیت کمی داشته باشد. به عنوان مثال ، این متغیرها ممکن است نمایانگر “ضعیف” یا “خوب” ، “بسیار خوب” ، “عالی” باشند و هر دسته می تواند نمرات مانند 0،1،2،3 داشته باشد.
فرضیات رگرسیون لجستیک
قبل از غوطه وری در اجرای رگرسیون لجستیک، باید از مفروضات زیر در مورد آن آگاه باشیم –
- در صورت رگرسیون لجستیک باینری، متغیرهای هدف باید همیشه باینری باشند و نتیجه مطلوب با عامل 1 نشان داده می شود.
- در مدل نباید هیچ چند همبستگی وجود داشته باشد، بدین معنی که متغیرهای مستقل باید از یکدیگر مستقل باشند.
- ما باید متغیرهای معنی دار را در مدل خود بگنجانیم.
- ما باید اندازه نمونه بزرگی را برای رگرسیون لجستیک انتخاب کنیم.
مدل رگرسیون لجستیک دودویی
ساده ترین شکل رگرسیون لجستیک ، رگرسیون لجستیک دودویی یا دوجمله ای است که در آن متغیر هدف یا وابسته می تواند فقط 2 نوع ممکن یا 1 یا 0 داشته باشد. این به ما امکان می دهد یک رابطه بین چند متغیر پیش بینی کننده و یک متغیر هدف دودویی / دوجمله ای را مدل کنیم. در صورت رگرسیون لجستیک ، تابع خطی اساساً به عنوان ورودی به یک تابع دیگر مانند … در رابطه زیر استفاده می شود –
|
1 |
h _ {\ theta} {(x)} = g (\ theta ^ {T} x) 𝑤ℎ𝑒𝑟𝑒 0≤h _ {\ theta} ≤1 |
در اینجا تابع لجستیک یا سیگموئید است که می تواند به صورت زیر ارائه شود –
|
1 |
g (z) = \ frac {1} {1 + e ^ {- z}} 𝑧 = \ theta ^ {T} |
منحنی تا سیگموئید را می توان با کمک نمودار زیر نشان داد. می توانیم مقادیر محور y را بین 0 تا 1 ببینیم و محور را از 0.5 عبور می دهیم.
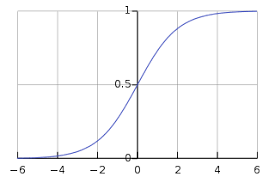
کلاسها را می توان به مثبت یا منفی تقسیم کرد. اگر بین 0 و 1 باشد ، خروجی تحت احتمال کلاس مثبت قرار می گیرد. برای اجرای ما ، ما خروجی تابع فرضیه را مثبت می دانیم اگر .50.5 باشد ، در غیر این صورت منفی است.
ما همچنین باید یک تابع از دست دادن را برای اندازه گیری عملکرد خوب الگوریتم با استفاده از وزن های توابع ، که توسط تتا به شرح زیر نشان داده شده است ، تعریف کنیم –
|
1 2 3 |
ℎ = 𝑔 (𝑋𝜃) J (\ theta) = \ frac {1} {m}. (- y ^ {T} log (h) - (1 -y) ^ Tlog (1-h)) |
اکنون ، پس از تعریف تابع ضرر، هدف اصلی ما به حداقل رساندن عملکرد ضرر است. این کار را می توان با کمک نصب وزنه ها انجام داد که به معنی افزایش یا کاهش وزن است. با کمک مشتقات عملکرد از دست دادن وزن هر وزن ، می توانیم بدانیم که چه پارامترهایی باید دارای وزن بالا باشند و چه وزن هایی باید وزن کمتری داشته باشند.
معادله نزولی گرادیان زیر به ما می گوید که اگر پارامترها را اصلاح کنیم ، ضرر چگونه تغییر می کند –
|
1 |
\ frac {𝛿𝐽 (𝜃)} {𝛿 \ theta_ {j}} = \ frac {1} {m} X ^ {T} (𝑔 (𝑋𝜃) −𝑦) |
پیاده سازی در پایتون
حال ما مفهوم فوق مربوط به رگرسیون لجستیکی دوجمله ای را در پایتون پیاده سازی خواهیم کرد. برای این منظور ، ما از یک مجموعه داده چند متغیره گل به نام ‘iris’ استفاده می کنیم که دارای 3 کلاس 50 نمونه است ، اما ما از دو ستون ویژگی اول استفاده خواهیم کرد. هر کلاس نماینده نوعی گل عنبیه است.
اول ، ما باید کتابخانه های لازم را به شرح زیر وارد کنیم –
|
1 2 3 4 |
import numpy as np import matplotlib.pyplot as plt import seaborn as sns from sklearn import datasets |
بعد ، مجموعه داده ‘iris’ را به شرح زیر بارگیری کنید –
|
1 2 3 |
iris = datasets.load_iris() X = iris.data[:, :2] y = (iris.target != 0) * 1 |
ما می توانیم داده های آموزش خود را به شرح زیر ترسیم کنیم –
|
1 2 3 4 |
plt.figure(figsize=(6, 6)) plt.scatter(X[y == 0][:, 0], X[y == 0][:, 1], color='g', label='0') plt.scatter(X[y == 1][:, 0], X[y == 1][:, 1], color='y', label='1') plt.legend(); |
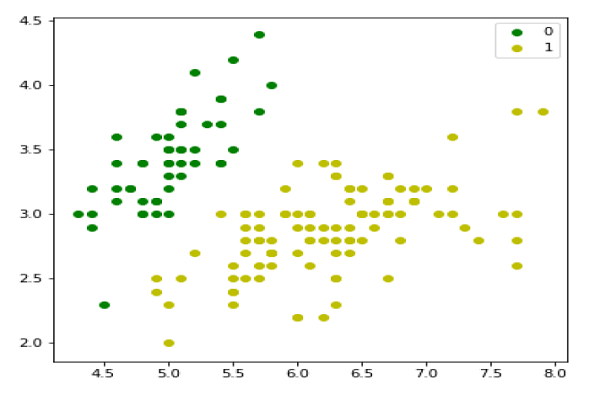
بعد ما تابع سیگموئید ، تابع ضرر و پایین آمدن شیب را به شرح زیر تعریف خواهیم کرد –
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
class LogisticRegression: def __init__(self, lr=0.01, num_iter=100000, fit_intercept=True, verbose=False): self.lr = lr self.num_iter = num_iter self.fit_intercept = fit_intercept self.verbose = verbose def __add_intercept(self, X): intercept = np.ones((X.shape[0], 1)) return np.concatenate((intercept, X), axis=1) def __sigmoid(self, z): return 1 / (1 + np.exp(-z)) def __loss(self, h, y): return (-y * np.log(h) - (1 - y) * np.log(1 - h)).mean() def fit(self, X, y): if self.fit_intercept: X = self.__add_intercept(X) |
با کمک اسکریپت زیر می توان احتمالات خروجی را پیش بینی کرد –
|
1 2 3 4 5 6 7 8 9 10 11 |
self.theta = np.zeros(X.shape[1]) for i in range(self.num_iter): z = np.dot(X, self.theta) h = self.__sigmoid(z) gradient = np.dot(X.T, (h - y)) / y.size self.theta -= self.lr * gradient z = np.dot(X, self.theta) h = self.__sigmoid(z) loss = self.__loss(h, y) if(self.verbose ==True and i % 10000 == 0): print(f'loss: {loss} \t') |
بعد ، ما می توانیم مدل را ارزیابی کنیم و آن را به صورت زیر ترسیم کنیم –
|
1 2 3 4 5 6 |
def predict_prob(self, X): if self.fit_intercept: X = self.__add_intercept(X) return self.__sigmoid(np.dot(X, self.theta)) def predict(self, X): return self.predict_prob(X).round() |
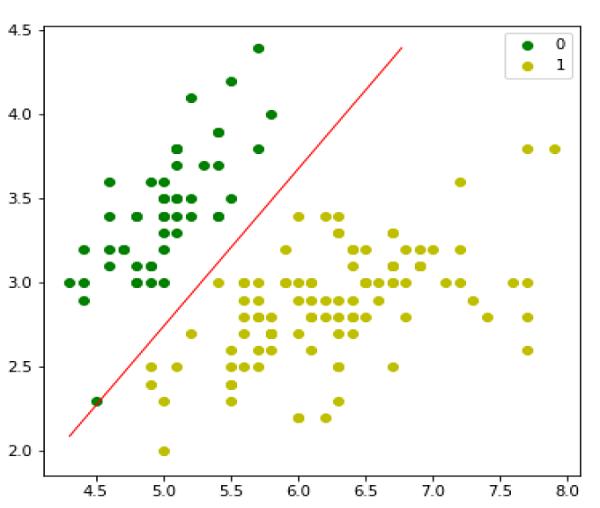
مدل رگرسیون لجستیک چند جمله ای
روش مفید دیگر رگرسیون لجستیک ، رگرسیون لجستیک چند جمله ای است که در آن متغیر هدف یا وابسته می تواند 3 نوع غیر مرتب شده یا بیشتر داشته باشد ، یعنی انواع فاقد اهمیت کمی.
پیاده سازی در پایتون
حال ما مفهوم فوق را برای رگرسیون لجستیک چند جمله ای در پایتون پیاده خواهیم کرد. برای این منظور، ما از یک مجموعه داده از sklearn با نام عددی استفاده می کنیم.
اول ، ما باید کتابخانه های لازم را به شرح زیر وارد کنیم –
|
1 2 3 4 5 |
Import sklearn from sklearn import datasets from sklearn import linear_model from sklearn import metrics from sklearn.model_selection import train_test_split |
بعد ، ما باید مجموعه داده عددی را بارگیری کنیم –
|
1 |
digits = datasets.load_digits() |
اکنون ماتریس ویژگی (X) و بردار پاسخ (y) را به صورت زیر تعریف کنید –
|
1 2 |
X = digits.data y = digits.targe |
با کمک خط بعدی کد ، ما می توانیم X و y را به مجموعه های آموزش و آزمایش تقسیم کنیم –
|
1 |
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=1) |
اکنون یک شکل از رگرسیون لجستیک به شرح زیر ایجاد کنید –
|
1 |
digreg = linear_model.LogisticRegression() |
اکنون ، ما باید مدل را با استفاده از مجموعه های آموزشی به شرح زیر آموزش دهیم –
|
1 |
digreg.fit(X_train, y_train) |
بعد ، پیش بینی مجموعه آزمایش را به شرح زیر انجام دهید –
|
1 |
digreg.fit(X_train, y_train) |
بعدی دقت مدل را به صورت زیر چاپ کنید –
|
1 2 |
print("Accuracy of Logistic Regression model is:", metrics.accuracy_score(y_test, y_pred)*100) |
خروجی
|
1 |
Accuracy of Logistic Regression model is: 95.6884561891516 |
از خروجی فوق می توانیم دقت مدل خود را در حدود 96 درصد ببینیم.
لیست جلسات قبل آموزش یادگیری ماشین با پایتون
- آموزش یادگیری ماشین با پایتون
- مبانی یادگیری ماشین با پایتون
- آموزش اکوسیستم یادگیری ماشین با پایتون
- آموزش متدها در یادگیری ماشین با پایتون
- آموزش بارگیری داده ها برای پروژه های یادگیری ماشین
- آموزش درک داده ها با آمار در یادگیری ماشین
- آموزش آماده سازی داده ها در یادگیری ماشین با پایتون
- آموزش انتخاب ویژگی داده ها در یادگیری ماشین با پایتون
- آموزش طبقه بندی در یادگیری ماشین با پایتون



.svg)
دیدگاه شما