
آموزش دریافت داده ها رگرسیون لجستیک در پایتون

آموزش دریافت داده ها رگرسیون لجستیک در پایتون
در این درس از مجموعه آموزش برنامه نویسی سایت سورس باران، به آموزش دریافت داده ها رگرسیون لجستیک در پایتون خواهیم پرداخت.
مراحل مربوط به بدست آوردن داده ها برای انجام رگرسیون لجستیک در پایتون به طور مفصل در این درس مورد بحث قرار گرفته است.
پیشنهاد ویژه : پکیج آموزش طراحی وب سایت با پایتون و جنگو
دانلود مجموعه داده
اگر قبلاً مجموعه داده UCI را که قبلاً ذکر شد دانلود نکرده اید، اکنون آن را از اینجا بارگیری کنید. روی پوشه داده کلیک کنید. صفحه زیر را مشاهده خواهید کرد –

با کلیک بر روی لینک داده شده ، فایل bank.zip را بارگیری کنید. فایل zip شامل پرونده های زیر است –

ما برای توسعه مدل خود از فایل bank.csv استفاده خواهیم کرد. فایل bank-names.txt حاوی شرح پایگاه داده ای است که بعداً به آن نیاز خواهید داشت. bank-full.csv شامل یک مجموعه داده بسیار بزرگتر است که می توانید برای پیشرفتهای پیشرفته تر از آن استفاده کنید.
در اینجا فایل bank.csv را در zip منبع قابل بارگیری قرار داده ایم. این پرونده شامل قسمتهای محدود شده با ویرگول است. ما همچنین چند تغییر در پرونده ایجاد کرده ایم. توصیه می شود برای یادگیری خود از فایلی که در ZIP منبع پروژه است استفاده کنید.
بارگیری داده ها
برای بارگذاری داده ها از پرونده csv که همین حالا کپی کرده اید ، عبارت زیر را تایپ کرده و کد را اجرا کنید.
|
1 |
In [2]: df = pd.read_csv('bank.csv', header=0) |
همچنین با اجرای عبارت کد زیر می توانید داده های بارگذاری شده را بررسی کنید –
|
1 |
IN [3]: df.head() |
پس از اجرای دستور، خروجی زیر را مشاهده خواهید کرد –
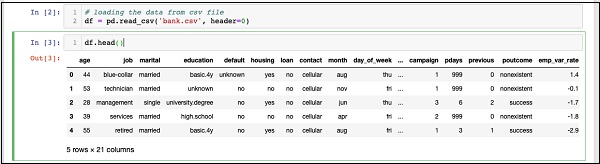
اساساً پنج ردیف اول داده بارگذاری شده را چاپ کرده است. 21 ستون موجود را بررسی کنید. ما فقط چند ستون از این ست ها برای توسعه مدل خود استفاده خواهیم کرد.
بعد باید داده ها را پاک کنیم. داده ها ممکن است حاوی چند ردیف با NaN باشند. برای حذف چنین سطرهایی، از دستور زیر استفاده کنید –
|
1 |
IN [4]: df = df.dropna() |
خوشبختانه، bank.csv هیچ ردیفی با NaN ندارد ، بنابراین این مرحله در مورد ما واقعاً لازم نیست. با این حال به طور کلی کشف چنین ردیف هایی در یک پایگاه داده عظیم دشوار است. بنابراین اجرای دستور بالا برای پاک کردن داده ها همیشه ایمن تر است.
توجه – با استفاده از عبارت زیر می توانید به راحتی اندازه داده را در هر زمان از زمان بررسی کنید –
|
1 2 |
IN [5]: print (df.shape) (41188, 21) |
همانطور که در سطر دوم بالا نشان داده شده است ، تعداد ردیف ها و ستون ها در خروجی چاپ می شوند.
کار بعدی این است که بررسی مناسب بودن هر ستون برای مدلی که می خواهیم بسازیم.
لیست جلسات قبل آموزش رگرسیون لجستیک در پایتون
- آموزش رگرسیون لجستیک در پایتون
- معرفی رگرسیون لجستیک در پایتون
- آموزش مطالعه موردی رگرسیون لجستیک در پایتون
- آموزش راه اندازی یک پروژه رگرسیون لجستیک در پایتون
- آموزش دریافت داده ها رگرسیون لجستیک در پایتون
- آموزش تجدید ساختار داده ها رگرسیون لجستیک در پایتون
- آموزش آماده سازی داده ها رگرسیون لجستیک در پایتون
- آموزش تقسیم داده ها رگرسیون لجستیک در پایتون
- آموزش طبقه بندی کننده ساختمان رگرسیون لجستیک در پایتون
- آموزش تست رگرسیون لجستیک در پایتون
- محدودیت های رگرسیون لجستیک در پایتون



.svg)
دیدگاه شما