
آموزش آماده سازی داده ها رگرسیون لجستیک در پایتون
5 سال پیش

آموزش آماده سازی داده ها رگرسیون لجستیک در پایتون
در این درس از مجموعه آموزش برنامه نویسی سایت سورس باران، به آموزش آماده سازی داده ها رگرسیون لجستیک در پایتون خواهیم پرداخت.
پیشنهاد ویژه : پکیج آموزش پروژه محور پایتون
برای ایجاد طبقه بندی، ما باید داده ها را در قالبی که توسط ماژول ساختمان طبقه بندی کننده درخواست می شود ، آماده کنیم. ما داده ها را با انجام One Hot Encoding آماده می کنیم.
رمزگذاری داده ها
به زودی در مورد منظور از رمزگذاری داده ها بحث خواهیم کرد. ابتدا اجازه دهید کد را اجرا کنیم. دستور زیر را در پنجره کد اجرا کنید.
|
1 2 |
In [10]: # creating one hot encoding of the categorical columns. data = pd.get_dummies(df, columns =['job', 'marital', 'default', 'housing', 'loan', 'poutcome']) |
همانطور که در اظهار نظر آمده است ، عبارت بالا یک رمزگذاری داغ را ایجاد می کند. بگذارید ببینیم چه چیزی ایجاد کرده است؟ با چاپ رکوردهای اصلی در پایگاه داده، داده های ایجاد شده به نام “data” را بررسی کنید.
|
1 |
In [11]: data.head() |
خروجی زیر را مشاهده خواهید کرد –
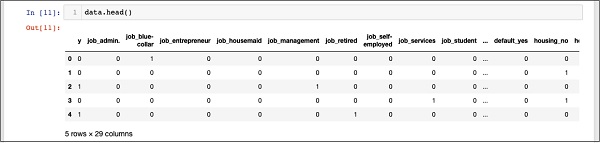
برای درک داده های فوق ، با اجرای دستور data.columns همانطور که در زیر نشان داده شده است ، نام ستون ها را لیست می کنیم –
|
1 2 3 4 5 6 7 8 9 |
In [12]: data.columns Out[12]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur', 'job_housemaid', 'job_management', 'job_retired', 'job_self-employed', 'job_services', 'job_student', 'job_technician', 'job_unemployed', 'job_unknown', 'marital_divorced', 'marital_married', 'marital_single', 'marital_unknown', 'default_no', 'default_unknown', 'default_yes', 'housing_no', 'housing_unknown', 'housing_yes', 'loan_no', 'loan_unknown', 'loan_yes', 'poutcome_failure', 'poutcome_nonexistent', 'poutcome_success'], dtype='object') |
حال ، ما توضیح خواهیم داد که چگونه رone hot encoding توسط دستور get_dummies انجام می شود. اولین ستون در پایگاه داده تازه ایجاد شده قسمت “y” است که نشان می دهد آیا این مشتری در TD مشترک شده است یا خیر. اکنون ، اجازه دهید ستون های رمزگذاری شده را بررسی کنیم. اولین ستون رمزگذاری شده “کار” است. در پایگاه داده ، متوجه خواهید شد که ستون “job” دارای مقادیر زیادی مانند “admin”, “blue-collar”, “entrepreneur” و غیره است. برای هر مقدار ممکن ، یک ستون جدید در پایگاه داده ایجاد کرده ایم که نام ستون به عنوان پیشوند ضمیمه شده است.
بنابراین، ستون هایی به نام “job_admin” ، “job_blue-collar” و غیره داریم. برای هر قسمت رمزگذاری شده در پایگاه داده اصلی ما، لیستی از ستون های اضافه شده در پایگاه داده ایجاد شده با تمام مقادیر ممکن که ستون در پایگاه داده اصلی می گیرد ، پیدا خواهید کرد. لیست ستون ها را با دقت بررسی کنید تا بفهمید که چگونه نقشه ها به یک پایگاه داده جدید ترسیم می شوند.
درک نقشه نگاری
برای درک داده های تولید شده ، اجازه دهید کل داده ها را با استفاده از دستور data چاپ کنیم. خروجی جزئی پس از اجرای دستور در زیر نشان داده شده است.
|
1 |
In [13]: data |
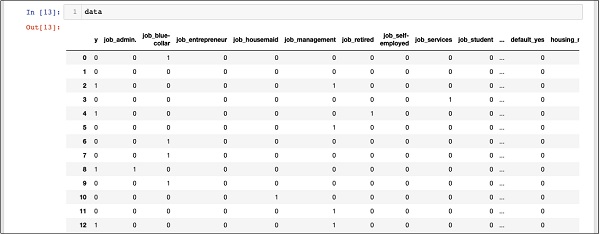
صفحه فوق دوازده ردیف اول را نشان می دهد. اگر بیشتر به پایین بروید ، می بینید که نقشه برداری برای همه ردیف ها انجام شده است.
یک خروجی صفحه نمایش جزئی در پایین پایگاه داده برای مرجع سریع شما در اینجا نشان داده شده است.
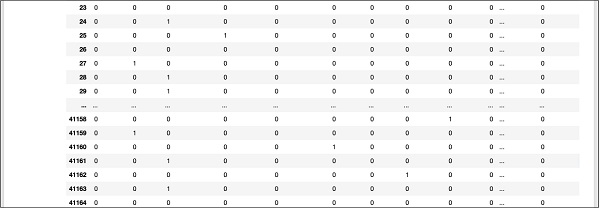
برای درک داده های ترسیم شده ، اجازه دهید ردیف اول را بررسی کنیم.

این می گوید که این مشتری در TD مشترک نشده است همانطور که با مقدار در قسمت “y” نشان داده شده است. این همچنین نشان می دهد که این مشتری یک مشتری“blue-collar” است. با پیمایش افقی به پایین به شما می گوید که او “خانه” دارد و “وام” نگرفته است.
بعد از این یک کدگذاری داغ ، قبل از شروع ساخت مدل خود به پردازش داده دیگری نیاز داریم.
“unknown”
اگر ستون ها را در پایگاه داده نگاشت شده بررسی کنیم ، وجود چند ستون را پیدا می کنید که با “unknown” ختم می شوند. به عنوان مثال ، ستون را در شاخص 12 با دستور زیر که در تصویر نشان داده شده است ، بررسی کنید –
|
1 2 |
In [14]: data.columns[12] Out[14]: 'job_unknown' |
این نشان می دهد کار برای مشتری مشخص مشخص نیست. بدیهی است که درج چنین ستونهایی در تجزیه و تحلیل و مدل سازی ما فایده ای ندارد. بنابراین ، تمام ستون های دارای مقدار “unknown” باید حذف شوند. این کار با دستور زیر انجام می شود –
|
1 |
In [15]: data.drop(data.columns[[12, 16, 18, 21, 24]], axis=1, inplace=True) |
اطمینان حاصل کنید که شماره ستون را به درستی تعیین کرده اید. در صورت تردید ، می توانید نام ستون را در هر زمان با تعیین شاخص آن در دستور ستون ها همانطور که قبلا توضیح داده شد ، بررسی کنید.
پس از رها کردن ستون های نامطلوب ، می توانید لیست نهایی ستون ها را همانطور که در خروجی زیر نشان داده شده است ، بررسی کنید –
|
1 2 3 4 5 6 7 8 |
In [16]: data.columns Out[16]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur', 'job_housemaid', 'job_management', 'job_retired', 'job_self-employed', 'job_services', 'job_student', 'job_technician', 'job_unemployed', 'marital_divorced', 'marital_married', 'marital_single', 'default_no', 'default_yes', 'housing_no', 'housing_yes', 'loan_no', 'loan_yes', 'poutcome_failure', 'poutcome_nonexistent', 'poutcome_success'], dtype='object') |
در این مرحله، داده های ما برای ساخت مدل آماده است.
لیست جلسات قبل آموزش رگرسیون لجستیک در پایتون
- آموزش رگرسیون لجستیک در پایتون
- معرفی رگرسیون لجستیک در پایتون
- آموزش مطالعه موردی رگرسیون لجستیک در پایتون
- آموزش راه اندازی یک پروژه رگرسیون لجستیک در پایتون
- آموزش دریافت داده ها رگرسیون لجستیک در پایتون
- آموزش تجدید ساختار داده ها رگرسیون لجستیک در پایتون
- آموزش آماده سازی داده ها رگرسیون لجستیک در پایتون
- آموزش تقسیم داده ها رگرسیون لجستیک در پایتون
- آموزش طبقه بندی کننده ساختمان رگرسیون لجستیک در پایتون
- آموزش تست رگرسیون لجستیک در پایتون
- محدودیت های رگرسیون لجستیک در پایتون
نویسنده مطلب
saber



.svg)
دیدگاه شما