
هوش مصنوعی با پایتون، یادگیری نظارت شده و طبقه بندی

هوش مصنوعی با برنامه نویسی پایتون، یادگیری نظارت شده و طبقه بندی
در این درس از مجموعه آموزش برنامه نویسی سایت سورس باران، ما بر اجرای یادگیری نظارت شده و طبقه بندی تمرکز خواهیم کرد.
پیشنهاد ویژه : پکیج آموزش صفر تا صد پایتون
روش طبقه بندی یا مدل سعی در نتیجه گیری از مقادیر مشاهده شده دارد. در مسئله طبقه بندی، ما خروجی طبقه بندی شده ای مانند “Black” or “white” or “Teaching” and “Non-Teaching” داریم. هنگام ساخت مدل طبقه بندی، ما باید مجموعه داده های آموزشی داشته باشیم که شامل نقاط داده و برچسب های مربوطه باشد. به عنوان مثال، اگر می خواهیم بررسی کنیم که آیا تصویر ماشین است یا نه. برای بررسی این، ما یک مجموعه داده آموزشی خواهیم ساخت که دارای دو کلاس مربوط به “car” و “no car” است. سپس ما نیاز به آموزش مدل با استفاده از نمونه های آموزشی داریم. مدل های طبقه بندی عمدتا در شناسایی چهره، شناسایی هرزنامه و غیره استفاده می شوند.
مراحل ساخت طبقه بندی در پایتون
برای ساخت یک طبقه بندی در پایتون، ما قصد داریم از Python 3 و Scikit-learn استفاده کنیم که ابزاری برای یادگیری ماشین است. برای ساخت یک طبقه بندی در پایتون این مراحل را دنبال کنید
مرحله 1 – وارد کردن Scikit-learn
این اولین قدم برای ساخت یک طبقه بندی در پایتون است. در این مرحله، ما یک بسته پایتون به نام Scikit-learn نصب می کنیم که یکی از بهترین ماژول های یادگیری ماشین در پایتون است. دستور زیر به ما کمک می کند پکیج را وارد کنیم –
|
1 |
Import Sklearn |
مرحله 2 – وارد کردن مجموعه داده های Scikit-learn
در این مرحله، ما می توانیم کار با مجموعه داده را برای مدل یادگیری ماشین خود شروع کنیم. در اینجا، ما می خواهیم از پایگاه داده تشخیصی سرطان سینه ویسکانسین استفاده کنیم. این مجموعه اطلاعات شامل اطلاعات مختلفی در مورد تومورهای سرطان پستان و همچنین برچسب های طبقه بندی از بدخیم یا خوش خیم است. این مجموعه داده 569 مورد یا داده در مورد 569 تومور دارد و شامل اطلاعات مربوط به 30 ویژگی یا ویژگی مانند شعاع تومور، بافت، صافی و ناحیه می باشد. با کمک دستور زیر می توانیم مجموعه داده های سرطان پستان Scikit-learn را وارد کنیم –
|
1 |
from sklearn.datasets import load_breast_cancer |
اکنون دستور زیر مجموعه داده را بارگیری می کند.
|
1 |
data = load_breast_cancer() |
در زیر لیستی از کلیدهای مهم دیکشنری آورده شده است –
- نام برچسب های طبقه بندی (target_names)
- برچسب های واقعی (target)
- نام ویژگی ها / ویژگی ها (feature_names)
- ویژگی (data)
حال با کمک دستور زیر می توان متغیرهای جدیدی را برای هر مجموعه اطلاعات مهم ایجاد کرد و داده ها را اختصاص داد. به عبارت دیگر، ما می توانیم داده ها را با دستورات زیر سازماندهی کنیم –
|
1 2 3 4 |
label_names = data['target_names'] labels = data['target'] feature_names = data['feature_names'] features = data['data'] |
اکنون، برای شفاف سازی بیشتر می توانیم برچسب های کلاس، برچسب نمونه داده اول، نام ویژگی های و مقدار ویژگی را با کمک دستورات زیر چاپ کنیم –
|
1 |
print(label_names) |
دستور فوق به ترتیب نام های کلاس را که به ترتیب بدخیم و خوش خیم هستند چاپ می کند. این به عنوان خروجی زیر نشان داده شده است –
|
1 |
['malignant' 'benign'] |
اکنون، دستور زیر نشان می دهد که آنها به مقادیر دودویی 0 و 1 ترسیم شده اند. در اینجا 0 نشان دهنده سرطان بدخیم و 1 نشان دهنده سرطان خوش خیم است. شما خروجی زیر را دریافت خواهید کرد –
|
1 2 |
print(labels[0]) 0 |
دو دستور داده شده در زیر نام ویژگی ها و مقادیر ویژگی را تولید می کنند.
|
1 2 3 4 5 6 7 8 9 10 11 |
print(feature_names[0]) mean radius print(features[0]) [ 1.79900000e+01 1.03800000e+01 1.22800000e+02 1.00100000e+03 1.18400000e-01 2.77600000e-01 3.00100000e-01 1.47100000e-01 2.41900000e-01 7.87100000e-02 1.09500000e+00 9.05300000e-01 8.58900000e+00 1.53400000e+02 6.39900000e-03 4.90400000e-02 5.37300000e-02 1.58700000e-02 3.00300000e-02 6.19300000e-03 2.53800000e+01 1.73300000e+01 1.84600000e+02 2.01900000e+03 1.62200000e-01 6.65600000e-01 7.11900000e-01 2.65400000e-01 4.60100000e-01 1.18900000e-01] |
از خروجی فوق می توان دریافت که اولین نمونه داده، توموری بدخیم است که شعاع آن 1.7990000e + 01 است.
مرحله 3 – سازماندهی داده ها در مجموعه ها
در این مرحله، ما داده های خود را به دو قسمت یعنی یک مجموعه آموزش و یک مجموعه تست تقسیم می کنیم. تقسیم داده ها به این مجموعه ها بسیار مهم است زیرا ما باید مدل خود را بر روی داده های نادیده آزمایش کنیم. برای تقسیم داده ها به مجموعه ها، sklearn تابعی به نام تابع ()train_test_split دارد. با کمک دستورات زیر می توانیم داده ها را در این مجموعه ها تقسیم کنیم –
|
1 |
from sklearn.model_selection import train_test_split |
دستور فوق تابع train_test_split را از sklearn وارد کرده و دستور زیر داده ها را به داده های آموزش و تست تقسیم می کند. در مثالی که در زیر آورده شده است، ما از 40٪ داده ها برای آزمایش استفاده می کنیم و داده های باقیمانده برای آموزش مدل استفاده می شود.
|
1 |
train, test, train_labels, test_labels = train_test_split(features,labels,test_size = 0.40, random_state = 42) |
در این مرحله، ما در حال ساخت مدل خود هستیم. ما قصد داریم از الگوریتم Naïve Bayes برای ساخت مدل استفاده کنیم. برای ساخت مدل می توان از دستورات زیر استفاده کرد –
|
1 |
from sklearn.naive_bayes import GaussianNB |
دستور بالا ماژول GaussianNB را وارد می کند. اکنون، دستور زیر به شما کمک می کند تا مدل را اولیه کنید.
|
1 |
gnb = GaussianNB() |
ما با استفاده از ()gnb.fit مدل را متناسب با داده ها آموزش خواهیم داد.
|
1 |
model = gnb.fit(train, train_labels) |
مرحله 5 – ارزیابی مدل و صحت آن
در این مرحله، ما می خواهیم با پیش بینی داده های تست خود، مدل را ارزیابی کنیم. سپس به صحت آن نیز پی خواهیم برد. برای پیش بینی، از تابع ()predict استفاده خواهیم کرد. دستور زیر به شما در انجام این کار کمک می کند –
|
1 2 3 4 5 6 7 8 9 10 11 |
preds = gnb.predict(test) print(preds) [1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1 0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 0 0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 0 1 1 1 1 1 1 0 1 1 0 0 0 0 0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0 1 1 0 1 1 0 0 0 1 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 1 1 0 1 1 0 0 1 0 1 1 0 1 0 0 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1 0 0 0 1 1 0 1 0 1 1 1 1 0 1 1 0 1 1 1 0 1 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 1 0 0 1 1 0 1] |
سری های 0 و 1 مقادیر پیش بینی شده برای گروه های تومور – بدخیم و خوش خیم هستند.
حال با مقایسه دو آرایه یعنی test_labels و preds ، می توانیم از صحت مدل خود پی ببریم. ما برای تعیین دقت از تابع () precize_score استفاده می کنیم. برای این کار دستور زیر را در نظر بگیرید –
|
1 2 3 |
from sklearn.metrics import accuracy_score print(accuracy_score(test_labels,preds)) 0.951754385965 |
نتیجه نشان می دهد که طبقه بندی NaïveBayes 95.17٪ دقیق است.
به این ترتیب با کمک مراحل فوق می توانیم طبقه بندی خود را در پایتون بسازیم.
طبقه بندی ساختمان در پایتون
در این بخش، ما می آموزیم که چگونه یک طبقه بندی کننده در پایتون بسازیم.
طبقه بندی کننده Naïve Bayes
Naïve Bayes یک تکنیک طبقه بندی است که برای ساخت طبقه بندی با استفاده از قضیه Naïve Bayes استفاده می شود. فرض این است که پیش بینی کنندگان مستقل هستند. به عبارت ساده فرض بر این است که وجود یک ویژگی خاص در یک کلاس با وجود ویژگی دیگر ارتباطی ندارد. برای ساخت طبقه بندی Naïve Bayes باید از کتابخانه پایتون بنام scikit learn استفاده کنیم. سه نوع مدل Naïve Bayes به نام های Gaussian ،Multinomial و Bernoulli تحت بسته یادگیری دقیق وجود دارد.
برای ساخت یک مدل طبقه بندی یادگیری ماشین Naïve Bayes، به موارد زیر و منفی نیاز داریم
مجموعه داده
ما قصد داریم از مجموعه داده ای به نام Breast Cancer Wisconsin Diagnostic Database استفاده کنیم. این مجموعه داده شامل اطلاعات مختلفی در مورد تومورهای سرطان پستان و همچنین برچسب های طبقه بندی از بدخیم یا خوش خیم است. این مجموعه داده 569 مورد یا داده در مورد 569 تومور دارد و شامل اطلاعات مربوط به 30 ویژگی یا ویژگی مانند شعاع تومور، باف ، صافی و ناحیه است. ما می توانیم این مجموعه داده را از بسته sklearn وارد کنیم.
مدل Naïve Bayes
برای ساخت طبقه بندی Naïve Bayes، ما به یک مدل Naïve Bayes نیاز داریم. همانطور که قبلاً گفته شد، سه نوع مدل Naïve Bayes به نام هایGaussian ،Multinomial و Bernoulli تحت پکیج یادگیری دقیق وجود دارد. در اینجا، در مثال زیر قصد داریم از مدل Na Gve Bayes Gaussian استفاده کنیم.
با استفاده از موارد فوق، ما قصد داریم یک مدل یادگیری ماشین Naïve Bayes بسازیم تا با استفاده از اطلاعات تومور، بدخیمی یا خوش خیم بودن تومور را پیش بینی کنیم.
برای شروع، ماژول sklearn را باید نصب کنیم. این را می توان با کمک دستور زیر انجام داد –
|
1 |
Import Sklearn |
اکنون، ما باید مجموعه داده ای را با نام Breast Cancer Wisconsin Diagnostic Database وارد کنیم.
|
1 |
from sklearn.datasets import load_breast_cancer |
اکنون، دستور زیر مجموعه داده را بارگیری می کند.
|
1 |
data = load_breast_cancer() |
داده ها را می توان به صورت زیر سازماندهی کرد –
|
1 2 3 4 |
label_names = data['target_names'] labels = data['target'] feature_names = data['feature_names'] features = data['data'] |
اکنون برای ایجاد شفافیت بیشتر می توانیم برچسب های کلاس، برچسب نمونه داده اول، نام ویژگی های ما و مقدار ویژگی را با کمک دستورات زیر چاپ کنیم –
|
1 |
print(label_names) |
دستور فوق به ترتیب نام های کلاس را که به ترتیب بدخیم و خوش خیم هستند چاپ می کند. این به عنوان خروجی زیر نشان داده شده است –
|
1 |
['malignant' 'benign'] |
اکنون، دستور زیر نشان می دهد که آنها به مقادیر دودویی 0 و 1 ترسیم شده اند. در اینجا 0 نشان دهنده سرطان بدخیم و 1 نشان دهنده سرطان خوش خیم است. این به عنوان خروجی زیر نشان داده شده است –
|
1 2 |
print(labels[0]) 0 |
دو دستور زیر نام ویژگی ها و مقادیر ویژگی را تولید می کنند.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
rint(feature_names[0]) mean radius print(features[0]) [ 1.79900000e+01 1.03800000e+01 1.22800000e+02 1.00100000e+03 1.18400000e-01 2.77600000e-01 3.00100000e-01 1.47100000e-01 2.41900000e-01 7.87100000e-02 1.09500000e+00 9.05300000e-01 8.58900000e+00 1.53400000e+02 6.39900000e-03 4.90400000e-02 5.37300000e-02 1.58700000e-02 3.00300000e-02 6.19300000e-03 2.53800000e+01 1.73300000e+01 1.84600000e+02 2.01900000e+03 1.62200000e-01 6.65600000e-01 7.11900000e-01 2.65400000e-01 4.60100000e-01 1.18900000e-01] |
از خروجی فوق، می بینیم که اولین نمونه داده ها یک تومور بدخیم است که شعاع اصلی آن 1.7990000e + 01 است.
برای آزمایش مدل خود بر روی داده های دیده نشده، باید داده های خود را به داده های آموزش و تست تقسیم کنیم. این کار با کمک کد زیر انجام می شود –
|
1 |
from sklearn.model_selection import train_test_split |
دستور فوق تابع train_test_split را از sklearn وارد کرده و دستور زیر داده ها را به داده های آموزش و آزمایش تقسیم می کند. در مثال زیر ، ما از 40٪ داده ها برای آزمایش استفاده می کنیم و از داده های بازیابی برای آموزش مدل استفاده می شود.
|
1 2 |
train, test, train_labels, test_labels = train_test_split(features,labels,test_size = 0.40, random_state = 42) |
اکنون، ما در حال ساخت مدل با دستورات زیر هستیم –
|
1 |
from sklearn.naive_bayes import GaussianNB |
دستور بالا ماژول GaussianNB را وارد می کند. اکنون ، با دستوری که در زیر آورده شده است ، باید مدل را مقدار دهی اولیه کنیم.
|
1 |
gnb = GaussianNB() |
ما با استفاده از ()gnb.fit مدل را متناسب با داده ها آموزش خواهیم داد.
|
1 |
model = gnb.fit(train, train_labels) |
اکنون، مدل را با پیش بینی داده های تست را ارزیابی کنید و می توان آن را به صورت زیر انجام داد –
|
1 2 3 4 5 6 7 8 9 10 11 |
preds = gnb.predict(test) print(preds) [1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1 0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 0 0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 0 1 1 1 1 1 1 0 1 1 0 0 0 0 0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0 1 1 0 1 1 0 0 0 1 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 1 1 0 1 1 0 0 1 0 1 1 0 1 0 0 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1 0 0 0 1 1 0 1 0 1 1 1 1 0 1 1 0 1 1 1 0 1 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 1 0 0 1 1 0 1] |
سری فوق 0 و 1 مقادیر پیش بینی شده برای گروه های تومور یعنی بدخیم و خوش خیم هستند.
حال ، با مقایسه دو آرایه یعنی test_labels و preds ، می توانیم از صحت مدل خود پی ببریم. ما برای تعیین دقت از تابع () precize_score استفاده می کنیم. دستور زیر را در نظر بگیرید –
|
1 2 3 |
from sklearn.metrics import accuracy_score print(accuracy_score(test_labels,preds)) 0.951754385965 |
نتیجه نشان می دهد که طبقه بندی NaïveBayes 95.17٪ دقیق است.
این طبقه بندی کلاس یادگیری ماشینی بر اساس مدل Naïve Bayse Gaussian بود.
ماشین های برداری پشتیبانی (SVM)
اساساً، ماشین بردار پشتیبانی (SVM) یک الگوریتم یادگیری ماشین تحت نظارت است که می تواند برای رگرسیون و طبقه بندی استفاده شود. مفهوم اصلی SVM ترسیم هر مورد داده به عنوان یک نقطه در فضای n بعدی است که مقدار هر ویژگی مقدار مختصات خاص است. در اینجا n می تواند ویژگی های ما باشد. در زیر یک نمایش گرافیکی ساده برای درک مفهوم SVM آورده شده است –
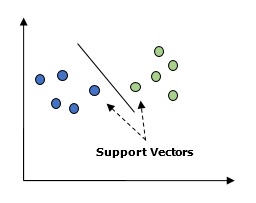
در نمودار بالا، دو ویژگی داریم. از این رو ابتدا باید این دو متغیر را در فضای دو بعدی ترسیم کنیم که هر نقطه دارای دو مختصات است، به نام بردارهای پشتیبانی. خط داده ها را به دو گروه طبقه بندی شده مختلف تقسیم می کند. این خط طبقه بندی کننده خواهد بود.
در اینجا، ما می خواهیم یک طبقه بندی SVM را با استفاده از مجموعه داده های scikit-learn و iris بسازیم. کتابخانه Scikitlearn دارای ماژول sklearn.svm است و sklearn.svm.svc را برای طبقه بندی ارائه می دهد. طبقه بندی SVM برای پیش بینی طبقه گیاه عنبیه بر اساس 4 ویژگی در زیر نشان داده شده است.
مجموعه داده
ما از مجموعه عنبیه استفاده خواهیم کرد که شامل 3 کلاس با 50 نمونه است ، هر کلاس به نوعی گیاه عنبیه اشاره دارد. هر نمونه دارای چهار ویژگی است یعنی طول کاسبرگ، عرض کاسبرگ، طول گلبرگ و عرض گلبرگ. طبقه بندی SVM برای پیش بینی طبقه گیاه عنبیه بر اساس 4 ویژگی در زیر نشان داده شده است.
هسته
این روشی است که توسط SVM استفاده می شود. اصولاً این توابع هستند که فضای ورودی با ابعاد کم را می گیرند و آن را به فضای بعدی بالاتر تبدیل می کنند. این مسئله غیر قابل تفکیک را به مسئله قابل تفکیک تبدیل می کند. تابع هسته می تواند هر یک از خطی، چند جمله ای، rbf و سیگموئید باشد. در این مثال از هسته خطی استفاده خواهیم کرد.
اکنون اجازه دهید پکیج های زیر را وارد کنیم:
|
1 2 3 4 |
import pandas as pd import numpy as np from sklearn import svm, datasets import matplotlib.pyplot as plt |
اکنون، داده های ورودی را بارگیری کنید –
|
1 |
iris = datasets.load_iris() |
ما در حال گرفتن دو ویژگی اول هستیم –
|
1 2 |
X = iris.data[:, :2] y = iris.target |
ما مرزهای ماشین بردار پشتیبانی را با داده های اصلی ترسیم خواهیم کرد. ما در حال ایجاد یک مش برای طراحی هستیم.
|
1 2 3 4 5 6 |
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1 y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1 h = (x_max / x_min)/100 xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) X_plot = np.c_[xx.ravel(), yy.ravel |
ما باید مقدار پارامتر تنظیم را ارائه دهیم.
|
1 |
C = 1.0 |
ما باید شی class طبقه بندی کننده SVM را ایجاد کنیم.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
Svc_classifier = svm_classifier.SVC(kernel='linear', C=C, decision_function_shape = 'ovr').fit(X, y) Z = svc_classifier.predict(X_plot) Z = Z.reshape(xx.shape) plt.figure(figsize = (15, 5)) plt.subplot(121) plt.contourf(xx, yy, Z, cmap = plt.cm.tab10, alpha = 0.3) plt.scatter(X[:, 0], X[:, 1], c = y, cmap = plt.cm.Set1) plt.xlabel('Sepal length') plt.ylabel('Sepal width') plt.xlim(xx.min(), xx.max()) plt.title('SVC with linear kernel') |
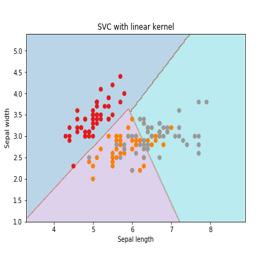
رگرسیون لجستیک
اساساً، مدل رگرسیون لجستیک یکی از اعضای خانواده الگوریتم طبقه بندی تحت نظارت است. رگرسیون لجستیک با تخمین احتمالات با استفاده از یک تابع لجستیک، رابطه بین متغیرهای وابسته و متغیرهای مستقل را اندازه گیری می کند.
در اینجا، اگر در مورد متغیرهای وابسته و مستقل صحبت کنیم، متغیر وابسته متغیر کلاس هدف است که ما می خواهیم پیش بینی کنیم و در طرف دیگر متغیرهای مستقل ویژگی هایی هستند که ما می خواهیم برای پیش بینی کلاس هدف استفاده کنیم.
در رگرسیون لجستیک، تخمین احتمالات به معنای پیش بینی احتمال وقوع واقعه است. به عنوان مثال، صاحب مغازه مایل است مشتری را که وارد مغازه شده است ایستگاه بازی را خریداری کند یا خیر. بسیاری از ویژگی های مشتری – جنسیت، سن و غیره وجود دارد که توسط صاحب مغازه مشاهده می شود تا احتمال وقوع، یعنی خرید یک ایستگاه بازی اتفاق می افتد یا خیر. تابع لجستیک منحنی سیگموئید است که برای ساخت تابع با پارامترهای مختلف استفاده می شود.
پیش نیازها
قبل از ساخت طبقه بندی با استفاده از رگرسیون لجستیک ، باید بسته Tkinter را روی سیستم خود نصب کنیم. از طریق https://docs.python.org/2/library/tkinter.html قابل نصب است.
اکنون، با کمک کدی که در زیر آورده شده است، می توانیم یک طبقه بندی با استفاده از رگرسیون لجستیک ایجاد کنیم –
ابتدا، برخی پکیج ها را وارد خواهیم کرد –
|
1 2 3 |
import numpy as np from sklearn import linear_model import matplotlib.pyplot as plt |
اکنون، ما باید نمونه داده ای را تعریف کنیم که می تواند به صورت زیر انجام شود –
|
1 2 3 |
X = np.array([[2, 4.8], [2.9, 4.7], [2.5, 5], [3.2, 5.5], [6, 5], [7.6, 4], [3.2, 0.9], [2.9, 1.9],[2.4, 3.5], [0.5, 3.4], [1, 4], [0.9, 5.9]]) y = np.array([0, 0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 3]) |
بعد، ما باید طبقه بندی رگرسیون لجستیک را ایجاد کنیم ، که می تواند به صورت زیر انجام شود –
|
1 |
Classifier_LR = linear_model.LogisticRegression(solver = 'liblinear', C = 75) |
آخرین اما نه کمترین، ما نیاز به آموزش این طبقه بندی داریم –
|
1 |
Classifier_LR.fit(X, y) |
حال ، چگونه می توانیم خروجی را تجسم کنیم؟ این را می توان با ایجاد یک تابع به نام ()Logistic_visualize انجام داد –
|
1 2 3 |
Def Logistic_visualize(Classifier_LR, X, y): min_x, max_x = X[:, 0].min() - 1.0, X[:, 0].max() + 1.0 min_y, max_y = X[:, 1].min() - 1.0, X[:, 1].max() + 1.0 |
در خط بالا، حداقل و حداکثر مقادیر X و Y را برای استفاده در شبکه مش تعریف کردیم. علاوه بر این، ما برای طراحی شبکه مش اندازه گام را تعریف خواهیم کرد.
|
1 |
mesh_step_size = 0.02 |
اجازه دهید شبکه مش مقادیر X و Y را به شرح زیر تعریف کنیم –
|
1 2 |
x_vals, y_vals = np.meshgrid(np.arange(min_x, max_x, mesh_step_size), np.arange(min_y, max_y, mesh_step_size)) |
با کمک کد زیر می توان طبقه بندی را روی شبکه مش اجرا کرد –
|
1 2 3 4 5 6 7 |
output = classifier.predict(np.c_[x_vals.ravel(), y_vals.ravel()]) output = output.reshape(x_vals.shape) plt.figure() plt.pcolormesh(x_vals, y_vals, output, cmap = plt.cm.gray) plt.scatter(X[:, 0], X[:, 1], c = y, s = 75, edgecolors = 'black', linewidth=1, cmap = plt.cm.Paired) |
کد زیر مرزهای طرح را مشخص می کند
|
1 2 3 4 5 |
plt.xlim(x_vals.min(), x_vals.max()) plt.ylim(y_vals.min(), y_vals.max()) plt.xticks((np.arange(int(X[:, 0].min() - 1), int(X[:, 0].max() + 1), 1.0))) plt.yticks((np.arange(int(X[:, 1].min() - 1), int(X[:, 1].max() + 1), 1.0))) plt.show() |
اکنون، پس از اجرای کد، ما خروجی زیر را می گیریم ، طبقه بندی رگرسیون لجستیک:
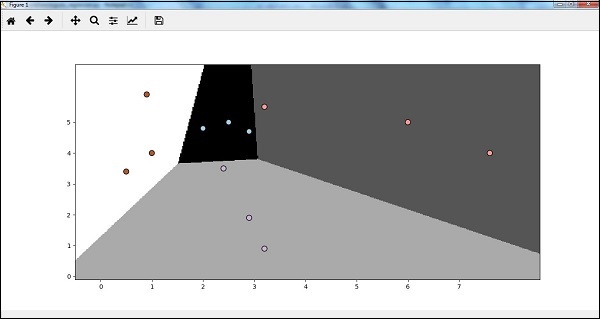
طبقه بندی درخت تصمیم
درخت تصمیم در اصل یک نمودار جریان باینری است که هر گره با توجه به برخی از متغیرهای ویژگی ، گروهی از مشاهدات را تقسیم می کند.
در اینجا، ما در حال ساخت یک طبقه بندی درخت تصمیم برای پیش بینی زن یا مرد هستیم. ما یک مجموعه داده بسیار کوچک با 19 نمونه خواهیم گرفت. این نمونه ها از دو ویژگی “قد” و “طول مو” تشکیل شده اند.
پيش نياز
برای ساخت طبقه بندی زیر ، باید pydotplus و graphviz را نصب کنیم. اساساً ، graphviz ابزاری برای ترسیم گرافیک با استفاده از فایلهای نقطه است و pydotplus ماژولی برای زبان Graphviz’s Dot است. می توان آن را با مدیر بسته یا pip نصب کرد.
اکنون، می توانیم طبقه بندی درخت تصمیم را با کمک کد Python زیر ایجاد کنیم:
برای شروع ، اجازه دهید برخی از کتابخانه های مهم را به شرح زیر وارد کنیم –
|
1 2 3 4 5 6 |
import pydotplus from sklearn import tree from sklearn.datasets import load_iris from sklearn.metrics import classification_report from sklearn import cross_validation import collections |
اکنون، ما باید مجموعه داده را به شرح زیر ارائه دهیم –
|
1 2 3 4 5 6 7 8 9 10 |
X = [[165,19],[175,32],[136,35],[174,65],[141,28],[176,15],[131,32], [166,6],[128,32],[179,10],[136,34],[186,2],[126,25],[176,28],[112,38], [169,9],[171,36],[116,25],[196,25]] Y = ['Man','Woman','Woman','Man','Woman','Man','Woman','Man','Woman', 'Man','Woman','Man','Woman','Woman','Woman','Man','Woman','Woman','Man'] data_feature_names = ['height','length of hair'] X_train, X_test, Y_train, Y_test = cross_validation.train_test_split (X, Y, test_size=0.40, random_state=5) |
پس از ارائه مجموعه داده، ما باید مدل را متناسب کنیم که می تواند به صورت زیر انجام شود –
|
1 2 |
clf = tree.DecisionTreeClassifier() clf = clf.fit(X,Y) |
پیش بینی را می توان با کمک کد پایتون زیر انجام داد –
|
1 2 |
prediction = clf.predict([[133,37]]) print(prediction) |
ما می توانیم درخت تصمیم را با کمک کد پایتون زیر تجسم کنیم:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
dot_data = tree.export_graphviz(clf,feature_names = data_feature_names, out_file = None,filled = True,rounded = True) graph = pydotplus.graph_from_dot_data(dot_data) colors = ('orange', 'yellow') edges = collections.defaultdict(list) for edge in graph.get_edge_list(): edges[edge.get_source()].append(int(edge.get_destination())) for edge in edges: edges[edge].sort() for i in range(2):dest = graph.get_node(str(edges[edge][i]))[0] dest.set_fillcolor(colors[i]) graph.write_png('Decisiontree16.png') |
این پیش بینی کد بالا را به عنوان [‘Woman’] ارائه می دهد و درخت تصمیم زیر را ایجاد می کند –
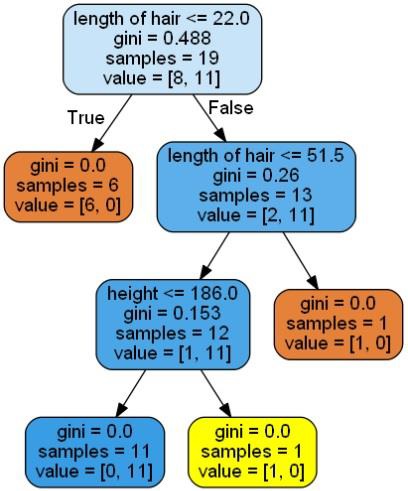
می توانیم مقادیر ویژگی ها را در پیش بینی تغییر دهیم تا آن را آزمایش کنیم.
طبقه بندی کننده جنگل تصادفی
همانطور که می دانیم روشهای گروهی روشی است که مدلهای یادگیری ماشین را به یک مدل یادگیری ماشین قدرتمندتر تبدیل می کند. Random Forest، مجموعه ای از درختان تصمیم گیرنده، یکی از آنهاست. در اینجا، ما می خواهیم مدل جنگل تصادفی را در مجموعه داده های سرطان scikit یاد بگیریم.
بسته های لازم را وارد کنید –
|
1 2 3 4 5 6 |
from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split from sklearn.datasets import load_breast_cancer cancer = load_breast_cancer() import matplotlib.pyplot as plt import numpy as np |
اکنون، ما باید مجموعه داده را ارائه دهیم که می تواند به صورت زیر و منهای انجام شود
|
1 2 3 |
cancer = load_breast_cancer() X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, random_state = 0) |
پس از ارائه مجموعه داد ، ما باید مدل را متناسب کنیم که می تواند به صورت زیر انجام شود –
|
1 2 |
forest = RandomForestClassifier(n_estimators = 50, random_state = 0) forest.fit(X_train,y_train) |
اکنون، در آموزش و همچنین زیر مجموعه تست دقت کنید: اگر تعداد برآوردگرها را افزایش دهیم، دقت زیرمجموعه آزمایش نیز افزایش می یابد.
|
1 2 |
print('Accuracy on the training subset:(:.3f)',format(forest.score(X_train,y_train))) print('Accuracy on the training subset:(:.3f)',format(forest.score(X_test,y_test))) |
خروجی
|
1 2 |
Accuracy on the training subset:(:.3f) 1.0 Accuracy on the training subset:(:.3f) 0.965034965034965 |
اکنون مانند درخت تصمیم، جنگل تصادفی دارای ماژول feature_importance است که نمای بهتری از وزن ویژگی را نسبت به درخت تصمیم ارائه می دهد. این می تواند به صورت زیر طرح و تجسم شود –
|
1 2 3 4 5 6 |
n_features = cancer.data.shape[1] plt.barh(range(n_features),forest.feature_importances_, align='center') plt.yticks(np.arange(n_features),cancer.feature_names) plt.xlabel('Feature Importance') plt.ylabel('Feature') plt.show() |
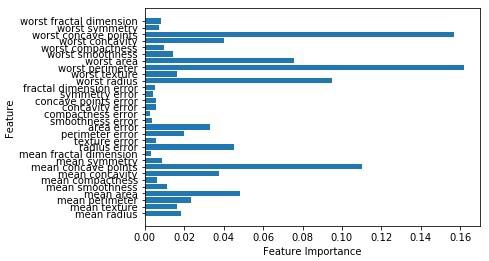
عملکرد طبقه بندی کننده
پس از پیاده سازی الگوریتم یادگیری ماشین، باید بدانیم که مدل تا چه اندازه موثر است. معیارهای اندازه گیری اثربخشی ممکن است براساس مجموعه داده ها و معیارها باشد. برای ارزیابی الگوریتم های مختلف یادگیری ماشین، می توان از معیارهای عملکرد مختلف استفاده کرد. به عنوان مثال، فرض کنید اگر از یک طبقه بندی کننده برای تشخیص تصاویر از اشیا مختلف استفاده شود ، می توانیم از معیارهای عملکرد طبقه بندی مانند دقت متوسط ، AUC و غیره استفاده کنیم. بسیار مهم است زیرا انتخاب معیارها بر چگونگی اندازه گیری و مقایسه عملکرد الگوریتم یادگیری ماشین تأثیر می گذارد. برخی از معیارهای زیر –
ماتریس درهم ریختگی
اساساً از آن برای مشکل طبقه بندی استفاده می شود که در آن خروجی می تواند از دو یا چند نوع کلاس باشد. این ساده ترین راه برای اندازه گیری عملکرد یک طبقه بندی است. ماتریس درهم ریختگی در واقع یک جدول با دو بعد “واقعی” و “پیش بینی شده” است. هر دو بعد دارای “(True Positives (TP)”, “True Negatives (TN)” ، “مثبت کاذب (FP)” ، “منفی کاذب (FN)” هستند.
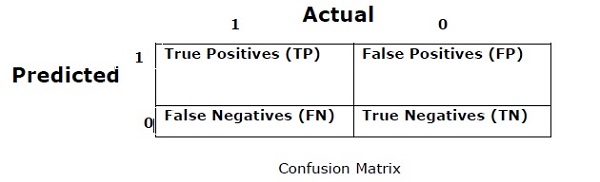
در ماتریس سردرگمی فوق، 1 برای کلاس مثبت و 0 برای کلاس منفی است.
در زیر اصطلاحات مرتبط با ماتریس سردرگمی آورده شده است:
- TP –True Positivesها مواردی هستند که کلاس واقعی نقطه داده 1 و پیش بینی شده نیز 1 است.
- TN –True Positivesها مواردی هستند که کلاس واقعی نقطه داده ها 0 و پیش بینی شده ها نیز 0 باشد.
- FP –False Positives ها مواردی هستند که کلاس واقعی نقطه داده ها 0 بوده و پیش بینی شده نیز 1 است.
- FN –False Negatives ها مواردی هستند که کلاس واقعی نقطه داده 1 بوده و پیش بینی شده نیز 0 است.
صحت
ماتریس درهم ریختگی به خودی خود یک معیار عملکرد نیست اما تقریباً تمام ماتریس های عملکرد مبتنی بر ماتریس درهم ریختگی هستند. یکی از آنها صحت است. در مشکلات طبقه بندی، ممکن است به عنوان تعداد پیش بینی های صحیح ساخته شده توسط مدل نسبت به انواع پیش بینی های انجام شده تعریف شود. فرمول محاسبه دقت به شرح زیر است –
$$Accuracy = \frac{TP+TN}{TP+FP+FN+TN}$$
دقت، درستی
این بیشتر در بازیابی اسناد استفاده می شود. ممکن است به این صورت تعریف شود که چه تعداد از مدارک برگشتی صحیح است. فرمول محاسبه دقت زیر است –
$ $ Precision = \ frac {TP} {TP + FP} $ $
حساسیت
ممکن است این تعریف شود که چگونه بسیاری از نکات مثبت مدل را برمی گرداند. در زیر فرمول محاسبه فراخوانی / حساسیت مدل وجود دارد –
$ $ Recall = \ frac {TP} {TP + FN} $ $
اختصاصی
ممکن است تعریف شود که چگونه بسیاری از منفی ها مدل را برمی گرداند. یادآوری دقیقاً مخالف است. در زیر فرمول محاسبه ویژگی مدل آورده شده است –
$ $ Specificity = \ frac {TN} {TN + FP} $ $
مشکل عدم تعادل کلاس
عدم تعادل طبقاتی سناریویی است که تعداد مشاهدات متعلق به یک کلاس به طور قابل توجهی کمتر از مشاهدات مربوط به طبقات دیگر است. به عنوان مثال، این مشکل در سناریویی برجسته است که ما باید بیماری های نادر، معاملات جعلی در بانک و غیره را شناسایی کنیم.
نمونه ای از کلاس های نامتعادل
بگذارید برای درک مفهوم طبقه نامتعادل مثالی از مجموعه داده های کشف تقلب را در نظر بگیریم –
|
1 2 3 4 |
Total observations = 5000 Fraudulent Observations = 50 Non-Fraudulent Observations = 4950 Event Rate = 1% |
راه حل
متعادل سازی کلاسها به عنوان راه حلی برای کلاسهای نامتعادل عمل می کند. هدف اصلی ایجاد تعادل بین کلاسها این است که فرکانس کلاس اقلیت را افزایش دهیم یا فرکانس کلاس اکثریت را کاهش دهیم. در زیر روش های حل مسئله کلاس های عدم تعادل وجود دارد –
نمونه گیری مجدد
نمونه گیری مجدد مجموعه ای از روش ها است که برای بازسازی مجموعه داده های نمونه – هر دو مجموعه آموزش و مجموعه تست استفاده می شود. برای بهبود دقت مدل، نمونه گیری مجدد انجام می شود. در زیر برخی از روشهای نمونه گیری مجدد آورده شده است –
زیر نمونه گیری تصادفی – هدف این روش ایجاد تعادل در توزیع کلاس با حذف تصادفی مثالهای کلاس اکثریت است. این کار تا زمانی انجام می شود که اکثریت و کلاس های اقلیت متعادل شوند.
|
1 2 3 4 |
Total observations = 5000 Fraudulent Observations = 50 Non-Fraudulent Observations = 4950 Event Rate = 1% |
در این حالت، ما 10 درصد نمونه را بدون جایگزینی از موارد غیر تقلب می گیریم و سپس آنها را با موارد تقلب ترکیب می کنیم –
مشاهدات غیر تقلبی پس از تصادفی تحت نمونه گیری = 10٪ 4950 = 495
کل مشاهدات پس از ترکیب آنها با مشاهدات جعلی = 505 = 495 = 545
از این رو، اکنون میزان رویداد برای مجموعه داده های جدید پس از زیر نمونه گیری = 9٪
مزیت اصلی این روش این است که می تواند زمان اجرا را کاهش دهد و ذخیره سازی را بهبود بخشد. اما در طرف دیگر، می تواند ضمن کاهش تعداد نمونه های داده آموزش، اطلاعات مفید را کنار بگذارد.
نمونه برداری بیش از حد تصادفی – هدف این روش ایجاد تعادل در توزیع کلاس با افزایش تعداد موارد در کلاس اقلیت با تکرار آنها است.
|
1 2 3 4 |
Total observations = 5000 Fraudulent Observations = 50 Non-Fraudulent Observations = 4950 Event Rate = 1% |
از این رو میزان رویداد برای مجموعه داده های جدید 1500/6450 = 23٪ خواهد بود.
مزیت اصلی این روش این است که اطلاعات مفید از بین نمی رود. اما از طرف دیگر، شانس بیش از حد مناسب بودن را افزایش می دهد زیرا رویدادهای کلاس اقلیت را تکرار می کند.
تکنیک های گروه
این روش اساساً برای اصلاح الگوریتم های طبقه بندی موجود برای مناسب سازی آنها برای مجموعه داده های نامتعادل استفاده می شود. در این روش چندین طبقه بندی کننده دو مرحله ای را از داده های اصلی ساخته و سپس پیش بینی های آنها را جمع می کنیم. طبقه بندی جنگل تصادفی نمونه ای از طبقه بندی بر اساس گروه است.
منبع.
لیست جلسات قبل آموزش هوش مصنوعی با برنامه نویسی پایتون
- آموزش هوش مصنوعی با برنامه نویسی پایتون – مفهوم کلی
- شروع آموزش هوش مصنوعی با برنامه نویسی پایتون
- یادگیری ماشین در هوش مصنوعی با برنامه نویسی پایتون
- هوش مصنوعی با برنامه نویسی پایتون، آماده سازی داده ها



.svg)
دیدگاه شما