
همانطور که میدانیم، یادگیری ماشین، زیرمجموعهای از هوش مصنوعی است که شامل آموزش الگوریتمهای رایانهای برای یادگیری خودکار الگوها و روابط در دادهها میشود. در ادامه برخی مبانی یادگیری ماشین با پایتون معرفی میشوند:
داده (Data)
داده نقش ستون فقرات یادگیری ماشین را ایفا میکند. اگر دادهای در دسترس نباشد، الگوریتم قادر به یادگیری نخواهد بود. این دادهها ممکن است بهصورت ساختیافته (مانند جداول و پایگاههای داده) یا بدون ساختار (مانند محتوای متنی و تصویری) وجود داشته باشند. کیفیت و کمیت دادههای مورد استفاده برای آموزش الگوریتم یادگیری ماشین، عواملی حیاتی هستند که میتوانند تأثیر زیادی بر عملکرد آن بگذارند.
ویژگی (Feature)
در یادگیری ماشین، ویژگیها متغیرها یا خصوصیات مورد استفاده برای توصیف دادههای ورودی هستند. هدف این است که مرتبطترین و مفیدترین ویژگیها انتخاب شوند تا الگوریتم بتواند پیشبینیها یا تصمیمهای دقیقی ارائه کند. انتخاب ویژگی، مرحلهای بسیار مهم در فرایند یادگیری ماشین است زیرا عملکرد الگوریتم به شدت به کیفیت و ارتباط ویژگیهای انتخابشده بستگی دارد.
مدل (Model)
مدل یادگیری ماشین، یک نمایش ریاضی از رابطه بین دادههای ورودی (ویژگیها) و خروجی (پیشبینی یا تصمیم) است. و مدل با استفاده از یک مجموعهداده آموزشی ساخته میشود و سپس با یک مجموعهداده اعتبارسنجی جداگانه ارزیابی میشود. هدف این است که مدلی ایجاد شود که بتواند بهخوبی به دادههای جدید و نادیده تعمیم یابد.
آموزش (Training)
آموزش، فرایند یاددادن به الگوریتم یادگیری ماشین برای انجام پیشبینی یا تصمیمگیری دقیق است. این کار با ارائه یک مجموعهداده بزرگ به الگوریتم و اجازه دادن به آن برای یادگیری از الگوها و روابط در داده انجام میشود. در طول آموزش، الگوریتم پارامترهای داخلی خود را تنظیم میکند تا تفاوت بین خروجی پیشبینیشده و خروجی واقعی را به حداقل برساند.
آزمون (Testing)
آزمون، فرایند ارزیابی عملکرد الگوریتم یادگیری ماشین بر روی یک مجموعهداده جداگانه است که الگوریتم قبلاً آن را ندیده است. هدف این است که مشخص شود الگوریتم تا چه حد میتواند به دادههای جدید و نادیده تعمیم یابد. اگر الگوریتم بر روی مجموعهداده آزمون عملکرد خوبی داشته باشد، مدل موفق در نظر گرفته میشود.
بیش برازش (Overfitting)
بیشبرازش زمانی اتفاق میافتد که مدل یادگیری ماشین بیش از اندازه پیچیده شود و دادههای آموزشی را بیش از حد دقیق دنبال کند. در نتیجه، هنگام کار با دادههای تازه عملکرد ضعیفی دارد، چون وابستگی شدید به دادههای تمرینی پیدا کرده است.. برای جلوگیری از بیشبرازش، باید از مجموعهداده اعتبارسنجی استفاده کنیم تا عملکرد مدل را بسنجیم. همچنین میتوانیم از روشهای منظمسازی (Regularization) بهره ببریم تا مدل سادهتر شود.
کم برازش (Underfitting)
کمبرازش زمانی اتفاق می افتد که مدل یادگیری ماشین بیش از حد ساده باشد و نتواند الگوها و رابطههای موجود در داده را شناسایی کند. این مشکل باعث میشود مدل روی دادههای آموزشی و دادههای آزمون، هر دو، عملکرد ضعیفی داشته باشد. برای جلوگیری از کمبرازش، میتوانیم اقداماتی مانند افزایش پیچیدگی مدل، گردآوری دادهٔ بیشتر، کاهش میزان منظمسازی و استفاده از مهندسی ویژگی (Feature Engineering) انجام دهیم.
تعادل میان بیش برازش و کم برازش
باید توجه داشته باشیم که جلوگیری از کمبرازش به معنای ایجاد تعادل میان پیچیدگی مدل و میزان دادهٔ موجود است. افزایش پیچیدگی مدل میتواند کمبرازش را کاهش دهد، اما اگر داده کافی برای پشتیبانی از این پیچیدگی وجود نداشته باشد، مدل دچار بیشبرازش خواهد شد. بنابراین، لازم است همواره عملکرد مدل را زیر نظر بگیریم و پیچیدگی آن را بر اساس شرایط تنظیم کنیم.
چرا و چه زمانی باید به ماشین یاد بدهیم؟
تا اینجا دربارهٔ ضرورت یادگیری ماشین صحبت کردیم. اما پرسش دیگری مطرح میشود: در چه موقعیتهایی لازم است ماشین یاد بگیرد؟ در بسیاری از شرایط، ما به تصمیمگیریهای مبتنی بر داده نیاز داریم؛ آن هم با کارایی بالا و در مقیاس بزرگ. در ادامه به چند نمونه از این شرایط اشاره میکنیم که در آنها استفاده از یادگیری ماشین مؤثرتر خواهد بود:
نبود تخصص انسانی
نخستین موقعیتی که در آن میخواهیم ماشین یاد بگیرد و تصمیمهای مبتنی بر داده بگیرد، زمانی است که در یک حوزه تخصص انسانی وجود ندارد. برای نمونه، میتوان به مسیریابی در مناطق ناشناخته یا کاوش در سیارههای فضایی اشاره کرد.
سناریوهای پویا
برخی موقعیتها ماهیتی پویا دارند و در طول زمان دائماً تغییر میکنند. در چنین شرایط و رفتارهایی، نیاز داریم ماشین بیاموزد و تصمیمهای مبتنی بر داده اتخاذ کند. بهعنوان مثال میتوان به اتصال شبکه یا دسترسی به زیرساختها در یک سازمان اشاره کرد.
دشواری در تبدیل تخصص انسانی به وظایف محاسباتی
در بسیاری از حوزهها انسانها تخصص بالایی دارند، اما قادر نیستند این تخصص را مستقیماً به وظایف محاسباتی تبدیل کنند. در چنین شرایطی به یادگیری ماشین نیاز داریم. نمونههایی از این حوزهها شامل تشخیص گفتار (Speech Recognition) و وظایف شناختی (Cognitive Tasks) هستند.
مدل یادگیری ماشین (Machine Learning Model)
پیش از آنکه وارد بحث مدل یادگیری ماشین شویم، باید تعریف رسمی ارائهشده توسط پروفسور میتچل (Mitchell) را درک کنیم:
«یک برنامه رایانهای زمانی میآموزد که با توجه به مجموعهای از وظایف (T) و معیار عملکرد (P)، توانایی آن در انجام وظایف T، بر اساس معیار P، با کسب تجربه (E) بهبود یابد.»
این تعریف در واقع بر سه پارامتر اصلی تمرکز دارد که هسته هر الگوریتم یادگیری را تشکیل میدهند: وظیفه (Task – T)، عملکرد (Performance – P) و تجربه (Experience – E).
با سادهسازی تعریف بالا میتوان گفت:
یادگیری ماشین شاخهای از هوش مصنوعی است که الگوریتمهای آن:
-
عملکرد خود را بهبود میدهند (P)،
-
در انجام یک وظیفه مشخص (T)،
-
در گذر زمان و بر اساس تجربه (E).
بر این اساس، نمودار زیر نمایی کلی از یک مدل یادگیری ماشین را نشان میدهد:
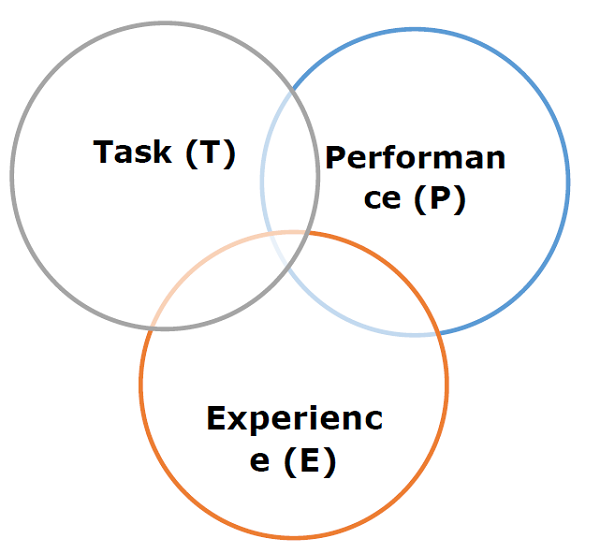
اکنون بیایید آنها را با جزئیات بیشتری بررسی کنیم:
وظیفه (Task – T)
از دیدگاه مسئله، وظیفه T همان مشکل دنیای واقعی است که باید حل شود. این مشکل میتواند تعیین بهترین قیمت خانه در یک منطقه مشخص یا یافتن بهترین استراتژی بازاریابی باشد.
با این حال، در یادگیری ماشین تعریف وظیفه متفاوت است، زیرا حل چنین وظایفی با رویکردهای سنتی برنامهنویسی بسیار دشوار است.
یک وظیفه T را زمانی میتوان «وظیفه مبتنی بر یادگیری ماشین» دانست که بر اساس فرایندی تعریف شده باشد که سیستم برای کار با نقاط داده دنبال میکند. نمونههایی از این وظایف عبارتاند از:
-
طبقهبندی (Classification)
-
رگرسیون (Regression)
-
برچسبگذاری ساختاریافته (Structured Annotation)
-
خوشهبندی (Clustering)
-
رونویسی یا تبدیل گفتار به متن (Transcription)
تجربه (Experience – E)
همانطور که از نامش پیداست، تجربه به دانشی اشاره دارد که مدل از دادههای ورودی کسب میکند. وقتی مجموعهداده در اختیار الگوریتم قرار میگیرد، مدل بهصورت تکراری اجرا میشود و الگوهای پنهان را میآموزد. این دانش بهدستآمده همان تجربه (E) است.
برای مقایسه، میتوان این روند را مشابه یادگیری انسان دانست؛ یعنی فرد از طریق شرایط، روابط و عوامل مختلف تجربه کسب میکند.
روشهای مختلف یادگیری مانند یادگیری نظارتشده (Supervised Learning)، یادگیری بدون نظارت (Unsupervised Learning) و یادگیری تقویتی (Reinforcement Learning) ابزارهایی هستند که مدل از طریق آنها تجربه میآموزد. تجربهای که الگوریتم یا مدل کسب میکند، برای حل وظیفه T بهکار میرود.
عملکرد (Performance – P)
الگوریتم یادگیری ماشین باید وظیفه را انجام دهد و در گذر زمان تجربه بیاموزد. اما معیار سنجش این است که آیا الگوریتم مطابق انتظار عمل میکند یا نه. این معیار همان عملکرد (P) است.
عملکرد در اصل یک شاخص کمی است که نشان میدهد مدل چگونه وظیفه T را با استفاده از تجربه E انجام میدهد.
برخی از معیارهای رایج برای ارزیابی عملکرد مدل عبارتاند از:
-
دقت (Accuracy Score)
-
امتیاز F1 (F1 Score)
-
ماتریس اغتشاش یا درهم ریختگی (Confusion Matrix)
-
دقت یا Precision
-
فراخوانی یا Recall
-
حساسیت (Sensitivity)
اگر بهتازگی وارد دنیای برنامه نویسی شدهاید، بهترین نقطه شروع یادگیری ماشین، زبان پایتون است. با استفاده از منابع معتبر در زمینه آموزش پایتون از صفر میتوانید پایههای کدنویسی را تقویت کرده و سپس بهصورت عملی الگوریتمهای یادگیری ماشین را پیادهسازی کنید.
راستی! برای دریافت مطالب جدید در کانال تلگرام یا پیج اینستاگرام سورس باران عضو شوید.
- انتشار: 20 آگوست 2025
دسته بندی موضوعات
- آموزش ارز دیجیتال
- آموزش برنامه نویسی
- آموزش متنی برنامه نویسی
- اطلاعیه و سایر مطالب
- پروژه برنامه نویسی
- دوره های تخصصی برنامه نویسی
- رپورتاژ
- فیلم های آموزشی
- ++C
- ADO.NET
- Adobe Flash
- Ajax
- AngularJS
- apache
- ARM
- Asp.Net
- ASP.NET MVC
- AVR
- Bootstrap
- CCNA
- CCNP
- CMD
- CSS
- Dreameaver
- EntityFramework
- HTML
- IOS
- jquery
- Linq
- Mysql
- Oracle
- PHP
- PHPMyAdmin
- Rational Rose
- silver light
- SQL Server
- Stimulsoft Reports
- Telerik
- UML
- VB.NET&VB6
- WPF
- Xml
- آموزش های پروژه محور
- اتوکد
- الگوریتم تقریبی
- امنیت
- اندروید
- اندروید استودیو
- بک ترک
- بیسیک فور اندروید
- پایتون
- جاوا
- جاوا اسکریپت
- جوملا
- دلفی
- دوره آموزش Go
- دوره های رایگان پیشنهادی
- زامارین
- سئو
- ساخت CMS
- سی شارپ
- شبکه و مجازی سازی
- طراحی الگوریتم
- طراحی بازی
- طراحی وب
- فتوشاپ
- فریم ورک codeigniter
- فلاتر
- کانستراکت
- کریستال ریپورت
- لاراول
- معماری کامپیوتر
- مهندسی اینترنت
- هوش مصنوعی
- یونیتی
- کتاب های آموزشی
- Android
- ASP.NET
- AVR
- LINQ
- php
- Workflow
- اچ تی ام ال
- بانک اطلاعاتی
- برنامه نویسی سوکت
- برنامه نویسی موبایل
- پاسکال
- پایان نامه
- پایتون
- جاوا
- جاوا اسکریپت
- جی کوئری
- داده کاوی
- دلفی
- رباتیک
- سئو
- سایر کتاب ها
- سخت افزار
- سی اس اس
- سی پلاس پلاس
- سی شارپ
- طراحی الگوریتم
- فتوشاپ
- مقاله
- مهندسی نرم افزار
- هک و امنیت
- هوش مصنوعی
- ویژوال بیسیک
- نرم افزار و ابزار برنامه نویسی
- وردپرس










