
طبقه بندی به فرایند پیشبینی یک کلاس یا دسته از روی مقادیر مشاهدهشده یا دادههای دادهشده اطلاق میشود. خروجی دستهبندیشده میتواند شکلی مانند «سیاه» یا «سفید» یا «اسپم» یا «غیراسپم» داشته باشد.
در یادگیری ماشین، طبقه بندی یک تکنیک یادگیری نظارتشده (supervised learning) است که طی آن، الگوریتم با دادههای برچسبدار آموزش میبیند تا بتواند دسته دادههای جدید را پیشبینی کند.
از نظر ریاضی، طبقه بندی وظیفه تخمین یک تابع نگاشت (f) از متغیرهای ورودی (X) به متغیرهای خروجی (Y) است. این مسئله اساساً متعلق به یادگیری نظارتشده است، زیرا هدفها (یا برچسبها) همراه با مجموعه دادههای ورودی ارائه میشوند.
مثالی از یک مسئله طبقه بندی، تشخیص اسپم در ایمیلهاست. در این حالت، تنها دو دسته خروجی وجود دارد: «اسپم» و «غیراسپم»؛ بنابراین این یک طبقه بندی دودویی (binary classification) محسوب میشود.
برای پیادهسازی این طبقه بندی، ابتدا باید مدل طبقه بندیکننده (classifier) را آموزش دهیم. در این مثال، ایمیلهای «اسپم» و «غیراسپم» بهعنوان دادههای آموزشی مورد استفاده قرار میگیرند. پس از آموزش موفق مدل، میتوان از آن برای شناسایی ایمیلهای ناشناخته استفاده کرد.
انواع یادگیرندهها در مسئله طبقه بندی
در مسائل طبقه بندی، دو نوع یادگیرنده وجود دارد:
- یادگیرندههای تنبل (Lazy Learners) – همانطور که از نام آنها پیداست، این دسته از یادگیرندهها پس از ذخیرهسازی دادههای آموزشی، منتظر دریافت دادههای آزمایشی میمانند و تنها پس از آن اقدام به طبقه بندی میکنند. آنها زمان کمتری را صرف آموزش کرده اما در پیشبینی زمان بیشتری نیاز دارند. از جمله نمونههای این نوع یادگیرندهها میتوان به الگوریتم نزدیکترین همسایه (K-nearest neighbor) و استدلال مبتنی بر مورد (case-based reasoning) اشاره کرد.
- یادگیرندههای فعال (Eager Learners) – برخلاف یادگیرندههای تنبل، این نوع یادگیرندهها پس از دریافت دادههای آموزشی، بدون انتظار برای دادههای آزمایشی، مدل طبقه بندی را میسازند. آنها زمان بیشتری را صرف آموزش میکنند اما در پیشبینی سریعتر عمل مینمایند. نمونههایی از یادگیرندههای فعال عبارتند از: درخت تصمیم (Decision Trees)، بیز ساده (Naive Bayes) و شبکههای عصبی مصنوعی (Artificial Neural Networks یا ANN).
الگوریتم های طبقه بندی در یادگیری ماشین
الگوریتم طبقه بندی نوعی تکنیک یادگیری نظارتشده (supervised learning) است که به پیشبینی یک متغیر هدف دستهای (categorical) بر اساس مجموعهای از ویژگیهای ورودی میپردازد. این الگوریتمها بهطور گسترده در حل مسائلی مانند تشخیص اسپم، شناسایی تقلب، تشخیص تصویر، تحلیل احساسات و بسیاری کاربردهای دیگر استفاده میشوند.
هدف یک مدل طبقه بندی، یادگیری یک تابع نگاشت (f) بین ویژگیهای ورودی (X) و متغیر هدف (Y) است. این تابع نگاشت معمولاً بهصورت یک مرز تصمیمگیری (decision boundary) نمایش داده میشود که کلاسهای مختلف را در فضای ویژگیها از یکدیگر جدا میکند. پس از آموزش مدل، میتوان از آن برای پیشبینی کلاس نمونههای جدید و دیدهنشده استفاده کرد.
در ادامه برخی از الگوریتم های مهم طبقه بندی در یادگیری ماشین معرفی میشوند:
-
رگرسیون لجستیک (Logistic Regression)
-
نزدیکترین همسایگان (K-Nearest Neighbors یا KNN)
-
ماشین بردار پشتیبان (Support Vector Machine یا SVM)
-
درخت تصمیم (Decision Tree)
-
بیز ساده (Naive Bayes)
-
جنگل تصادفی (Random Forest)
در فصلهای بعدی، تمامی این الگوریتم های طبقه بندی بهطور مفصل مورد بررسی قرار خواهند گرفت. با این حال، در ادامه مروری کوتاه بر آنها خواهیم داشت:
رگرسیون لجستیک (Logistic Regression)
رگرسیون لجستیک یکی از الگوریتم های پرکاربرد برای مسائل طبقه بندی دودویی (binary classification) است، جایی که متغیر هدف فقط دو کلاس دارد. این الگوریتم احتمال تعلق نمونه به هر کلاس را بر اساس ویژگیهای ورودی مدلسازی کرده و کلاسی را که بیشترین احتمال را دارد، پیشبینی میکند.
رگرسیون لجستیک نوعی مدل خطی تعمیمیافته (generalized linear model) است که در آن متغیر هدف از توزیع برنولی (Bernoulli distribution) پیروی میکند. مدل شامل یک تابع خطی از ویژگیهای ورودی است که از طریق تابع لجستیک (logistic function) تبدیل میشود تا مقدار احتمالی بین ۰ و ۱ تولید کند.
نزدیکترین همسایگان (K-Nearest Neighbors یا KNN)
الگوریتم K-نزدیکترین همسایه (K-Nearest Neighbors یا KNN) یک الگوریتم یادگیری نظارتشده است که میتواند هم در مسائل طبقه بندی و هم در مسائل رگرسیون مورد استفاده قرار گیرد. ایده اصلی در KNN این است که نزدیکترین k نقطه داده به یک نقطه آزمایشی را بیابد و از این همسایههای نزدیک برای پیشبینی استفاده کند. مقدار k یک ابرپارامتر (hyperparameter) قابل تنظیم است و تعداد همسایههایی را تعیین میکند که باید در نظر گرفته شوند.
در مسائل طبقه بندی، الگوریتم KNN، نقطه آزمایشی را به کلاسی نسبت میدهد که در میان k همسایه نزدیک، بیشترین فراوانی را دارد. به بیان دیگر، کلاسی که بیشترین تعداد همسایه را در اطراف دارد، بهعنوان کلاس پیشبینیشده انتخاب میشود.
در مسائل رگرسیون، الگوریتم KNN مقدار پیشبینیشده را بهصورت میانگین مقادیر k همسایه نزدیک اختصاص میدهد.
ماشین بردار پشتیبان (Support Vector Machine یا SVM)
ماشینهای بردار پشتیبان (Support Vector Machines یا SVM) الگوریتم هایی قدرتمند و در عین حال انعطافپذیر از نوع یادگیری نظارتشده هستند که برای طبقه بندی و همچنین رگرسیون بهکار میروند، هرچند که معمولاً در مسائل طبقه بندی استفادهی بیشتری دارند. الگوریتم SVM نخستین بار در دهه ۱۹۶۰ معرفی شد و سپس در دهه ۱۹۹۰ بهطور چشمگیری بهبود یافت.
SVMها روش پیادهسازی منحصربهفردی دارند که آنها را از سایر الگوریتم های یادگیری ماشین متمایز میسازد. در سالهای اخیر، این الگوریتمها بهدلیل توانایی بالا در مدیریت متغیرهای پیوسته و گسسته، بسیار محبوب شدهاند.
درخت تصمیم (Decision Tree)
الگوریتم درخت تصمیم یک الگوریتم سلسلهمراتبی مبتنی بر ساختار درختی است که برای طبقه بندی یا پیشبینی خروجیها بر اساس مجموعهای از قواعد بهکار میرود. این الگوریتم با تقسیم دادهها به زیرمجموعههایی بر اساس مقادیر ویژگیهای ورودی عمل میکند. فرآیند تقسیم بهصورت بازگشتی ادامه مییابد تا زمانی که هر زیرمجموعه تنها شامل نمونههایی از یک کلاس مشخص باشد یا مقادیر متغیر هدف در آن یکسان شوند.
نتیجه نهایی، درختی از قواعد تصمیمگیری است که میتوان از آن برای پیشبینی یا طبقه بندی دادههای جدید استفاده کرد.
بیز ساده (Naive Bayes)
الگوریتم بیز ساده یک الگوریتم طبقه بندی مبتنی بر قضیه بیز (Bayes’ theorem) است. این الگوریتم فرض میکند که ویژگیها از یکدیگر مستقل هستند؛ به همین دلیل آن را «ساده» (naive) مینامند. الگوریتم ناوی بیز احتمال تعلق یک نمونه به یک کلاس خاص را بر اساس احتمال ویژگیهای آن محاسبه میکند.
برای مثال، یک تلفن همراه ممکن است بهعنوان «هوشمند» در نظر گرفته شود اگر دارای صفحهنمایش لمسی، قابلیت اتصال به اینترنت، دوربین با کیفیت و ویژگیهای مشابه باشد. حتی اگر این ویژگیها در عمل به یکدیگر وابسته باشند، الگوریتم فرض میکند که هر یک از آنها بهطور مستقل در احتمال هوشمند بودن گوشی تأثیرگذار هستند.
جنگل تصادفی (Random Forest)
جنگل تصادفی یک الگوریتم یادگیری ماشین از نوع یادگیری نظارتشده است که برای پیشبینی از مجموعهای از درختهای تصمیم (decision trees) استفاده میکند. این الگوریتم نخستینبار توسط لئو بریمن (Leo Breiman) در سال ۲۰۰۱ معرفی شد.
ایده اصلی پشت این الگوریتم، ایجاد تعداد زیادی درخت تصمیم است که هر کدام بر روی زیرمجموعهای متفاوت از دادهها آموزش میبینند. در نهایت، پیشبینیهای همه درختها با یکدیگر ترکیب میشود تا نتیجه نهایی بهدست آید. این روش بهدلیل کاهش احتمال بیشبرازش (overfitting) و افزایش دقت پیشبینی، بسیار محبوب است.
کاربردهای الگوریتم های طبقه بندی در یادگیری ماشین
الگوریتم های طبقه بندی در طیف وسیعی از مسائل کاربرد دارند. برخی از مهمترین کاربردهای آنها عبارتاند از:
-
تشخیص گفتار (Speech Recognition)
-
شناسایی دستخط (Handwriting Recognition)
-
شناسایی زیستی (Biometric Identification)
-
طبقه بندی اسناد (Document Classification)
-
طبقه بندی تصاویر (Image Classification)
-
فیلتر کردن اسپم (Spam Filtering)
-
کشف تقلب (Fraud Detection)
-
تشخیص چهره (Facial Recognition)
ساخت یک مدل طبقه بندی در یادگیری ماشین
در این بخش، به مراحل اصلی ساخت یک مدل طبقه بندی در یادگیری ماشین میپردازیم:
۱. آمادهسازی دادهها (Data Preparation)
اولین گام، جمعآوری و پیشپردازش دادهها است. این مرحله شامل پاکسازی دادهها، مدیریت مقادیر گمشده، و تبدیل متغیرهای دستهای (categorical) به مقادیر عددی میباشد. کیفیت دادههای ورودی تأثیر مستقیمی بر عملکرد نهایی مدل دارد.
۲. استخراج یا انتخاب ویژگیها (Feature Extraction/Selection)
در این مرحله، ویژگیهای مرتبط و مؤثر از میان دادهها استخراج یا انتخاب میشوند. این مرحله بسیار حیاتی است، زیرا کیفیت و ارتباط ویژگیها نقش مهمی در دقت مدل ایفا میکند. برخی از تکنیکهای رایج برای انتخاب ویژگی عبارتند از:
-
تحلیل همبستگی (Correlation Analysis)
-
رتبهبندی اهمیت ویژگیها (Feature Importance Ranking)
-
تحلیل مؤلفههای اصلی (Principal Component Analysis یا PCA)
۳. انتخاب مدل (Model Selection)
پس از انتخاب ویژگیها، گام بعدی انتخاب یک الگوریتم طبقه بندی مناسب است. الگوریتم های متعددی برای این منظور وجود دارند که هر کدام مزایا و محدودیتهای خاص خود را دارند. از جمله الگوریتم های پرکاربرد میتوان به موارد زیر اشاره کرد:
-
رگرسیون لجستیک (Logistic Regression)
-
درخت تصمیم (Decision Tree)
-
جنگل تصادفی (Random Forest)
-
ماشین بردار پشتیبان (Support Vector Machine یا SVM)
-
شبکههای عصبی (Neural Networks)
۴. آموزش مدل (Model Training)
پس از انتخاب الگوریتم مناسب، مدل بر روی دادههای آموزشی برچسبدار (labeled training data) آموزش داده میشود. در این مرحله، مدل تابع نگاشت بین ویژگیهای ورودی و متغیر هدف را یاد میگیرد. پارامترهای مدل بهصورت تکراری (iteratively) تنظیم میشوند تا اختلاف بین خروجیهای پیشبینیشده و خروجیهای واقعی به حداقل برسد.
۵. ارزیابی مدل (Model Evaluation)
پس از آموزش مدل، گام بعدی ارزیابی عملکرد آن بر روی مجموعهی داده اعتبارسنجی (validation data) است. این مرحله به منظور برآورد دقت و توانایی تعمیم مدل به دادههای جدید انجام میشود. برخی از معیارهای متداول برای ارزیابی مدل عبارتاند از:
-
دقت (Accuracy)
-
دقت مثبتها (Precision)
-
بازخوانی (Recall)
-
امتیاز F1 (F1-Score)
-
مساحت زیر منحنی ROC (Area Under the ROC Curve)
۶. تنظیم ابرپارامترها (Hyperparameter Tuning)
در بسیاری از موارد، عملکرد مدل را میتوان با تنظیم ابرپارامترها بهبود بخشید. ابرپارامترها تنظیماتی هستند که پیش از آموزش مدل انتخاب میشوند و بر جنبههایی مانند نرخ یادگیری (learning rate)، شدت منظمسازی (regularization strength) و تعداد لایههای پنهان در یک شبکه عصبی تأثیر دارند.
برخی از تکنیکهای متداول برای تنظیم ابرپارامترها شامل موارد زیر هستند:
-
جستجوی شبکهای (Grid Search)
-
جستجوی تصادفی (Random Search)
-
بهینهسازی بیزی (Bayesian Optimization)
۷. استقرار مدل (Model Deployment)
پس از آموزش و ارزیابی موفق مدل، آخرین مرحله، استقرار آن در محیط عملیاتی است. این فرآیند شامل ادغام مدل با سیستمهای بزرگتر، آزمایش آن با دادههای دنیای واقعی و پایش مداوم عملکرد مدل در طول زمان میباشد.
ساخت یک مدل طبقه بندی با پایتون
کتابخانه Scikit-learn یکی از کتابخانههای قدرتمند پایتون در حوزه یادگیری ماشین است که میتوان از آن برای ساخت مدلهای طبقه بندی استفاده کرد. مراحل ساخت یک طبقه بندی کننده در پایتون بهصورت زیر است:
گام اول: وارد کردن بستههای مورد نیاز پایتون
برای ساخت یک طبقه بندی کننده با استفاده از Scikit-learn، ابتدا باید این کتابخانه را وارد کنیم. این کار با دستور زیر انجام میشود:
|
1 |
import sklearn |
گام دوم: وارد کردن مجموعهداده
پس از وارد کردن بستههای مورد نیاز، به یک مجموعهداده برای ساخت مدل پیشبینی نیاز داریم. میتوان از مجموعهدادههای موجود در Scikit-learn استفاده کرد یا مجموعه داده دیگری را با توجه به نیاز خود وارد نمود.
در این مثال، از پایگاه داده تشخیصی سرطان پستان ویسکانسین (Breast Cancer Wisconsin Diagnostic Database) استفاده میکنیم. با استفاده از دستور زیر آن را بارگذاری میکنیم:
|
1 |
from sklearn.datasets import load_breast_cancer |
|
1 |
data = load_breast_cancer() |
|
1 2 3 4 |
label_names = data['target_names'] labels = data['target'] feature_names = data['feature_names'] features = data['data'] |
|
1 |
print(label_names) |
|
1 |
['malignant' 'benign'] |
در این مجموعهداده، برچسبها بهصورت مقادیر دودویی کدگذاری شدهاند:
-
«بدخیم» (malignant): مقدار ۰
-
«خوشخیم» (benign): مقدار ۱
برای مشاهده نام ویژگیهای مربوط به این دادهها میتوان از دستورات زیر استفاده کرد:
|
1 |
print(feature_names[0]) |
|
1 |
mean radius |
|
1 |
print(feature_names[1]) |
|
1 |
mean texture |
|
1 |
print(features[0]) |
و برای نمایش مقادیر نمونه دوم از دستور زیر استفاده کنیم:
|
1 |
print(features[1]) |
|
1 2 3 4 5 |
[2.057e+01 1.777e+01 1.329e+02 1.326e+03 8.474e-02 7.864e-02 8.690e-02 7.017e-02 1.812e-01 5.667e-02 5.435e-01 7.339e-01 3.398e+00 7.408e+01 5.225e-03 1.308e-02 1.860e-02 1.340e-02 1.389e-02 3.532e-03 2.499e+01 2.341e+01 1.588e+02 1.956e+03 1.238e-01 1.866e-01 2.416e-01 1.860e-01 2.750e-01 8.902e-02] |
گام سوم: تقسیمبندی دادهها به مجموعههای آموزش و آزمون
جهت ارزیابی مدل روی دادههای دیدهنشده، لازم است مجموعهداده را به دو بخش تقسیم کنیم: مجموعه آموزش (training set) و مجموعه آزمون (test set). برای این منظور میتوان از تابع train_test_split() در کتابخانه Scikit-learn استفاده کرد.
برای وارد کردن این تابع، از دستور زیر استفاده میکنیم:
|
1 |
from sklearn.model_selection import train_test_split |
|
1 2 |
train, test, train_labels, test_labels = train_test_split(features,labels,test_size = 0.40, random_state = 42) |
گام چهارم: ارزیابی مدل
پس از تقسیمبندی دادهها، نوبت به ساخت مدل میرسد. در این مثال، از الگوریتم بیز ساده (Naive Bayes) استفاده میکنیم. برای این کار، ابتدا باید ماژول GaussianNB را وارد کنیم:
|
1 |
from sklearn.naive_bayes import GaussianNB |
|
1 |
gnb = GaussianNB() |
|
1 |
model = gnb.fit(train, train_labels) |
predict() انجام میشود:|
1 2 |
preds = gnb.predict(test) print(preds) |
|
1 2 3 4 5 6 7 |
[1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1 0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 0 0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 0 1 1 1 1 1 1 0 1 1 0 0 0 0 0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0 1 1 0 1 1 0 0 0 1 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 1 1 0 1 1 0 0 1 0 1 1 0 1 0 0 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1 0 0 0 1 1 0 1 0 1 1 1 1 0 1 1 0 1 1 1 0 1 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 1 0 0 1 1 0 1] |
خروجی بالا شامل مجموعهای از ۰ و ۱ است که مقادیر پیشبینیشده مدل برای برچسبهای تومور بدخیم (malignant) و خوشخیم (benign) میباشد:
-
۰ → تومور بدخیم (Malignant)
-
۱ → تومور خوشخیم (Benign)
گام پنجم: محاسبه دقت مدل (Finding Accuracy)
برای محاسبه دقت مدل ساختهشده در مرحله قبل، کافی است دو آرایه test_labels (برچسبهای واقعی) و preds (برچسبهای پیشبینیشده توسط مدل) را با یکدیگر مقایسه کنیم.
برای انجام این کار، از تابع accuracy_score() موجود در ماژول sklearn.metrics استفاده میکنیم:
|
1 2 |
from sklearn.metrics import accuracy_score print(accuracy_score(test_labels,preds)) |
|
1 |
0.951754385965 |
معیارهای ارزیابی مدل طبقه بندی
اجرای موفق یک مدل یا برنامه یادگیری ماشین پایان کار نیست. ما باید ارزیابی کنیم که مدل تا چه اندازه مؤثر و دقیق عمل میکند؟
معیارهای مختلفی برای ارزیابی عملکرد مدل وجود دارند، اما انتخاب صحیح معیار اهمیت زیادی دارد؛ زیرا نوع معیاری که انتخاب میشود، تأثیر مستقیمی بر نحوه اندازهگیری و مقایسه عملکرد الگوریتم یادگیری ماشین خواهد داشت.
در ادامه، چند مورد از مهمترین معیارهای ارزیابی برای مدلهای طبقه بندی آورده شده است. بسته به نوع داده و مسئله، میتوان معیار مناسب را انتخاب کرد:
ماتریس درهمریختگی (Confusion Matrix)
ماتریس درهمریختگی سادهترین و درعینحال کاربردیترین روش برای ارزیابی عملکرد یک مدل طبقه بندی است، بهویژه زمانی که خروجی شامل دو یا چند کلاس باشد.
این ماتریس در واقع یک جدول دوبعدی است که شامل دو محور اصلی است:
-
مقدار واقعی (Actual)
-
مقدار پیشبینیشده (Predicted)
هر یک از این محورها شامل چهار مقدار کلیدی هستند:
| پیشبینی: مثبت | پیشبینی: منفی | |
|---|---|---|
| واقعی: مثبت | TP (مثبتِ درست) | FN (منفیِ نادرست) |
| واقعی: منفی | FP (مثبتِ نادرست) | TN (منفیِ درست) |
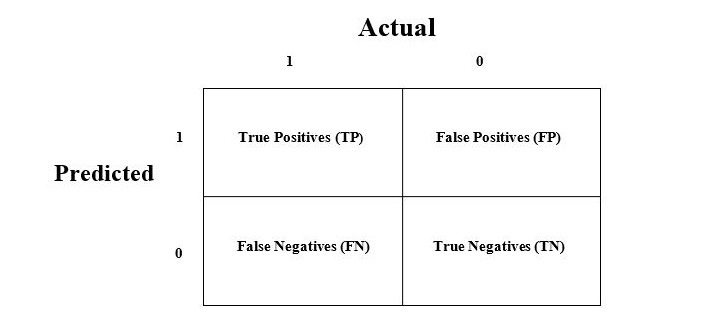
توضیح اصطلاحات مرتبط با ماتریس درهمریختگی به شرح زیر است:
-
True Positives (TP): زمانیکه کلاس واقعی و پیشبینیشده هر دو «۱» باشند.
-
True Negatives (TN): زمانیکه کلاس واقعی و پیشبینیشده هر دو «۰» باشند.
-
False Positives (FP): زمانیکه کلاس واقعی «۰» ولی مدل بهاشتباه «۱» پیشبینی کرده است.
-
False Negatives (FN): زمانیکه کلاس واقعی «۱» ولی مدل بهاشتباه «۰» پیشبینی کرده است.
برای محاسبه ماتریس درهمریختگی در Scikit-learn، میتوان از تابع confusion_matrix() استفاده کرد. در مدل دودویی ساختهشده قبلی، میتوان از اسکریپت زیر استفاده کرد:
|
1 2 3 4 |
from sklearn.metrics import confusion_matrix preds = gnb.predict(test) cm = confusion_matrix(test, preds) print(cm) |
خروجی:
|
1 2 3 4 |
[ [ 73 7] [ 4 144] ] |
دقت (Accuracy)
دقت به تعداد پیشبینیهای درست انجامشده توسط مدل یادگیری ماشین گفته میشود. این معیار نشان میدهد که چند درصد از کل پیشبینیها صحیح بودهاند.
دقت را میتوان بهراحتی با استفاده از ماتریس درهمریختگی و از طریق فرمول زیر محاسبه کرد:
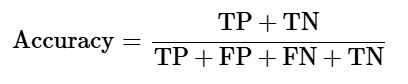
برای طبقهبند دودویی ساختهشده در مثال قبلی:
-
TP + TN = 73 (بدخیم پیشبینیشده درست) + 144 (خوشخیم پیشبینیشده درست) = 217
-
TP + FP + FN + TN = 73 + 7 + 4 + 144 = 228
بنابراین:
دقت = 217/228 = 0.951754385965
این نتیجه نشان میدهد که مدل Naive Bayes ساختهشده، دارای دقتی معادل ۹۵٫۱۷٪ است، که با دقت محاسبهشده در مرحله اجرای مدل مطابقت کامل دارد.
دقت مثبت ها (Precision)
Precision که در بازیابی اطلاعات (مانند بازیابی اسناد مرتبط) کاربرد فراوان دارد، به تعداد پیشبینیهای مثبتِ درستی که مدل انجام داده است اشاره دارد. این معیار نشان میدهد از میان تمام مواردی که مدل بهعنوان مثبت پیشبینی کرده، چه تعداد واقعاً مثبت بودهاند.
فرمول محاسبه دقت مثبتها از طریق ماتریس درهمریختگی به شکل زیر است:
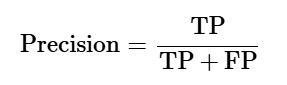
برای مدل دودویی ساختهشده:
-
TP = 73 (تعداد نمونههای مثبتِ درست پیشبینیشده)
-
TP + FP = 73 + 7 = 80 (تمام پیشبینیهای مثبت، شامل درست و نادرست)
بنابراین:
دقت مثبت ها = 73/80 = 0.915
یعنی دقت مثبت ها برابر با ۹۱٫۵٪ است، که نشاندهنده توان بالای مدل در انجام پیشبینیهای مثبت صحیح میباشد.
بازخوانی یا حساسیت (Recall / Sensitivity)
بازخوانی (Recall) یا حساسیت (Sensitivity) به تعداد نمونههای مثبتی اشاره دارد که مدل یادگیری ماشین بهدرستی آنها را شناسایی کرده است. این معیار نشان میدهد مدل از میان تمام مواردی که واقعاً مثبت بودهاند، چه تعداد را بهدرستی بهعنوان مثبت تشخیص داده است.
فرمول محاسبه بازخوانی از طریق ماتریس درهمریختگی به شکل زیر است:
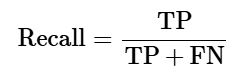
برای classifier دودویی ساختهشده:
-
TP = 73 (تعداد نمونههای مثبتِ درست شناساییشده)
-
TP + FN = 73 + 4 = 77 (تمام نمونههای واقعاً مثبت، شامل درست و نادرست)
بنابراین:
بازخوانی = 73/77 = 0.94805
یعنی مقدار بازخوانی یا حساسیت حدود ۹۴٫۸٪ است، که بیانگر توان بالای مدل در تشخیص درست نمونههای مثبت (مانند تومور بدخیم) میباشد.
ویژگی مندی (Specificity)
ویژگیمندی یا Specificity برخلاف بازخوانی (Recall)، بر روی شناسایی درست نمونههای منفی تمرکز دارد. این معیار نشان میدهد که مدل یادگیری ماشین از میان تمام نمونههایی که واقعاً منفی بودهاند، چه تعداد را بهدرستی بهعنوان منفی تشخیص داده است.
فرمول محاسبه Specificity از روی ماتریس درهمریختگی به شکل زیر است:
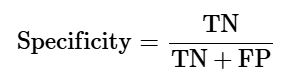
برای classifier دودویی ساختهشده:
-
TN = 144 (تعداد نمونههای منفی که بهدرستی منفی پیشبینی شدهاند)
-
TN + FP = 144 + 7 = 151 (تمام نمونههایی که مدل بهعنوان منفی در نظر گرفته، شامل درست و نادرست)
بنابراین:
ویژگی مندی = 144/151 = 0.95364
یعنی ویژگیمندی مدل حدود ۹۵٫۳۶٪ است، که نشاندهنده توان بالای مدل در شناسایی نمونههای منفی (مانند تومور خوشخیم) میباشد.
در فصلهای بعدی، بهصورت گامبهگام و دقیق به بررسی برخی از الگوریتم های طبقه بندی پرکاربرد در یادگیری ماشین خواهیم پرداخت و با نحوه عملکرد و موارد استفاده هر یک آشنا خواهیم شد. برای اجرای عملی این الگوریتمها، گذراندن دوره آموزش پایتون و کتابخانههای آن میتواند مسیر یادگیری شما را بسیار سادهتر کند.
راستی! برای دریافت مطالب جدید در کانال تلگرام یا پیج اینستاگرام سورس باران عضو شوید.
- انتشار: 21 آگوست 2025
دسته بندی موضوعات
- آموزش ارز دیجیتال
- آموزش برنامه نویسی
- آموزش متنی برنامه نویسی
- اطلاعیه و سایر مطالب
- پروژه برنامه نویسی
- دوره های تخصصی برنامه نویسی
- رپورتاژ
- فیلم های آموزشی
- ++C
- ADO.NET
- Adobe Flash
- Ajax
- AngularJS
- apache
- ARM
- Asp.Net
- ASP.NET MVC
- AVR
- Bootstrap
- CCNA
- CCNP
- CMD
- CSS
- Dreameaver
- EntityFramework
- HTML
- IOS
- jquery
- Linq
- Mysql
- Oracle
- PHP
- PHPMyAdmin
- Rational Rose
- silver light
- SQL Server
- Stimulsoft Reports
- Telerik
- UML
- VB.NET&VB6
- WPF
- Xml
- آموزش های پروژه محور
- اتوکد
- الگوریتم تقریبی
- امنیت
- اندروید
- اندروید استودیو
- بک ترک
- بیسیک فور اندروید
- پایتون
- جاوا
- جاوا اسکریپت
- جوملا
- دلفی
- دوره آموزش Go
- دوره های رایگان پیشنهادی
- زامارین
- سئو
- ساخت CMS
- سی شارپ
- شبکه و مجازی سازی
- طراحی الگوریتم
- طراحی بازی
- طراحی وب
- فتوشاپ
- فریم ورک codeigniter
- فلاتر
- کانستراکت
- کریستال ریپورت
- لاراول
- معماری کامپیوتر
- مهندسی اینترنت
- هوش مصنوعی
- یونیتی
- کتاب های آموزشی
- Android
- ASP.NET
- AVR
- LINQ
- php
- Workflow
- اچ تی ام ال
- بانک اطلاعاتی
- برنامه نویسی سوکت
- برنامه نویسی موبایل
- پاسکال
- پایان نامه
- پایتون
- جاوا
- جاوا اسکریپت
- جی کوئری
- داده کاوی
- دلفی
- رباتیک
- سئو
- سایر کتاب ها
- سخت افزار
- سی اس اس
- سی پلاس پلاس
- سی شارپ
- طراحی الگوریتم
- فتوشاپ
- مقاله
- مهندسی نرم افزار
- هک و امنیت
- هوش مصنوعی
- ویژوال بیسیک
- نرم افزار و ابزار برنامه نویسی
- وردپرس










