
پایتون بهدلیل سادگی، انعطافپذیری و اکوسیستم گستردهی کتابخانهها و ابزارها، به یکی از محبوبترین زبانهای برنامهنویسی در حوزه یادگیری ماشین تبدیل شده است. زبان های برنامه نویسی متعددی مانند Java، C++، Lisp، Julia و Python وجود دارند که میتوان از آنها در یادگیری ماشین استفاده کرد. در میان این زبانها، پایتون محبوبیت فراوانی کسب کرده است.
در اینجا به بررسی اکوسیستم پایتون در زمینه یادگیری ماشین میپردازیم و برخی از پرکاربردترین کتابخانهها و چارچوبهای (framework) آن را معرفی میکنیم.
اکوسیستم یادگیری ماشین با پایتون
اکوسیستم یادگیری ماشین به مجموعهای از ابزارها و فناوریهایی گفته میشود که برای توسعه برنامههای یادگیری ماشین مورد استفاده قرار میگیرند. پایتون مجموعهای از کتابخانهها و ابزارهای متنوع را فراهم میکند که اجزای این اکوسیستم را تشکیل میدهند. این اجزای کاربردی، پایتون را به زبانی مهم برای یادگیری ماشین و علم داده تبدیل کردهاند. هرچند ابزارها و کتابخانههای متعددی در این زمینه وجود دارند، اما در اینجا به برخی از اجزای کلیدی اکوسیستم پایتون اشاره میکنیم:
-
زبان برنامهنویسی: پایتون
-
محیط توسعهی یکپارچه (IDE)
-
کتابخانههای پایتون
زبان برنامهنویسی: پایتون
زبان های برنامه نویسی، بخش مهمی از هر اکوسیستم توسعه به شمار میروند. پایتون بهصورت گسترده در یادگیری ماشین و علم داده استفاده میشود.
حال به این پرسش میپردازیم که چرا پایتون بهترین انتخاب برای یادگیری ماشین است.
چرا پایتون برای یادگیری ماشین؟
بر اساس نظرسنجی توسعهدهندگان Stack Overflow در سال ۲۰۲۳، پایتون سومین زبان محبوب برنامه نویسی و همچنین محبوبترین زبان برای یادگیری ماشین و علم داده است. ویژگیهای زیر باعث شدهاند پایتون به زبان منتخب متخصصان این حوزه تبدیل شود:
مجموعه گستردهای از بسته ها (Packages)
پایتون دارای مجموعهای گسترده و قدرتمند از بستههایی است که آمادهی استفاده در حوزههای مختلف هستند. همچنین بستههایی مانند numpy، scipy، pandas و scikit-learn را در اختیار دارد که برای یادگیری ماشین و علم داده ضروری هستند.
نمونهسازی سریع و آسان
یکی دیگر از ویژگیهای مهم پایتون که آن را به زبان منتخب در حوزه علم داده تبدیل کرده است، توانایی در نمونهسازی (prototyping) سریع و آسان است. این قابلیت برای توسعه الگوریتمهای جدید بسیار مفید است.
قابلیت همکاری
حوزه علم داده اساساً به همکاری مؤثر میان افراد نیاز دارد و پایتون ابزارهای مفید بسیاری را برای تسهیل این همکاری فراهم میکند.
یک زبان برای حوزههای مختلف
یک پروژه معمول در علم داده شامل مراحلی همچون استخراج، پردازش و تحلیل داده، بههمراه استخراج ویژگی، مدلسازی، ارزیابی، پیادهسازی و بهروزرسانی راهحل است. به همین دلیل پایتون بهعنوان زبانی چندمنظوره، این امکان را به متخصصان علم داده میدهد که همه این مراحل را در یک بستر مشترک اجرا کنند.
نقاط قوت و ضعف پایتون
همانند هر زبان برنامهنویسی دیگر، پایتون نیز دارای نقاط قوت و ضعف خاص خود است.
نقاط قوت
بر اساس مطالعات و نظرسنجیها، پایتون پنجمین زبان برنامهنویسی مهم و همچنین محبوبترین زبان برای یادگیری ماشین و علم داده بهشمار میرود. این محبوبیت بهدلیل نقاط قوت زیر است:
-
یادگیری و درک آسان – نحو (syntax) پایتون ساده است؛ بنابراین یادگیری و درک آن حتی برای مبتدیان نیز نسبتاً آسان است.
-
زبان چندمنظوره – پایتون یک زبان برنامه نویسی چندمنظوره محسوب میشود، زیرا از برنامه نویسی ساختیافته (structured)، شیءگرا (object-oriented) و تابعمحور (functional) پشتیبانی میکند.
-
تعداد زیاد ماژولها – پایتون دارای تعداد زیادی ماژول برای پوشش جنبههای مختلف برنامه نویسی است. این ماژولها بهراحتی در دسترس هستند و همین موضوع، پایتون را به زبانی توسعهپذیر تبدیل کرده است.
-
پشتیبانی جامعه متنباز – بهعنوان یک زبان متنباز (open source)، پایتون از سوی جامعه بزرگی از توسعهدهندگان پشتیبانی میشود. در نتیجه، باگها (اشکالات) بهسرعت توسط این جامعه شناسایی و رفع میشوند. این ویژگی، پایتون را به زبانی قدرتمند و سازگار تبدیل کرده است.
-
قابلیت مقیاسپذیری – پایتون زبانی مقیاسپذیر (scalable) است، زیرا ساختار بهتری نسبت به اسکریپتهای پوسته (shell scripts) برای پشتیبانی از برنامههای بزرگ فراهم میکند.
نقطه ضعف
با وجود اینکه پایتون یک زبان برنامهنویسی قدرتمند و محبوب است، دارای نقطهضعفی در زمینه سرعت اجرای پایین میباشد.
سرعت اجرای برنامهها در پایتون نسبت به زبانهای کامپایلشده کمتر است، زیرا پایتون یک زبان تفسیرشونده (interpreted) است. این موضوع میتواند یکی از حوزههای مهم برای بهبود در جامعه توسعهدهندگان پایتون باشد.
نصب پایتون
برای کار با پایتون، ابتدا باید آن را نصب کنیم. نصب پایتون را میتوان از یکی از دو روش زیر انجام داد:
-
نصب پایتون بهصورت مستقل
-
استفاده از توزیعهای آماده پایتون – مانند Anaconda
در ادامه، هر یک از این روشها را بهصورت جداگانه بررسی میکنیم.
نصب پایتون بهصورت مستقل
اگر قصد دارید پایتون را بهطور مستقیم روی سیستم خود نصب کنید، کافی است نسخه باینری (binary) متناسب با پلتفرم خود را دانلود و نصب نمایید. توزیع پایتون برای سیستمعاملهای ویندوز، لینوکس و مکاواس در دسترس است.
در ادامه، مروری سریع بر مراحل نصب پایتون روی سیستمهای یونیکس و لینوکس ارائه شده است:
نصب پایتون در سیستمهای Unix و Linux
برای نصب پایتون در سیستمهای Unix/Linux، مراحل زیر را دنبال کنید:
-
ابتدا به نشانی: www.python.org/downloads/ مراجعه کنید.
-
سپس روی لینک دانلود کد منبع فشردهشده (zipped source code) ویژه سیستمهای Unix/Linux کلیک کنید.
-
فایلهای مربوطه را دانلود و از حالت فشرده خارج کنید.
-
در صورت نیاز به سفارشیسازی، میتوانید فایل
Modules/Setupرا ویرایش کنید. -
سپس این دستور را برای پیکربندی اجرا کنید: ./configure
- دستور کامپایل را اجرا کنید: make
- در نهایت، برای نصب پایتون این دستور را وارد کنید: make install
نصب پایتون در ویندوز (Windows)
برای نصب پایتون در سیستمعامل ویندوز، مراحل زیر را دنبال کنید:
-
ابتدا به وبسایت رسمی پایتون به نشانی www.python.org/downloads/ مراجعه کنید.
-
سپس روی لینک دانلود فایل نصب ویندوز با نام
python-XYZ.msiکلیک کنید. در اینجا منظور از XYZ نسخهای است که قصد نصب آن را دارید. -
پس از دانلود فایل، آن را اجرا کنید. این کار شما را به راهنمای نصب پایتون (Python Install Wizard) هدایت میکند که استفاده از آن بسیار ساده است.
-
تنظیمات پیشفرض را بپذیرید و منتظر بمانید تا فرآیند نصب به پایان برسد.
نصب پایتون در مک (Macintosh)
برای سیستمعامل Mac OS X، استفاده از Homebrew (یک ابزار قدرتمند و ساده برای نصب بستهها) برای نصب پایتون ۳ توصیه میشود.
در صورتی که Homebrew روی سیستم شما نصب نشده باشد، میتوانید آن را با استفاده از دستور زیر نصب کنید:
|
1 2 |
$ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" |
|
1 |
$ brew update |
|
1 |
$ brew install python3 |
استفاده از توزیع آماده پایتون: Anaconda
Anaconda یک توزیع بستهبندیشده از زبان پایتون است که شامل تمام کتابخانههای پرکاربرد در علم داده میباشد. برای راهاندازی محیط پایتون با استفاده از Anaconda، میتوانید مراحل زیر را دنبال کنید:
مرحله ۱ – ابتدا باید بستهی نصب موردنیاز را از توزیع Anaconda دانلود کنید. لینک مربوطه: www.anaconda.com/distribution/
با توجه به سیستمعامل خود (ویندوز، مک یا لینوکس) نسخه مناسب را انتخاب کنید.
مرحله ۲ – در مرحله بعد، نسخه پایتونی را که میخواهید نصب کنید، انتخاب نمایید. آخرین نسخه پیشنهادی Python، نسخه ۳.۷ است. در این بخش، گزینههای نصب گرافیکی ۶۴ بیتی و ۳۲ بیتی در دسترس خواهند بود.
مرحله ۳ – پس از انتخاب سیستمعامل و نسخه پایتون، فایل نصبکننده Anaconda روی سیستم شما دانلود خواهد شد. اکنون روی فایل دوبار کلیک کنید تا فرآیند نصب بسته Anaconda آغاز شود.
مرحله ۴ – برای اطمینان از نصب صحیح، یک پنجره خط فرمان (Command Prompt) باز کرده و دستور python را وارد کنید. اگر پایتون به درستی نصب شده باشد، وارد محیط تعاملی پایتون خواهید شد.
محیط توسعه یکپارچه (IDE)
محیط توسعه یکپارچه یا IDE (Integrated Development Environment) ابزاری نرمافزاری است که مجموعهای از ابزارهای استاندارد توسعه را در یک رابط گرافیکی کاربرپسند (GUI) گرد هم میآورد. در توسعه مرتبط با یادگیری ماشین و علم داده، محیطهای توسعه متعددی پرکاربرد هستند. برخی از IDEهای محبوب عبارتاند از:
-
Jupyter Notebook
-
PyCharm
-
Visual Studio Code
-
Spyder
-
Sublime Text
-
Atom
-
Thonny
-
Google Colab Notebook
در اینجا، به بررسی دقیقتر محیط Jupyter Notebook میپردازیم. برای اطلاعات بیشتر درباره هرکدام از IDEها از جمله نحوهی دانلود، نصب و استفاده، میتوانید به وبسایت رسمی آنها مراجعه کنید.
Jupyter Notebook
Jupyter Notebook محیطی تعاملی برای محاسبات و توسعه برنامههای مبتنی بر پایتون در حوزه علم داده فراهم میکند. این ابزار پیشتر با نام ipython notebook شناخته میشد. ویژگیهای زیر باعث شدهاند Jupyter Notebook به یکی از مولفههای کلیدی در اکوسیستم یادگیری ماشین پایتون تبدیل شود:
-
Jupyter Notebook امکان ارائه فرایند تحلیل را بهصورت گامبهگام فراهم میکند؛ بهگونهای که میتوان کد، تصاویر، متن، خروجی و سایر محتواها را به ترتیبی منظم در کنار هم قرار داد.
-
این ابزار به متخصص علم داده کمک میکند تا همزمان با توسعه فرایند تحلیل، مسیر فکری و منطق پشت تحلیلها را نیز مستند کند.
-
امکان ذخیره و نمایش نتایج بهعنوان بخشی از دفترچه یادداشت وجود دارد.
-
با استفاده از Jupyter Notebook، میتوان بهراحتی پروژه را با دیگر همکاران بهاشتراک گذاشت.
نصب و اجرا
اگر از توزیع Anaconda استفاده میکنید، نیازی به نصب جداگانه Jupyter Notebook ندارید، چرا که بهصورت پیشفرض همراه با Anaconda نصب میشود. برای اجرای آن کافی است مراحل زیر را دنبال کنید:
-
وارد محیط Anaconda Prompt شوید.
-
دستور زیر را تایپ کرده و کلید Enter را فشار دهید:
|
1 |
C:\>jupyter notebook |
localhost:8888 راهاندازی میشود. تصویر مربوط به آن در ادامه قابل مشاهده است:
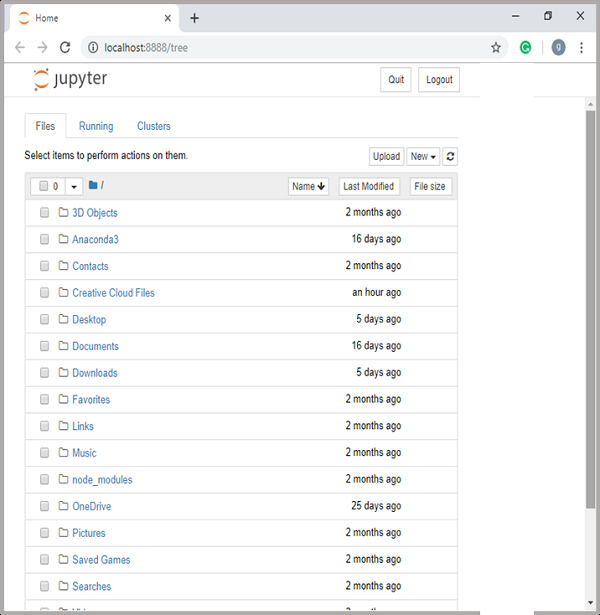
پس از باز شدن رابط کاربری Jupyter در مرورگر، با کلیک بر روی تب New، فهرستی از گزینهها نمایش داده میشود. گزینهی Python 3 را انتخاب نمایید. این کار شما را به یک دفترچه یادداشت جدید هدایت میکند تا بتوانید کار خود را آغاز کنید. نمایی از این محیط در تصاویر بعدی قابل مشاهده است:
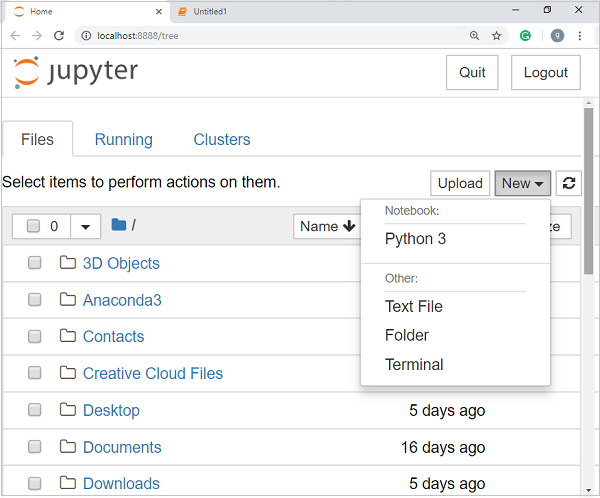
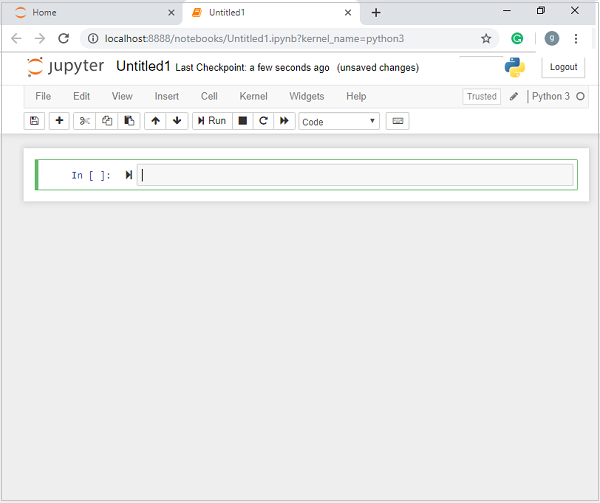
در صورتی که از توزیع استاندارد پایتون استفاده میکنید (نه Anaconda)، میتوانید Jupyter Notebook را با استفاده از مدیر بسته pip نصب کنید. دستور نصب بهصورت زیر است:
|
1 |
pip install jupyter |
انواع سلولها در Jupyter Notebook
در محیط Jupyter Notebook، سه نوع سلول اصلی وجود دارد:
-
سلولهای کد (Code cells) – همانطور که از نام آنها پیداست، از این سلولها برای نوشتن کد استفاده میشود. پس از نوشتن کد، محتوا به کرنل (kernel) مرتبط با دفترچه ارسال میشود تا اجرا شود.
-
سلولهای مارکداون (Markdown cells) – این سلولها برای توضیح و مستندسازی فرآیند محاسبه بهکار میروند. محتوای آنها میتواند شامل متن، تصویر، معادلات LaTeX، تگهای HTML و … باشد.
-
سلولهای خام (Raw cells) – محتوای نوشتهشده در این سلولها بدون تغییر و تبدیل نمایش داده میشود. این نوع سلولها معمولاً برای نوشتن متنی استفاده میشوند که نباید توسط سیستم Jupyter تبدیل شود.
کتابخانهها و بستههای پایتون
اکوسیستم پایتون مجموعه بزرگی از کتابخانهها و بستهها را در اختیار دارد که به توسعهدهندگان کمک میکند مدلهای یادگیری ماشین را بهسادگی و با سرعت بیشتری ایجاد کنند. در این بخش به برخی از مهمترین آنها اشاره میکنیم:
NumPy
NumPy یک کتابخانه بنیادی برای محاسبات علمی در پایتون است. این کتابخانه از آرایهها و ماتریسهای بزرگ و چندبعدی پشتیبانی میکند و مجموعهای از توابع ریاضی برای انجام عملیات روی آنها ارائه میدهد.
NumPy یکی از اجزای حیاتی اکوسیستم یادگیری ماشین پایتون است، زیرا ساختار دادهای و عملیات عددی موردنیاز بسیاری از الگوریتمهای یادگیری ماشین را فراهم میکند.
برای نصب NumPy میتوانید از دستور زیر استفاده کنید:
|
1 |
pip install numpy |
Pandas
Pandas یک کتابخانه قدرتمند برای دستکاری (manipulation) و تحلیل دادههاست. این کتابخانه توابع متنوعی برای واردکردن، پاکسازی و تبدیل دادهها در اختیار میگذارد و ابزارهای پیشرفتهای برای گروهبندی و تجمیع دادهها ارائه میکند.
Pandas بهویژه در مرحله پیشپردازش دادهها در یادگیری ماشین کاربرد فراوانی دارد، زیرا امکان مدیریت و پردازش دادهها را بهصورت کارآمد فراهم میسازد.
برای نصب Pandas میتوانید از دستور زیر استفاده کنید:
|
1 |
pip install pandas |
Scikit-learn
Scikit-learn یکی از محبوبترین کتابخانههای یادگیری ماشین در پایتون است. این کتابخانه مجموعهای از الگوریتمها را برای طبقهبندی (classification)، رگرسیون (regression)، خوشهبندی (clustering) و بسیاری موارد دیگر فراهم میکند. همچنین ابزارهایی برای پیشپردازش دادهها، انتخاب ویژگیها (feature selection) و ارزیابی مدل در اختیار کاربران قرار میدهد.
Scikit-learn بهدلیل سادگی استفاده، عملکرد بالا و مستندات جامع، جایگاهی ویژه در جامعه یادگیری ماشین یافته است.
برای نصب Scikit-learn میتوانید از دستور زیر استفاده کنید:
|
1 |
pip install scikit-learn |
TensorFlow
TensorFlow یک کتابخانه متنباز برای یادگیری ماشین است که توسط شرکت Google توسعه یافته است. این کتابخانه از ساخت و آموزش مدلهای یادگیری عمیق (Deep Learning) پشتیبانی میکند و ابزارهایی برای محاسبات توزیعشده و پیادهسازی (deployment) نیز در اختیار قرار میدهد.
TensorFlow یکی از ابزارهای قدرتمند برای ساخت مدلهای پیچیدهی یادگیری ماشین است، بهویژه در حوزههای بینایی ماشین (Computer Vision) و پردازش زبان طبیعی (NLP).
برای نصب TensorFlow میتوانید از دستور زیر استفاده کنید:
|
1 |
pip install tensorflow |
PyTorch
PyTorch یکی دیگر از کتابخانههای محبوب یادگیری عمیق در پایتون است که توسط Facebook توسعه یافته است. این کتابخانه ابزارهای متنوعی برای ساخت و آموزش شبکههای عصبی (Neural Networks) ارائه میدهد و از گرافهای محاسباتی پویا (Dynamic Computation Graphs) و شتابدهی با GPU پشتیبانی میکند.
PyTorch بهویژه برای پژوهشگران و توسعهدهندگانی که نیازمند یک چارچوب یادگیری عمیق قدرتمند و انعطافپذیر هستند، بسیار مفید است.
برای نصب PyTorch میتوانید از دستور زیر استفاده کنید:
|
1 |
pip install torch |
Keras
Keras یک کتابخانه سطحبالا برای شبکههای عصبی است که بر روی TensorFlow و سایر چارچوبهای سطحپایین اجرا میشود. این کتابخانه یک رابط برنامهنویسی (API) ساده و شهودی برای ساخت و آموزش مدلهای یادگیری عمیق فراهم میکند.
سادگی و سرعت توسعه در Keras، آن را به انتخابی مناسب برای مبتدیان و پژوهشگرانی تبدیل کرده است که به نمونهسازی سریع و آزمایش مدلهای گوناگون نیاز دارند.
برای نصب Keras میتوانید از دستور زیر استفاده کنید:
|
1 |
pip install keras |
OpenCV
OpenCV یک کتابخانهی تخصصی در حوزهی بینایی ماشین (Computer Vision) است که ابزارهای متنوعی برای پردازش تصویر و ویدئو، به همراه پشتیبانی از الگوریتمهای یادگیری ماشین ارائه میدهد. این کتابخانه بهطور گسترده در جامعهی بینایی ماشین برای کارهایی همچون تشخیص اشیاء (Object Detection)، بخشبندی تصویر (Image Segmentation) و تشخیص چهره (Facial Recognition) مورد استفاده قرار میگیرد.
برای نصب OpenCV میتوانید از دستور زیر استفاده کنید:
|
1 |
pip install opencv-python |
علاوه بر کتابخانههای ذکرشده، ابزارها و چارچوبهای قدرتمند دیگری نیز در اکوسیستم پایتون برای یادگیری ماشین وجود دارند، از جمله:
-
XGBoost
-
LightGBM
-
spaCy
-
NLTK
اکوسیستم پایتون برای یادگیری ماشین همواره در حال توسعه و تکامل است و کتابخانهها و ابزارهای جدیدی بهطور مداوم معرفی میشوند.
چه یک مبتدی باشید و چه یک متخصص باتجربه یادگیری ماشین، پایتون محیطی غنی و انعطافپذیر برای توسعه و پیادهسازی مدلهای یادگیری ماشین در اختیار شما قرار میدهد. اگر تازه شروع کردهاید، گذراندن آموزش پایتون میتواند مسیر یادگیری شما را سریعتر و اصولیتر کند.
همچنین لازم به یادآوری است که برخی کتابخانهها ممکن است نیازمند وابستگیهای اضافی یا الزامات خاص سیستم باشند. در چنین مواردی، توصیه میشود برای نصب و پیکربندی صحیح، به مستندات رسمی آن کتابخانه مراجعه کنید.
راستی! برای دریافت مطالب جدید در کانال تلگرام یا پیج اینستاگرام سورس باران عضو شوید.
- انتشار: 20 آگوست 2025
دسته بندی موضوعات
- آموزش ارز دیجیتال
- آموزش برنامه نویسی
- آموزش متنی برنامه نویسی
- اطلاعیه و سایر مطالب
- پروژه برنامه نویسی
- دوره های تخصصی برنامه نویسی
- رپورتاژ
- فیلم های آموزشی
- ++C
- ADO.NET
- Adobe Flash
- Ajax
- AngularJS
- apache
- ARM
- Asp.Net
- ASP.NET MVC
- AVR
- Bootstrap
- CCNA
- CCNP
- CMD
- CSS
- Dreameaver
- EntityFramework
- HTML
- IOS
- jquery
- Linq
- Mysql
- Oracle
- PHP
- PHPMyAdmin
- Rational Rose
- silver light
- SQL Server
- Stimulsoft Reports
- Telerik
- UML
- VB.NET&VB6
- WPF
- Xml
- آموزش های پروژه محور
- اتوکد
- الگوریتم تقریبی
- امنیت
- اندروید
- اندروید استودیو
- بک ترک
- بیسیک فور اندروید
- پایتون
- جاوا
- جاوا اسکریپت
- جوملا
- دلفی
- دوره آموزش Go
- دوره های رایگان پیشنهادی
- زامارین
- سئو
- ساخت CMS
- سی شارپ
- شبکه و مجازی سازی
- طراحی الگوریتم
- طراحی بازی
- طراحی وب
- فتوشاپ
- فریم ورک codeigniter
- فلاتر
- کانستراکت
- کریستال ریپورت
- لاراول
- معماری کامپیوتر
- مهندسی اینترنت
- هوش مصنوعی
- یونیتی
- کتاب های آموزشی
- Android
- ASP.NET
- AVR
- LINQ
- php
- Workflow
- اچ تی ام ال
- بانک اطلاعاتی
- برنامه نویسی سوکت
- برنامه نویسی موبایل
- پاسکال
- پایان نامه
- پایتون
- جاوا
- جاوا اسکریپت
- جی کوئری
- داده کاوی
- دلفی
- رباتیک
- سئو
- سایر کتاب ها
- سخت افزار
- سی اس اس
- سی پلاس پلاس
- سی شارپ
- طراحی الگوریتم
- فتوشاپ
- مقاله
- مهندسی نرم افزار
- هک و امنیت
- هوش مصنوعی
- ویژوال بیسیک
- نرم افزار و ابزار برنامه نویسی
- وردپرس










