
الگوریتم بیز ساده (Naive Bayes) یک الگوریتم طبقهبندی است که بر اساس قضیه بیز (Bayes’ theorem) عمل میکند. این الگوریتم ویژگیها را مستقل از یکدیگر فرض میکند و به همین دلیل به آن «ساده» گفته میشود. الگوریتم احتمال تعلق یک نمونه به یک کلاس خاص را با توجه به احتمالات ویژگیهای آن محاسبه میکند.
بهعنوان مثال، یک تلفن همراه ممکن است هوشمند در نظر گرفته شود اگر دارای صفحهنمایش لمسی، امکان اتصال به اینترنت، دوربین خوب و غیره باشد. حتی اگر این ویژگیها به هم وابسته باشند، هر ویژگی بهصورت مستقل در تعیین احتمال هوشمند بودن تلفن نقش دارد.
احتمال پسین و استفاده از قضیه بیز
در طبقهبندی بیزی (Bayesian classification)، هدف اصلی یافتن احتمال پسین (posterior probability) است، یعنی احتمال یک برچسب (label) با توجه به ویژگیهای مشاهدهشده: P(L∣features)
با استفاده از قضیه بیز، این احتمال را میتوان به شکل کمی به صورت زیر بیان کرد:
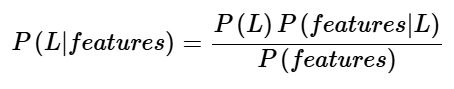
در اینجا:
-
P(L|features): احتمال پسین کلاس است.
-
P(L): احتمال پیشین کلاس است.
-
P(features|L): احتمال شرطی (likelihood) است، یعنی احتمال ویژگیها با توجه به کلاس.
-
P(features): احتمال پیشین ویژگیها است.
در الگوریتم بیز ساده، از قضیه بیز برای محاسبه احتمال تعلق یک نمونه به کلاس خاص استفاده میکنیم. ابتدا احتمال هر ویژگی نمونه با توجه به کلاس محاسبه میشود و سپس این احتمالات در هم ضرب میشوند تا احتمال شرطی نمونه برای کلاس به دست آید. سپس این احتمال شرطی در احتمال پیشین کلاس ضرب میشود تا احتمال پسین تعلق نمونه به کلاس محاسبه شود. این فرآیند برای هر کلاس تکرار میشود و در نهایت، کلاسی که بیشترین احتمال پسین را دارد بهعنوان کلاس نمونه انتخاب میشود.
انواع الگوریتم بیز ساده
الگوریتمهای مختلفی از بیز ساده (Naive Bayes) وجود دارند. در اینجا به سه نوع اصلی آن میپردازیم:
بیز ساده گاوسی (Gaussian Naive Bayes)
بیز ساده گاوسی سادهترین نوع الگوریتم بیز ساده است و فرض میکند که دادههای هر برچسب از یک توزیع گاوسی (Gaussian distribution) پیروی میکنند. این نوع الگوریتم زمانی کاربرد دارد که ویژگیها متغیرهای پیوسته باشند و از توزیع نرمال پیروی کنند.
بیز ساده چندجملهای (Multinomial Naive Bayes)
یک نوع دیگر کاربردی، بیز ساده چندجملهای است که در آن فرض میشود ویژگیها از یک توزیع چندجملهای (Multinomial distribution) گرفته شدهاند. این نوع برای ویژگیهایی که نمایانگر شمارشهای گسسته هستند مناسب است. بیز ساده چندجملهای معمولاً در کارهای طبقهبندی متن استفاده میشود، جایی که ویژگیها نشاندهنده تکرار کلمات در یک سند هستند.
بیز ساده برنولی (Bernoulli Naive Bayes)
یک مدل مهم دیگر بیز ساده برنولی است که در آن ویژگیها بهصورت دودویی (0 و 1) فرض میشوند. یکی از کاربردهای رایج این مدل، طبقهبندی متن با مدل «کیسه کلمات» (bag of words) است.
پیاده سازی الگوریتم بیز ساده با پایتون
با توجه به مجموعه دادههای خود، میتوانیم هر یک از مدلهای بیز ساده که پیشتر توضیح داده شد را انتخاب کنیم. در اینجا، مدل Gaussian Naive Bayes (بیز ساده گاوسی) را در پایتون پیادهسازی میکنیم.
ابتدا کتابخانههای مورد نیاز را وارد میکنیم:
|
1 2 3 |
import numpy as np import matplotlib.pyplot as plt import seaborn as sns; sns.set() |
make_blobs() از Scikit-learn، مجموعهای از نقاط با توزیع گاوسی ایجاد میکنیم:|
1 2 3 |
from sklearn.datasets import make_blobs X, y = make_blobs(300, 2, centers=2, random_state=2, cluster_std=1.5) plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='summer'); |
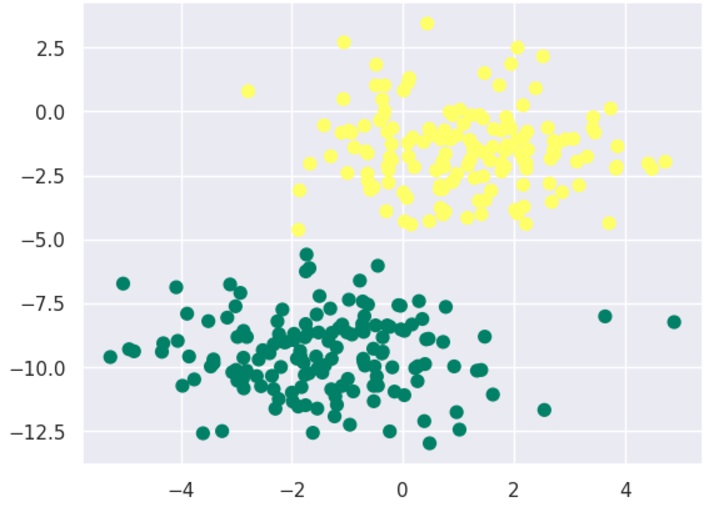
برای استفاده از مدل GaussianNB، ابتدا آن را وارد و نمونهسازی میکنیم:
|
1 2 3 |
from sklearn.naive_bayes import GaussianNB model_GNB = GaussianNB() model_GNB.fit(X, y); |
حالا نوبت به پیشبینی است. ابتدا دادههای جدیدی تولید میکنیم:
|
1 2 3 |
rng = np.random.RandomState(0) Xnew = [-6, -14] + [14, 18] * rng.rand(2000, 2) ynew = model_GNB.predict(Xnew) |
سپس برای بررسی مرزهای تصمیمگیری مدل، دادههای جدید را رسم میکنیم:
|
1 2 3 4 |
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='summer') lim = plt.axis() plt.scatter(Xnew[:, 0], Xnew[:, 1], c=ynew, s=20, cmap='summer', alpha=0.1) plt.axis(lim); |
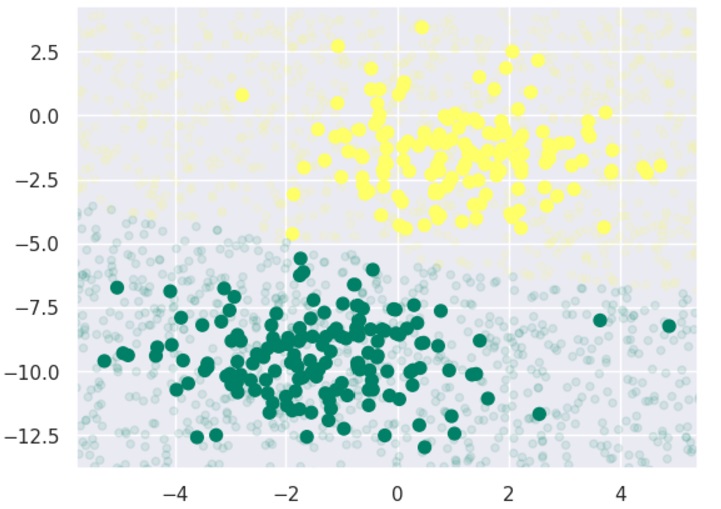
حالا با استفاده از کد زیر، میتوانیم احتمال پسین برای برچسب اول و دوم را به دست آوریم:
|
1 2 |
yprob = model_GNB.predict_proba(Xnew) yprob[-10:].round(3) |
خروجی
|
1 2 3 4 5 6 7 8 9 10 11 |
array([[0.998, 0.002], [1. , 0. ], [0.987, 0.013], [1. , 0. ], [1. , 0. ], [1. , 0. ], [1. , 0. ], [1. , 0. ], [0. , 1. ], [0.986, 0.014]] ) |
اگر هنوز با مفاهیم اولیه برنامه نویسی آشنا نیستید و میخواهید بهطور اصولی یادگیری پایتون را شروع کنید، بهترین راه شروع، شرکت در دوره تخصصی پایتون است. این دوره به شما کمک میکند تا با اصول اولیه پایتون آشنا شوید و به تدریج مهارتهای لازم برای پیادهسازی الگوریتمهای یادگیری ماشین و پروژههای پیچیده را کسب کنید.
مزایا و معایب الگوریتم بیز ساده
در این بخش به برخی مزایا و محدودیتهای الگوریتم طبقهبندی بیز ساده میپردازیم.
مزایا
مزایای استفاده از بیز ساده شامل موارد زیر است:
-
پیادهسازی آسان و سرعت بالا: الگوریتم بیز ساده به راحتی قابل اجرا است و سریع عمل میکند.
-
همگرایی سریعتر نسبت به مدلهای تمایزی: این الگوریتم سریعتر از مدلهایی مانند رگرسیون لجستیک (logistic regression) همگرا میشود.
-
نیاز به دادههای آموزشی کمتر: برای آموزش نیاز به دادههای کمتری دارد.
-
قابلیت مقیاسپذیری بالا: این الگوریتم بهصورت خطی با تعداد ویژگیها و نمونهها مقیاسپذیر است.
-
توانایی پیشبینی احتمالاتی: میتواند پیشبینیهای احتمالاتی انجام دهد و هم دادههای پیوسته و هم دادههای گسسته را مدیریت کند.
-
قابلیت استفاده در مسائل دودویی و چندکلاسه: الگوریتم بیز ساده هم برای مسائل طبقهبندی دودویی و هم چندکلاسه مناسب است.
معایب
محدودیتهای استفاده از بیز ساده عبارتاند از:
-
فرض استقلال شدید ویژگیها: یکی از مهمترین محدودیتها، فرض استقلال کامل ویژگیها است؛ در حالی که در دنیای واقعی، تقریباً هیچ مجموعهای از ویژگیها کاملاً مستقل از یکدیگر نیستند.
-
مسئله «فرکانس صفر» (Zero Frequency): اگر یک متغیر دستهای در دادههای آموزشی مشاهده نشود، الگوریتم بیز ساده به آن احتمال صفر اختصاص میدهد و قادر به پیشبینی آن نمونه نخواهد بود.
کاربردهای الگوریتم بیز ساده
برخی از کاربردهای رایج الگوریتم طبقهبندی بیز ساده عبارتاند از:
-
پیشبینی در زمان واقعی (Real-time prediction): به دلیل سهولت پیادهسازی و سرعت محاسباتی بالا، میتوان از این الگوریتم برای پیشبینی در زمان واقعی استفاده کرد.
-
پیشبینی چندکلاسه (Multi-class prediction): الگوریتم بیز ساده قادر است احتمال پسین چندین کلاس از متغیر هدف را پیشبینی کند.
-
طبقهبندی متن (Text classification): به دلیل قابلیت پیشبینی چندکلاسه، الگوریتم بیز ساده برای طبقهبندی متن بسیار مناسب است و به همین دلیل در مسائلی مانند فیلتر اسپم (spam filtering) و تحلیل احساسات (sentiment analysis) کاربرد دارد.
-
سیستمهای پیشنهاددهی (Recommendation system): همراه با الگوریتمهایی مانند Collaborative Filtering، بیز ساده میتواند در سیستمهای پیشنهاددهی به کار رود تا اطلاعات دیدهنشده را فیلتر کرده و پیشبینی کند که آیا کاربر از یک منبع خاص استقبال خواهد کرد یا خیر.
راستی! برای دریافت مطالب جدید در کانال تلگرام یا پیج اینستاگرام سورس باران عضو شوید.
- انتشار: 23 آگوست 2025
دسته بندی موضوعات
- آموزش ارز دیجیتال
- آموزش برنامه نویسی
- آموزش متنی برنامه نویسی
- اطلاعیه و سایر مطالب
- پروژه برنامه نویسی
- دوره های تخصصی برنامه نویسی
- رپورتاژ
- فیلم های آموزشی
- ++C
- ADO.NET
- Adobe Flash
- Ajax
- AngularJS
- apache
- ARM
- Asp.Net
- ASP.NET MVC
- AVR
- Bootstrap
- CCNA
- CCNP
- CMD
- CSS
- Dreameaver
- EntityFramework
- HTML
- IOS
- jquery
- Linq
- Mysql
- Oracle
- PHP
- PHPMyAdmin
- Rational Rose
- silver light
- SQL Server
- Stimulsoft Reports
- Telerik
- UML
- VB.NET&VB6
- WPF
- Xml
- آموزش های پروژه محور
- اتوکد
- الگوریتم تقریبی
- امنیت
- اندروید
- اندروید استودیو
- بک ترک
- بیسیک فور اندروید
- پایتون
- جاوا
- جاوا اسکریپت
- جوملا
- دلفی
- دوره آموزش Go
- دوره های رایگان پیشنهادی
- زامارین
- سئو
- ساخت CMS
- سی شارپ
- شبکه و مجازی سازی
- طراحی الگوریتم
- طراحی بازی
- طراحی وب
- فتوشاپ
- فریم ورک codeigniter
- فلاتر
- کانستراکت
- کریستال ریپورت
- لاراول
- معماری کامپیوتر
- مهندسی اینترنت
- هوش مصنوعی
- یونیتی
- کتاب های آموزشی
- Android
- ASP.NET
- AVR
- LINQ
- php
- Workflow
- اچ تی ام ال
- بانک اطلاعاتی
- برنامه نویسی سوکت
- برنامه نویسی موبایل
- پاسکال
- پایان نامه
- پایتون
- جاوا
- جاوا اسکریپت
- جی کوئری
- داده کاوی
- دلفی
- رباتیک
- سئو
- سایر کتاب ها
- سخت افزار
- سی اس اس
- سی پلاس پلاس
- سی شارپ
- طراحی الگوریتم
- فتوشاپ
- مقاله
- مهندسی نرم افزار
- هک و امنیت
- هوش مصنوعی
- ویژوال بیسیک
- نرم افزار و ابزار برنامه نویسی
- وردپرس










