
آمادهسازی دادهها مرحلهای حیاتی در فرایند یادگیری ماشین محسوب میشود و میتواند تأثیر چشمگیری بر دقت و کارایی مدل نهایی داشته باشد. این مرحله نیازمند دقت بالا و درک عمیقی از دادهها و مسئله موردنظر است.
در اینجا بررسی میکنیم که چگونه باید دادهها را آماده کرد تا بهخوبی با مدل یادگیری ماشین هماهنگ شده و نتایج دقیقتری حاصل شود.
تعریف آمادهسازی دادهها
آمادهسازی دادهها فرآیند کار با دادههای خام است؛ بهعبارت دیگر، شامل پاکسازی، سازماندهی و تبدیل دادهها به شکلی است که با الگوریتمهای یادگیری ماشین سازگار باشد. این فرآیند، مداوم و تکرارشونده است و نقش بسیار مهمی در عملکرد مدل یادگیری ماشین دارد. دادههای تمیز و ساختارمند، منجر به نتایج بهتر خواهند شد.
برای یادگیری عملی این مفاهیم و کار با ابزارهای مهم، شرکت در یک دوره تخصصی پایتون به شما کمک میکند مهارتهای خود را در زمینه آمادهسازی دادهها و پروژههای یادگیری ماشین تقویت کنید.
اهمیت آمادهسازی دادهها
در یادگیری ماشین، مدل بر اساس دادههایی که به آن داده میشود، یاد میگیرد. بنابراین، الگوریتم تنها زمانی میتواند بهطور مؤثر یاد بگیرد که دادهها ساختاریافته و مناسب باشند. کیفیت دادههایی که برای آموزش مدل استفاده میکنید، میتواند تأثیر بسزایی بر عملکرد آن داشته باشد.
چند جنبه که اهمیت آمادهسازی دادهها در یادگیری ماشین را نشان میدهد عبارتاند از:
-
افزایش دقت مدل: الگوریتمهای یادگیری ماشین کاملاً به دادهها وابستهاند. زمانی که دادههای پاک و ساختاریافته در اختیار مدل قرار میگیرد، خروجیها دقیقتر خواهند بود.
-
تسهیل مهندسی ویژگیها (Feature Engineering): آمادهسازی دادهها معمولاً شامل انتخاب یا ساخت ویژگیهای جدید برای آموزش مدل است. از اینرو، آمادهسازی صحیح دادهها روند مهندسی ویژگی را آسانتر میکند.
-
بهبود کیفیت دادهها: دادههای جمعآوریشده اغلب شامل ناسازگاری، خطا و اطلاعات غیرضروری هستند. بنابراین، زمانی که عملیاتهایی مانند پاکسازی و تبدیل بر روی دادهها انجام میشود، دادهها به فرمتی قابل استفاده و منظم تبدیل میگردند. این امر استخراج الگوها و بینشهای دقیقتر را ممکن میسازد.
-
افزایش سرعت و دقت پیشبینی: دادههای آمادهشده تحلیل نتایج را آسانتر کرده و منجر به نتایجی دقیقتر و قابل اتکاتر خواهند شد.
مراحل فرآیند آمادهسازی داده
فرآیند آمادهسازی داده شامل مجموعهای از مراحل است که برای مناسبسازی دادهها جهت تحلیل و مدلسازی ضروری هستند. هدف از این فرآیند، اطمینان از دقت، کاملبودن و مرتبطبودن دادهها برای تحلیل است.
مراحل اصلی در آمادهسازی داده عبارتاند از:
-
جمعآوری دادهها
-
پاکسازی دادهها
-
تبدیل دادهها
-
کاهش دادهها
-
تقسیمبندی دادهها
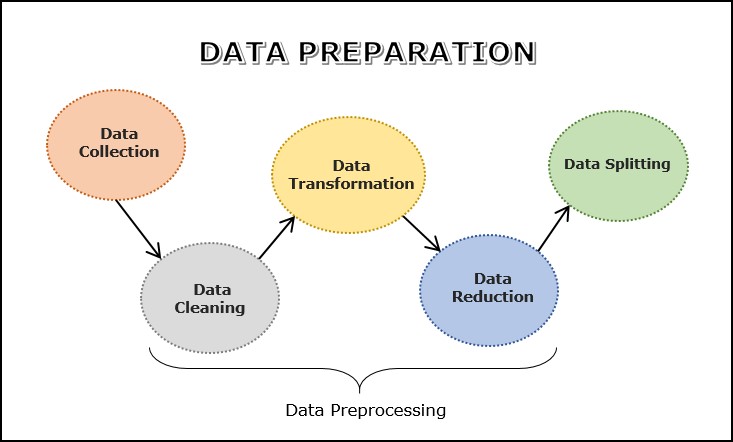
نکته: این مراحل همیشه بهصورت خطی و پشتسرهم انجام نمیشوند. ممکن است، برای مثال، قبل از تبدیل دادهها آنها را تقسیمبندی کرده یا نیاز به جمعآوری دادههای بیشتر داشته باشید.
در ادامه به بررسی دقیق هر یک از این مراحل میپردازیم:
جمعآوری دادهها
جمعآوری داده نخستین گام در فرایند یادگیری ماشین است. در این مرحله، شما دادهها را از منابع مختلف گردآوری میکنید تا بتوانید تصمیم بگیرید، به پرسشهای تحقیقاتی پاسخ دهید یا تحلیل آماری انجام دهید. منابع مختلفی مانند پایگاههای داده، فایلهای متنی، تصاویر، فایلهای صوتی یا دادههای استخراجشده از وب میتوانند برای این کار مفید باشند.
وقتی داده موردنیاز را انتخاب میکنید، لازم است آن را پیشپردازش کنید تا بتوانید الگوها و بینشهای مفید استخراج کنید. این کار، دادهها را به شکلی در میآورد که برای حل مسئله قابل استفاده باشند. گاهی اوقات، جمعآوری دادهها پس از مرحله «یکپارچهسازی داده» (Data Integration) انجام میشود.
در مرحله یکپارچهسازی، شما دادهها را از منابع مختلف ترکیب میکنید تا یک مجموعهداده واحد برای تحلیل بسازید. این کار معمولاً شامل تطبیق یا پیوند دادن رکوردها بین چند مجموعهداده، یا ادغام آنها بر اساس متغیرهای مشترک است.
بعد از انتخاب دادههای خام، باید آنها را پیشپردازش کنید. این مرحله یکی از مهمترین بخشهای آمادهسازی دادهها بهشمار میرود. در واقع، پیشپردازش دادهها به شما کمک میکند تا دادهها را به فرمی تبدیل کنید که بتوانید آنها را مستقیماً به الگوریتمهای یادگیری ماشین بدهید. همیشه باید دادهها را پیشپردازش کنید تا با ساختار مورد انتظار الگوریتمها سازگار باشند.
فرآیند پیشپردازش معمولاً شامل سه بخش زیر میشود:
-
پاکسازی دادهها
-
تبدیل دادهها (Transformation)
-
کاهش دادهها (Reduction)
در بخشهای بعدی، هرکدام از این مراحل را بهطور کامل توضیح میدهیم.
پاکسازی دادهها
پاکسازی دادهها مرحلهای مهم در فرآیند یادگیری ماشین محسوب میشود. در این مرحله، شما خطاها، مقادیر گمشده، دادههای تکراری و مقادیر پرت (Outliers) را شناسایی و اصلاح میکنید. انجام صحیح این مرحله باعث میشود دادهها دقیق، مرتبط و عاری از خطا باشند؛ در نتیجه عملکرد مدل یادگیری ماشین بهبود پیدا میکند.
برخی از تکنیکهای رایج در پاکسازی دادهها شامل جایگذاری مقادیر گمشده (Imputation)، شناسایی و حذف مقادیر پرت و حذف دادههای تکراری است. در ادامه، مراحل اصلی پاکسازی دادهها را بررسی میکنیم:
1. حذف مقادیر تکراری
وجود دادههای تکراری در مجموعه داده نشان میدهد که برخی رکوردها تکرار شدهاند. این مشکل معمولاً بهدلیل خطاهای وارد کردن اطلاعات یا نقص در فرآیند جمعآوری داده بهوجود میآید. برای حذف این مقادیر، ابتدا باید آنها را شناسایی کنید و سپس با استفاده از تابع drop_duplicates در کتابخانه Pandas آنها را حذف نمایید.
2. اصلاح خطاهای ساختاری
در این مرحله، باید خطاهایی مانند ناسازگاری در فرمت دادهها یا ناهماهنگی در شیوه نامگذاریها را برطرف کنید. با استانداردسازی فرمتها و تصحیح خطاها، میتوانید یکپارچگی و انسجام دادهها را حفظ کرده و تحلیلهای دقیقتری انجام دهید.
3. مدیریت مقادیر پرت
مقادیر پرت به دادههایی گفته میشود که از نظر مقدار، فاصله زیادی با سایر دادهها دارند و غیرعادی محسوب میشوند. برای شناسایی این مقادیر میتوانید از روشهای آماری مانند Z-Score یا IQR استفاده کنید. همچنین روشهای یادگیری ماشین مانند خوشهبندی (Clustering) و ماشین بردار پشتیبان (SVM) نیز در این زمینه کاربرد دارند.
4. مدیریت مقادیر گمشده
مقادیر گمشده به دادههایی گفته میشود که برای برخی رکوردها ذخیره نشدهاند. روشهای مختلفی برای برخورد با این مشکل وجود دارد:
-
جایگذاری (Imputation): در این روش، مقادیر گمشده را با مقدار دیگری جایگزین میکنید. این مقدار میتواند میانگین، میانه یا مد برای دادههای عددی باشد، یا رایجترین دسته برای دادههای طبقهبندیشده. از دیگر روشها میتوان به جایگذاری با استفاده از رگرسیون (Regression Imputation) یا جایگذاری چندگانه (Multiple Imputation) اشاره کرد.
-
حذف رکوردها (Deletion): در این روش، تمام نمونههایی که دارای مقدار گمشده هستند حذف میشوند. البته این روش بهدلیل از بین رفتن داده، همیشه قابلاعتماد نیست.
5. اعتبارسنجی دادهها
در مرحله اعتبارسنجی، بررسی میکنید که دادهها دقیقاً با الزامات پروژه هماهنگ باشند تا بتوانید به خروجیهای قابلاعتماد دست پیدا کنید. برخی از روشهای رایج برای اعتبارسنجی دادهها شامل موارد زیر است:
-
بررسی نوع دادهها (Data Type Check)
-
بررسی کدها یا مقادیر مجاز (Code Check)
-
بررسی فرمت (Format Check)
-
بررسی بازه مجاز (Range Check)
تبدیل دادهها
تبدیل دادهها فرآیندی است که طی آن، دادهها را از قالب اولیه به قالبی تبدیل میکنید که برای تحلیل و مدلسازی مناسب باشد. این فرایند میتواند شامل تعریف ساختار، همترازی دادهها، استخراج داده از منبع و سپس ذخیرهسازی آن در قالبی مناسب باشد.
روشهای گوناگونی برای تبدیل داده به فرمت قابل استفاده در یادگیری ماشین وجود دارد. در ادامه، برخی از رایجترین تکنیکهای تبدیل داده را معرفی میکنیم:
-
مقیاسبندی (Scaling)
-
نرمالسازی (Normalization – شامل L1 و L2)
-
استانداردسازی (Standardization)
-
دودوییسازی (Binarization)
-
کدگذاری (Encoding)
-
تبدیل لگاریتمی (Log Transformation)
در ادامه، هر یک از این تکنیکها را بهصورت جداگانه بررسی میکنیم:
1. مقیاسبندی (Scaling)
در بسیاری از مواقع، دادههایی که جمعآوری میکنید شامل ویژگیهایی با مقیاسهای متفاوت هستند. اما الگوریتمهای یادگیری ماشین نمیتوانند با این دادهها بهخوبی کار کنند. بنابراین باید آنها را بازمقیاسگذاری کرد تا همه ویژگیها در یک محدوده قرار گیرند، معمولاً بین ۰ تا ۱.
در زبان پایتون، میتوانید با استفاده از کلاس MinMaxScaler از کتابخانه Scikit-learn دادهها را بهراحتی مقیاسبندی کنید.
مثال
در این مثال، دادههای مجموعه «دیابت سرخپوستان پیما» را بازمقیاسگذاری میکنیم. ابتدا دادههای CSV را بارگذاری میکنیم (همانطور که در فصلهای قبل انجام شد) و سپس با استفاده از کلاس MinMaxScaler آنها را در محدوده ۰ تا ۱ قرار میدهیم.
|
1 2 3 4 5 6 7 |
from pandas import read_csv from numpy import set_printoptions from sklearn import preprocessing path = r'C:\pima-indians-diabetes.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(path, names=names) array = dataframe.values |
MinMaxScaler بازمقیاسگذاری کنیم:|
1 2 |
data_scaler = preprocessing.MinMaxScaler(feature_range=(0,1)) data_rescaled = data_scaler.fit_transform(array) |
|
1 2 |
set_printoptions(precision=1) print ("\nScaled data:\n", data_rescaled[0:10]) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
Scaled data: [ [0.4 0.7 0.6 0.4 0. 0.5 0.2 0.5 1. ] [0.1 0.4 0.5 0.3 0. 0.4 0.1 0.2 0. ] [0.5 0.9 0.5 0. 0. 0.3 0.3 0.2 1. ] [0.1 0.4 0.5 0.2 0.1 0.4 0. 0. 0. ] [0. 0.7 0.3 0.4 0.2 0.6 0.9 0.2 1. ] [0.3 0.6 0.6 0. 0. 0.4 0.1 0.2 0. ] [0.2 0.4 0.4 0.3 0.1 0.5 0.1 0.1 1. ] [0.6 0.6 0. 0. 0. 0.5 0. 0.1 0. ] [0.1 1. 0.6 0.5 0.6 0.5 0. 0.5 1. ] [0.5 0.6 0.8 0. 0. 0. 0.1 0.6 1. ] ] |
2. نرمالسازی (Normalization)
نرمالسازی روشی است که دادهها را در بازهای بین ۰ و ۱ بازمقیاسگذاری میکند. در این فرآیند، برای هر ویژگی (Feature)، مقدار حداقل برابر با ۰ و مقدار حداکثر برابر با ۱ تنظیم میشود.
در این روش، شما هر ردیف از دادهها را به شکلی بازمقیاسگذاری میکنید که طول (Length) آن برابر با ۱ باشد. این تکنیک بهویژه در دادههای پراکنده (Sparse Dataset) که تعداد زیادی صفر دارند بسیار کاربردی است.
در پایتون، میتوانید با استفاده از کلاس Normalizer از کتابخانهی Scikit-learn عملیات نرمالسازی را انجام دهید.
در یادگیری ماشین، دو نوع اصلی از تکنیکهای نرمالسازی پیشپردازشی وجود دارد:
-
نرمالسازی L1
-
نرمالسازی L2
نرمالسازی L1
در نرمالسازی نوع L1، مقدار هر ویژگی به گونهای تغییر میکند که مجموع مقادیر مطلق در هر ردیف برابر با ۱ باشد. این تکنیک را با نام «کمترین انحراف مطلق» (Least Absolute Deviations) نیز میشناسند.
مثال
در این مثال، از تکنیک نرمالسازی L1 برای نرمالسازی دادههای مجموعه دیابت سرخپوستان پیما استفاده میکنیم. ابتدا فایل CSV را بارگذاری کرده و سپس با استفاده از کلاس Normalizer دادهها را نرمالسازی میکنیم.
|
1 2 3 4 5 6 7 |
from pandas import read_csv from numpy import set_printoptions from sklearn.preprocessing import Normalizer path = r'C:\pima-indians-diabetes.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv (path, names=names) array = dataframe.values |
Normalizer و پارامتر norm='l1' میتوانیم دادهها را نرمالسازی کنیم:|
1 2 |
Data_normalizer = Normalizer(norm='l1').fit(array) Data_normalized = Data_normalizer.transform(array) |
|
1 2 |
set_printoptions(precision=2) print ("\nNormalized data:\n", Data_normalized [0:3]) |
|
1 2 3 4 5 6 |
Normalized data: [ [0.02 0.43 0.21 0.1 0. 0.1 0. 0.14 0. ] [0. 0.36 0.28 0.12 0. 0.11 0. 0.13 0. ] [0.03 0.59 0.21 0. 0. 0.07 0. 0.1 0. ] ] |
نرمالسازی L2
نرمالسازی L2 یکی از تکنیکهای معمول در تبدیل دادههاست که در آن، مقادیر هر ردیف از دادهها بهگونهای تغییر میکنند که مجموع مربعات آنها برابر با ۱ شود. این روش را با عنوان کمترین مربعات (Least Squares) نیز میشناسند.
مثال
در این مثال، از تکنیک نرمالسازی L2 برای نرمالسازی دادههای مجموعه «دیابت سرخپوستان پیما» استفاده میکنیم. همانند مراحل قبل، ابتدا دادههای CSV را بارگذاری میکنیم و سپس با کمک کلاس Normalizer از کتابخانه Scikit-learn عملیات نرمالسازی را انجام میدهیم.
|
1 2 3 4 5 6 7 |
from pandas import read_csv from numpy import set_printoptions from sklearn.preprocessing import Normalizer path = r'C:\pima-indians-diabetes.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv (path, names=names) array = dataframe.values |
norm='l2'، دادهها را با استفاده از L2 نرمالسازی میکنیم:|
1 2 |
Data_normalizer = Normalizer(norm='l2').fit(array) Data_normalized = Data_normalizer.transform(array) |
|
1 2 |
set_printoptions(precision=2) print ("\nNormalized data:\n", Data_normalized [0:3]) |
|
1 2 3 4 5 6 |
Normalized data: [ [0.03 0.83 0.4 0.2 0. 0.19 0. 0.28 0.01] [0.01 0.72 0.56 0.24 0. 0.22 0. 0.26 0. ] [0.04 0.92 0.32 0. 0. 0.12 0. 0.16 0.01] ] |
3. استانداردسازی (Standardization)
استانداردسازی تکنیکی است که دادهها را به یک توزیع نرمال (Gaussian) با میانگین صفر و انحراف معیار یک تبدیل میکند. این روش در الگوریتمهای یادگیری ماشین مانند رگرسیون خطی (Linear Regression) و رگرسیون لجستیک (Logistic Regression) بسیار مفید است؛ زیرا این الگوریتمها فرض میکنند دادههای ورودی دارای توزیع نرمال هستند و با دادههای مقیاسشده نتایج بهتری ارائه میدهند.
در پایتون، میتوانید با استفاده از کلاس StandardScaler از کتابخانه Scikit-learn دادهها را با میانگین ۰ و انحراف معیار ۱ استانداردسازی کنید.
مثال
در این مثال، دادههای مجموعهی «دیابت سرخپوستان پیما» را با استفاده از تکنیک استانداردسازی دوباره مقیاسگذاری میکنیم. ابتدا فایل CSV را بارگذاری میکنیم و سپس دادهها را با کمک StandardScaler به توزیع نرمال با میانگین صفر و انحراف معیار یک تبدیل میکنیم.
|
1 2 3 4 5 6 7 |
from sklearn.preprocessing import StandardScaler from pandas import read_csv from numpy import set_printoptions path = r'C:\pima-indians-diabetes.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(path, names=names) array = dataframe.values |
StandardScaler برای مقیاسبندی استفاده کنیم:|
1 2 |
data_scaler = StandardScaler().fit(array) data_rescaled = data_scaler.transform(array) |
|
1 2 |
set_printoptions(precision=2) print ("\nRescaled data:\n", data_rescaled [0:5]) |
|
1 2 3 4 5 6 7 8 |
Rescaled data: [ [ 0.64 0.85 0.15 0.91 -0.69 0.2 0.47 1.43 1.37] [-0.84 -1.12 -0.16 0.53 -0.69 -0.68 -0.37 -0.19 -0.73] [ 1.23 1.94 -0.26 -1.29 -0.69 -1.1 0.6 -0.11 1.37] [-0.84 -1. -0.16 0.15 0.12 -0.49 -0.92 -1.04 -0.73] [-1.14 0.5 -1.5 0.91 0.77 1.41 5.48 -0.02 1.37] ] |
4. دودوییسازی (Binarization)
همانطور که از نام این تکنیک مشخص است، با استفاده از آن میتوانید دادهها را به مقادیر دودویی (۰ و ۱) تبدیل کنید. برای انجام این کار، یک مقدار آستانه (Threshold) تعریف میکنید. هر مقداری که بالاتر از آستانه باشد به عدد ۱ و هر مقداری که پایینتر یا برابر با آستانه باشد به عدد ۰ تبدیل خواهد شد.
برای مثال، اگر مقدار آستانه را برابر با ۰.۵ قرار دهید، تمام مقادیری که بیشتر از ۰.۵ هستند برابر با ۱ میشوند و سایر مقادیر به ۰ تبدیل میشوند. به همین دلیل، این فرآیند را میتوان با نام آستانهگذاری (Thresholding) نیز شناخت.
این تکنیک در شرایطی کاربرد دارد که دادهها شامل احتمال (Probability) باشند و بخواهید آنها را به مقادیر قطعی (Crisp) تبدیل کنید.
در پایتون، میتوانید با کمک کلاس Binarizer از کتابخانهی Scikit-learn این فرآیند را پیادهسازی کنید.
مثال
در این مثال، از مجموعهداده «دیابت سرخپوستان پیما» استفاده میکنیم. ابتدا دادهها را از فایل CSV بارگذاری میکنیم و سپس با استفاده از Binarizer، آنها را بر اساس مقدار آستانه ۰.۵ به مقادیر دودویی ۰ و ۱ تبدیل میکنیم.
|
1 2 3 4 5 6 |
from pandas import read_csv from sklearn.preprocessing import Binarizer path = r'C:\pima-indians-diabetes.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(path, names=names) array = dataframe.values |
Binarizer به دادههای دودویی تبدیل میکنیم:|
1 2 |
binarizer = Binarizer(threshold=0.5).fit(array) Data_binarized = binarizer.transform(array) |
|
1 |
print ("\nBinary data:\n", Data_binarized [0:5]) |
|
1 2 3 4 5 6 7 8 |
Binary data: [ [1. 1. 1. 1. 0. 1. 1. 1. 1.] [1. 1. 1. 1. 0. 1. 0. 1. 0.] [1. 1. 1. 0. 0. 1. 1. 1. 1.] [1. 1. 1. 1. 1. 1. 0. 1. 0.] [0. 1. 1. 1. 1. 1. 1. 1. 1.] ] |
5. کدگذاری (Encoding)
کدگذاری تکنیکی است که برای تبدیل متغیرهای دستهای (Categorical) به مقادیر عددی بهکار میرود. این تبدیل، امکان استفاده از چنین دادههایی را در الگوریتمهای یادگیری ماشین فراهم میکند.
از جمله روشهای رایج کدگذاری میتوان به موارد زیر اشاره کرد:
-
کدگذاری برچسبی (Label Encoding)
-
کدگذاری یک-به-چند (One-Hot Encoding)
-
کدگذاری هدفمحور (Target Encoding)
کدگذاری برچسبی (Label Encoding)
بیشتر توابع موجود در کتابخانه Scikit-learn انتظار دارند که برچسبها بهصورت عددی باشند، نه متنی. بنابراین، لازم است برچسبهای متنی را به مقادیر عددی تبدیل کنید. این فرآیند را Label Encoding مینامند.
در پایتون، میتوانید با استفاده از تابع LabelEncoder() از کتابخانه Scikit-learn این تبدیل را انجام دهید.
مثال
در این مثال، یک اسکریپت پایتون برای انجام کدگذاری برچسبی اجرا میشود.
ابتدا کتابخانههای موردنیاز را وارد میکنیم:
|
1 2 |
import numpy as np from sklearn import preprocessing |
|
1 |
input_labels = ['red','black','red','green','black','yellow','white'] |
LabelEncoder میسازیم و آن را با دادههای ورودی آموزش میدهیم:|
1 2 |
encoder = preprocessing.LabelEncoder() encoder.fit(input_labels) |
|
1 2 3 4 5 6 |
test_labels = ['green','red','black'] encoded_values = encoder.transform(test_labels) print("\nLabels =", test_labels) print("Encoded values =", list(encoded_values)) encoded_values = [3,0,4,1] decoded_list = encoder.inverse_transform(encoded_values) |
|
1 2 |
print("\nEncoded values =", encoded_values) print("\nDecoded labels =", list(decoded_list)) |
|
1 2 3 4 |
Labels = ['green', 'red', 'black'] Encoded values = [1, 2, 0] Encoded values = [3, 0, 4, 1] Decoded labels = ['white', 'black', 'yellow', 'green'] |
6. تبدیل لگاریتمی (Log Transformation)
تبدیل لگاریتمی روشی است که برای اصلاح دادههای چولگی (Skewed) استفاده میشود. این تکنیک با اعمال تابع لگاریتم طبیعی (logarithm) بر روی مقادیر عددی، مقیاس آنها را اصلاح میکند و به نرمالسازی دادهها کمک مینماید.
استفاده از این روش، بهویژه زمانی مفید است که مقادیر دارای پراکندگی زیاد باشند یا چند مقدار بزرگ تأثیر نامتناسبی بر تحلیلها داشته باشند.
کاهش دادهها (Data Reduction)
کاهش دادهها تکنیکی است که با انتخاب زیرمجموعهای از ویژگیها یا مشاهدات (Observations)، حجم مجموعهداده را کاهش میدهد. این کار کمک میکند تا دادههای بیربط حذف شوند، نویز کاهش یابد و دقت مدل یادگیری ماشین افزایش پیدا کند.
از این روش زمانی استفاده میشود که:
-
حجم دادهها بسیار زیاد باشد
-
بخش قابلتوجهی از دادهها اطلاعات نامربوط یا تکراری داشته باشند
یکی از رایجترین تکنیکها در این حوزه کاهش ابعاد (Dimensionality Reduction) است. این روش حجم دادهها را بدون از بین رفتن اطلاعات مهم کاهش میدهد. در واقع، ویژگیهایی که بیشترین تأثیر را در تحلیل دارند حفظ میشوند و سایر ویژگیهای کماهمیت کنار گذاشته میشوند.
روش دیگر گسستهسازی (Discretization) است. در این روش، مقادیر پیوستهای مانند زمان یا دما را به دستههای گسسته تبدیل میکنید. این کار باعث سادهتر شدن ساختار داده میشود و تحلیل آن را نیز آسانتر میکند.
کاهش داده نهتنها باعث افزایش سرعت پردازش و کاهش منابع محاسباتی میشود، بلکه دقت و تعمیمپذیری مدل را نیز بهبود میبخشد؛ بهویژه زمانی که با مجموعهدادههای بزرگ یا پرتکرار کار میکنید.
تقسیمبندی دادهها (Data Splitting)
تقسیمبندی دادهها آخرین مرحله در فرآیند آمادهسازی داده برای یادگیری ماشین محسوب میشود. در این مرحله، دادهها به مجموعههای مختلف تقسیم میشوند:
-
دادههای آموزش (Training Set): مدلی که یادگیری ماشین انجام میدهد، از این زیرمجموعه برای شناسایی الگوها استفاده میکند.
-
دادههای اعتبارسنجی (Validation Set): از این مجموعه برای ارزیابی عملکرد مدل در حین فرایند آموزش استفاده میشود.
-
دادههای آزمون (Testing Set): پس از آموزش مدل، از این زیرمجموعه برای سنجش دقت و کارایی مدل نهایی استفاده میکنیم.
مثال پایتون
در این مثال، از مجموعه داده سرطان سینه (Breast Cancer Dataset) استفاده میکنیم تا مراحل تقسیمبندی و نرمالسازی دادهها را نمایش دهیم:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler # load the dataset data = load_breast_cancer() # separate the features and target X = data.data y = data.target # split the data into training and testing sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # normalize the data using StandardScaler scaler = StandardScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test) |
در این اسکریپت:
-
ابتدا دادههای سرطان سینه را با تابع
load_breast_cancerاز کتابخانه Scikit-learn بارگذاری میکنیم. -
ویژگیها (Features) و برچسب هدف (Target) را جدا میکنیم.
-
دادهها را با استفاده از تابع
train_test_splitبه دو بخش آموزش و آزمون تقسیم میکنیم. -
در نهایت، دادهها را با کلاس
StandardScalerنرمالسازی میکنیم؛ این عملیات، میانگین را صفر و انحراف معیار را یک میکند. این کار باعث میشود تمام ویژگیها در مقیاسی مشابه قرار بگیرند، که برای الگوریتمهایی مانند ماشین بردار پشتیبان (SVM) یا شبکههای عصبی بسیار اهمیت دارد.
آمادهسازی داده و مهندسی ویژگیها (Feature Engineering)
مهندسی ویژگی فرآیندی است که در آن، ویژگیهای جدید و مفید از دادههای موجود ایجاد میشوند. این ویژگیهای جدید میتوانند:
-
از ترکیب ویژگیهای موجود ساخته شوند
-
از تبدیل ویژگیهای خام به نمایندههای معنادار حاصل شوند
-
بر اساس دانش حوزهای (Domain Knowledge) یا تحلیلهای آماری تعریف شوند
آمادهسازی داده و مهندسی ویژگی، دو بخش کاملاً مرتبط از زنجیرهی پیشپردازش داده هستند. هر دو نقش کلیدی در بهبود عملکرد مدل یادگیری ماشین دارند.
راستی! برای دریافت مطالب جدید در کانال تلگرام یا پیج اینستاگرام سورس باران عضو شوید.
- انتشار: 21 آگوست 2025
دسته بندی موضوعات
- آموزش ارز دیجیتال
- آموزش برنامه نویسی
- آموزش متنی برنامه نویسی
- اطلاعیه و سایر مطالب
- پروژه برنامه نویسی
- دوره های تخصصی برنامه نویسی
- رپورتاژ
- فیلم های آموزشی
- ++C
- ADO.NET
- Adobe Flash
- Ajax
- AngularJS
- apache
- ARM
- Asp.Net
- ASP.NET MVC
- AVR
- Bootstrap
- CCNA
- CCNP
- CMD
- CSS
- Dreameaver
- EntityFramework
- HTML
- IOS
- jquery
- Linq
- Mysql
- Oracle
- PHP
- PHPMyAdmin
- Rational Rose
- silver light
- SQL Server
- Stimulsoft Reports
- Telerik
- UML
- VB.NET&VB6
- WPF
- Xml
- آموزش های پروژه محور
- اتوکد
- الگوریتم تقریبی
- امنیت
- اندروید
- اندروید استودیو
- بک ترک
- بیسیک فور اندروید
- پایتون
- جاوا
- جاوا اسکریپت
- جوملا
- دلفی
- دوره آموزش Go
- دوره های رایگان پیشنهادی
- زامارین
- سئو
- ساخت CMS
- سی شارپ
- شبکه و مجازی سازی
- طراحی الگوریتم
- طراحی بازی
- طراحی وب
- فتوشاپ
- فریم ورک codeigniter
- فلاتر
- کانستراکت
- کریستال ریپورت
- لاراول
- معماری کامپیوتر
- مهندسی اینترنت
- هوش مصنوعی
- یونیتی
- کتاب های آموزشی
- Android
- ASP.NET
- AVR
- LINQ
- php
- Workflow
- اچ تی ام ال
- بانک اطلاعاتی
- برنامه نویسی سوکت
- برنامه نویسی موبایل
- پاسکال
- پایان نامه
- پایتون
- جاوا
- جاوا اسکریپت
- جی کوئری
- داده کاوی
- دلفی
- رباتیک
- سئو
- سایر کتاب ها
- سخت افزار
- سی اس اس
- سی پلاس پلاس
- سی شارپ
- طراحی الگوریتم
- فتوشاپ
- مقاله
- مهندسی نرم افزار
- هک و امنیت
- هوش مصنوعی
- ویژوال بیسیک
- نرم افزار و ابزار برنامه نویسی
- وردپرس










