
جنگل تصادفی (Random Forest) یک الگوریتم یادگیری ماشین است که برای پیشبینیها از مجموعهای از درختهای تصمیم استفاده میکند. لئو بریمن (Leo Breiman) این الگوریتم را برای اولین بار در سال ۲۰۰۱ معرفی کرد. ایده اصلی الگوریتم، ایجاد تعداد زیادی درخت تصمیم است که هرکدام روی زیرمجموعهای متفاوت از دادهها آموزش میبینند. سپس پیشبینیهای این درختها با هم ترکیب شده و نتیجه نهایی ارائه میشود.
عملکرد الگوریتم جنگل تصادفی
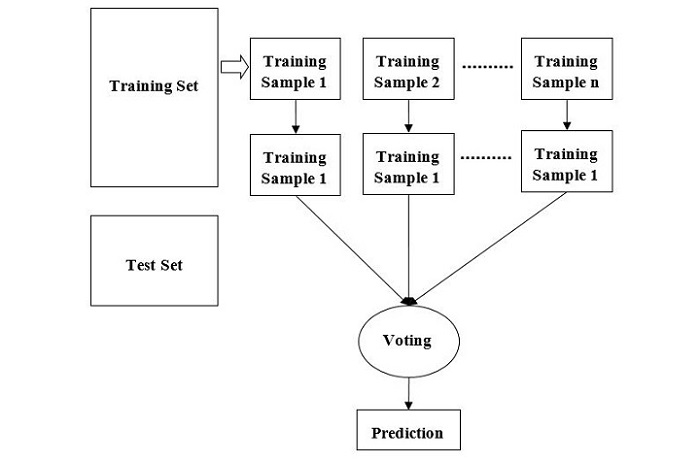
برای درک بهتر عملکرد الگوریتم، مراحل زیر را در نظر بگیرید:
۱ − ابتدا، نمونههای تصادفی از یک مجموعه داده مشخص انتخاب میشوند تا تنوع در آموزش ایجاد شود.
۲ − سپس این الگوریتم برای هر نمونه یک درخت تصمیم میسازد و پیشبینی هر درخت را دریافت میکند.
۳ − در این مرحله، برای هر پیشبینی انجامشده رأیگیری انجام میشود تا گزینه غالب مشخص شود.
۴ − در نهایت، پیشبینیای که بیشترین رأی را دارد به عنوان پیشبینی نهایی انتخاب میشود.
نمودار زیر نحوه عملکرد الگوریتم جنگل تصادفی را نشان میدهد:
جنگل تصادفی الگوریتمی انعطافپذیر است که میتواند برای وظایف دستهبندی (classification) و رگرسیون (regression) استفاده شود. در وظایف دستهبندی، الگوریتم از مد (mode) پیشبینیهای درختهای فردی برای تعیین پیشبینی نهایی استفاده میکند. در وظایف رگرسیون، الگوریتم از میانگین (mean) پیشبینیهای درختهای فردی بهره میگیرد.
مزایای الگوریتم جنگل تصادفی
این الگوریتم نسبت به سایر الگوریتمهای یادگیری ماشین مزایای متعددی دارد. برخی از مهمترین این مزایا عبارتاند از:
- مقاومت در برابر بیشبرازش (Overfitting) − الگوریتم جنگل تصادفی به دلیل استفاده از مجموعهای از درختهای تصمیم، به خوبی در برابر بیشبرازش مقاوم است. این روش باعث کاهش تأثیر نقاط پرت و نویز موجود در دادهها میشود.
- دقت بالا − الگوریتم جنگل تصادفی به خاطر دقت بالای خود شناخته شده است. ترکیب پیشبینیهای چندین درخت تصمیم کمک میکند تا اثر درختهای منفرد که ممکن است دارای خطا یا سوگیری باشند، کاهش یابد.
- مدیریت دادههای ناقص − الگوریتم جنگل تصادفی قادر است دادههای ناقص را بدون نیاز به جایگزینی (imputation) مدیریت کند. این الگوریتم تنها ویژگیهای موجود برای هر نقطه داده را در نظر میگیرد و نیازی نیست که همه ویژگیها برای تمام نقاط داده موجود باشند.
- مدلسازی روابط غیرخطی − الگوریتم جنگل تصادفی میتواند روابط غیرخطی بین ویژگیها و متغیر هدف را مدل کند. این توانایی به دلیل استفاده از درختهای تصمیم است که قادر به نمایش روابط غیرخطی هستند.
- اهمیت ویژگیها − الگوریتم جنگل تصادفی اطلاعاتی درباره اهمیت هر ویژگی در مدل ارائه میدهد. این اطلاعات میتواند برای شناسایی مهمترین ویژگیها، انتخاب ویژگیها و مهندسی ویژگیها مورد استفاده قرار گیرد.
پیاده سازی الگوریتم جنگل تصادفی در پایتون
در این بخش به پیادهسازی الگوریتم جنگل تصادفی در پایتون میپردازیم. برای این کار از کتابخانه scikit-learn استفاده خواهیم کرد. این کتابخانه یکی از محبوبترین کتابخانههای یادگیری ماشین است و مجموعهای گسترده از الگوریتمها و ابزارهای مرتبط را در اختیار کاربران قرار میدهد.
مرحله ۱ − وارد کردن کتابخانهها
ابتدا کتابخانههای لازم را وارد میکنیم. از کتابخانه pandas برای دستکاری دادهها و از scikit-learn برای پیادهسازی الگوریتم جنگل تصادفی استفاده خواهیم کرد:
|
1 2 |
import pandas as pd from sklearn.ensemble import RandomForestClassifier |
مرحله ۲ − بارگذاری دادهها
در ادامه، دادهها را در یک DataFrame از pandas بارگذاری میکنیم. برای این آموزش، از مجموعه داده مشهور Iris استفاده خواهیم کرد که یک دیتاست کلاسیک برای مسائل دستهبندی است.
|
1 2 3 4 5 |
# Loading the iris dataset iris = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learningdatabases/iris/iris.data', header=None) iris.columns = ['sepal_length', 'sepal_width', 'petal_length','petal_width', 'species'] |
مرحله ۳ − پیشپردازش دادهها
قبل از استفاده از دادهها برای آموزش مدل، لازم است دادهها را پیشپردازش کنیم. این شامل جدا کردن ویژگیها و متغیر هدف و تقسیم دادهها به مجموعههای آموزش و آزمون است.
|
1 2 3 4 5 6 7 8 |
# Separating the features and target variable X = iris.iloc[:, :-1] y = iris.iloc[:, -1] # Splitting the data into training and testing sets from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.35, random_state=42) |
مرحله ۴ − آموزش مدل
در ادامه، مدل جنگل تصادفی را روی دادههای آموزشی آموزش میدهیم.
|
1 2 3 4 5 |
# Creating the Random Forest classifier object rfc = RandomForestClassifier(n_estimators=100) # Training the model on the training data rfc.fit(X_train, y_train) |
مرحله ۵ − انجام پیشبینی
پس از آموزش مدل، میتوانیم از آن برای پیشبینی روی دادههای آزمون استفاده کنیم.
|
1 2 |
# Making predictions on the test data y_pred = rfc.predict(X_test) |
مرحله ۶ − ارزیابی مدل
در نهایت، عملکرد مدل را با استفاده از معیارهای مختلف مانند دقت (accuracy)، دقت تفکیکی (precision)، یادآوری (recall) و امتیاز F1 ارزیابی میکنیم.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# Importing the metrics library from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # Calculating the accuracy, precision, recall, and F1-score accuracy = accuracy_score(y_test, y_pred) precision = precision_score(y_test, y_pred, average='weighted') recall = recall_score(y_test, y_pred, average='weighted') f1 = f1_score(y_test, y_pred, average='weighted') print("Accuracy:", accuracy) print("Precision:", precision) print("Recall:", recall) print("F1-score:", f1) |
اگر هنوز با مفاهیم اولیه برنامهنویسی آشنا نیستید و میخواهید بهطور اصولی یادگیری پایتون را شروع کنید، بهترین راه شروع، شرکت در دوره آموزش پایتون است. این دوره به شما کمک میکند تا با اصول اولیه پایتون آشنا شوید و به تدریج مهارتهای لازم برای پیادهسازی الگوریتمهای یادگیری ماشین و پروژههای پیچیده را کسب کنید.
مثال کامل پیادهسازی
در ادامه، پیادهسازی کامل الگوریتم جنگل تصادفی با استفاده از دیتاست Iris را مشاهده میکنید:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
import pandas as pd from sklearn.ensemble import RandomForestClassifier # Loading the iris dataset iris = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learningdatabases/iris/iris.data', header=None) iris.columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species'] # Separating the features and target variable X = iris.iloc[:, :-1] y = iris.iloc[:, -1] # Splitting the data into training and testing sets from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.35, random_state=42) # Creating the Random Forest classifier object rfc = RandomForestClassifier(n_estimators=100) # Training the model on the training data rfc.fit(X_train, y_train) # Making predictions on the test data y_pred = rfc.predict(X_test) # Importing the metrics library from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # Calculating the accuracy, precision, recall, and F1-score accuracy = accuracy_score(y_test, y_pred) precision = precision_score(y_test, y_pred, average='weighted') recall = recall_score(y_test, y_pred, average='weighted') f1 = f1_score(y_test, y_pred, average='weighted') print("Accuracy:", accuracy) print("Precision:", precision) print("Recall:", recall) print("F1-score:", f1) |
خروجی
پس از اجرای کد، عملکرد مدل جنگل تصادفی به صورت زیر نمایش داده میشود:
|
1 2 3 4 |
Accuracy: 0.9811320754716981 Precision: 0.9821802935010483 Recall: 0.9811320754716981 F1-score: 0.9811157396063056 |
مزایا و معایب الگوریتم جنگل تصادفی
مزایا
-
این الگوریتم با میانگینگیری یا ترکیب نتایج درختهای تصمیم مختلف، مشکل بیشبرازش (Overfitting) را کاهش میدهد.
-
جنگل تصادفی نسبت به یک درخت تصمیم منفرد، عملکرد بهتری روی مجموعه دادههای بزرگ و متنوع دارد.
-
واریانس کمتری نسبت به یک درخت تصمیم منفرد دارد و پیشبینیهای پایدارتری ارائه میدهد.
-
الگوریتم بسیار انعطافپذیر است و دقت بسیار بالایی دارد.
-
نیازی به مقیاسدهی دادهها (Scaling) ندارد و حتی بدون اعمال مقیاسدهی، دقت خوبی حفظ میکند.
معایب
-
پیچیدگی اصلیترین نقطه ضعف الگوریتم جنگل تصادفی است.
-
ساختن جنگلهای تصادفی نسبت به درختهای تصمیم، زمانبر و دشوارتر است.
-
اجرای الگوریتم نیازمند منابع محاسباتی بیشتری است.
-
در صورتی که مجموعه بزرگی از درختها داشته باشیم، تفسیر مدل کمتر شهودی خواهد بود.
-
فرآیند پیشبینی با جنگل تصادفی نسبت به سایر الگوریتمها، زمان بیشتری میبرد.
راستی! برای دریافت مطالب جدید در کانال تلگرام یا پیج اینستاگرام سورس باران عضو شوید.
- انتشار: 23 آگوست 2025
دسته بندی موضوعات
- آموزش ارز دیجیتال
- آموزش برنامه نویسی
- آموزش متنی برنامه نویسی
- اطلاعیه و سایر مطالب
- پروژه برنامه نویسی
- دوره های تخصصی برنامه نویسی
- رپورتاژ
- فیلم های آموزشی
- ++C
- ADO.NET
- Adobe Flash
- Ajax
- AngularJS
- apache
- ARM
- Asp.Net
- ASP.NET MVC
- AVR
- Bootstrap
- CCNA
- CCNP
- CMD
- CSS
- Dreameaver
- EntityFramework
- HTML
- IOS
- jquery
- Linq
- Mysql
- Oracle
- PHP
- PHPMyAdmin
- Rational Rose
- silver light
- SQL Server
- Stimulsoft Reports
- Telerik
- UML
- VB.NET&VB6
- WPF
- Xml
- آموزش های پروژه محور
- اتوکد
- الگوریتم تقریبی
- امنیت
- اندروید
- اندروید استودیو
- بک ترک
- بیسیک فور اندروید
- پایتون
- جاوا
- جاوا اسکریپت
- جوملا
- دلفی
- دوره آموزش Go
- دوره های رایگان پیشنهادی
- زامارین
- سئو
- ساخت CMS
- سی شارپ
- شبکه و مجازی سازی
- طراحی الگوریتم
- طراحی بازی
- طراحی وب
- فتوشاپ
- فریم ورک codeigniter
- فلاتر
- کانستراکت
- کریستال ریپورت
- لاراول
- معماری کامپیوتر
- مهندسی اینترنت
- هوش مصنوعی
- یونیتی
- کتاب های آموزشی
- Android
- ASP.NET
- AVR
- LINQ
- php
- Workflow
- اچ تی ام ال
- بانک اطلاعاتی
- برنامه نویسی سوکت
- برنامه نویسی موبایل
- پاسکال
- پایان نامه
- پایتون
- جاوا
- جاوا اسکریپت
- جی کوئری
- داده کاوی
- دلفی
- رباتیک
- سئو
- سایر کتاب ها
- سخت افزار
- سی اس اس
- سی پلاس پلاس
- سی شارپ
- طراحی الگوریتم
- فتوشاپ
- مقاله
- مهندسی نرم افزار
- هک و امنیت
- هوش مصنوعی
- ویژوال بیسیک
- نرم افزار و ابزار برنامه نویسی
- وردپرس










