
شبکه عصبی عمیق (DNN) یک شبکه عصبی مصنوعی (ANN) است که دارای چندین لایه پنهان بین لایه ورودی و خروجی میباشد. مشابه شبکههای عصبی کم عمق، شبکههای عصبی عمیق میتوانند روابط غیرخطی پیچیده را مدلسازی کنند.
هدف اصلی یک شبکه عصبی دریافت مجموعهای از ورودیها، انجام محاسبات پیچیده به صورت تدریجی بر روی آنها و ارائه خروجی برای حل مشکلات دنیای واقعی مانند دستهبندی است. در اینجا، ما خود را به شبکههای عصبی فیدفوروارد محدود میکنیم.
در یک شبکه عمیق، ورودی، خروجی و جریان دادههای دنبالهدار داریم.
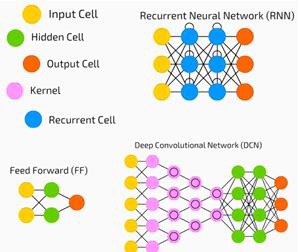
شبکههای عصبی در یادگیری نظارتشده و مشکلات یادگیری تقویتی به طور گستردهای استفاده میشوند. این شبکهها بر اساس مجموعهای از لایههای متصل به یکدیگر ساخته شدهاند.
در یادگیری عمیق، تعداد لایههای پنهان که معمولاً غیرخطی هستند، میتواند زیاد باشد؛ برای مثال حدود ۱۰۰۰ لایه.
مدلهای یادگیری عمیق نتایج به مراتب بهتری نسبت به شبکههای یادگیری ماشین معمولی تولید میکنند.
ما معمولاً از روش نزول گرادیان برای بهینهسازی شبکه و کمینه کردن تابع ضرر استفاده میکنیم.
ما میتوانیم از ایمیجنت (Imagenet)، یک مخزن از میلیونها تصویر دیجیتال برای دستهبندی یک مجموعه داده به دستههایی مانند گربهها و سگها استفاده کنیم. شبکههای یادگیری عمیق به طور فزایندهای برای تصاویر پویا به غیر از تصاویر ثابت و همچنین برای تحلیل سریهای زمانی و متنها استفاده میشوند.
آموزش مجموعه دادهها بخش مهمی از مدلهای یادگیری عمیق است. علاوه بر این، پس انتشار (Backpropagation) الگوریتم اصلی در آموزش مدلهای یادگیری عمیق است.
یادگیری عمیق با آموزش شبکههای عصبی بزرگ با تبدیلهای پیچیده ورودی و خروجی سروکار دارد.
یکی از مثالهای یادگیری عمیق، نقشهبرداری از یک عکس به نام شخص(های) موجود در آن عکس است که در شبکههای اجتماعی انجام میشود و توصیف یک تصویر با یک عبارت نیز یکی دیگر از کاربردهای اخیر یادگیری عمیق است.
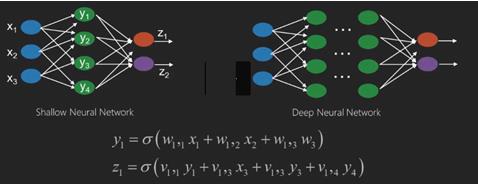
شبکههای عصبی توابعی هستند که ورودیهایی مانند x1,x2,x3 دارند که به خروجیهایی مانند z1,z2,z3 و غیره در دو عملیات میانه (شبکههای کمعمق) یا چندین عملیات میانه که به آنها لایهها گفته میشود (شبکههای عمیق) تبدیل میشوند.
وزنها و انحرافات از لایهای به لایه دیگر تغییر میکنند. w و وزنها یا سیناپسهای لایههای شبکههای عصبی هستند.
بهترین کاربرد یادگیری عمیق، مسئله یادگیری نظارتشده است. در اینجا، مجموعهای بزرگ از ورودیها با مجموعهای دلخواه از خروجیها داریم.
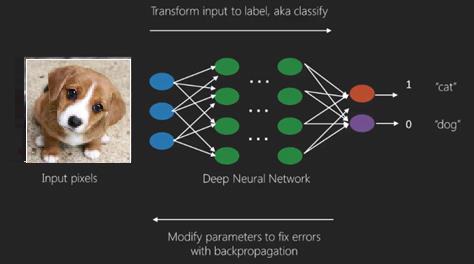
در اینجا، از الگوریتم پس انتشار (back propagation) برای پیشبینی خروجی صحیح استفاده میکنیم.
سادهترین مجموعه داده در یادگیری عمیق، MNIST است که یک مجموعه داده از ارقام دستنویس است.
ما میتوانیم یک شبکه عصبی کانولوشنی (Convolutional Neural Network) را با استفاده از Keras آموزش دهیم تا تصاویر ارقام دستنویس از این مجموعه داده را طبقهبندی کند.
فعالسازی یا شلیک یک طبقهبند شبکه عصبی امتیازی تولید میکند. به عنوان مثال، برای طبقهبندی بیماران به دو گروه بیمار و سالم، پارامترهایی مانند قد، وزن، دمای بدن، فشار خون و غیره را در نظر میگیریم.
امتیاز بالا به این معناست که بیمار است و امتیاز پایین به این معناست که سالم است.
هر گره در لایههای خروجی و پنهان طبقهبندهای خاص خود را دارد. لایه ورودی ورودیها را میگیرد و امتیازهای خود را به لایه پنهان بعدی برای فعالسازی بیشتر منتقل میکند و این فرآیند تا رسیدن به خروجی ادامه مییابد.
این پیشرفت از ورودی به خروجی در جهت جلو، که از چپ به راست حرکت میکند، به نام انتسار به جلو (Forward Propagation) شناخته میشود.
مسیر تخصیص اعتبار (CAP) در یک شبکه عصبی، سری تغییراتی است که از ورودی به خروجی شروع میشود. مسیرهای CAP اتصالات احتمالی علّی بین ورودی و خروجی را توضیح میدهند.
عمق مسیر CAP برای یک شبکه عصبی فیدفوروارد معین، برابر با تعداد لایههای پنهان به علاوه یک است، زیرا لایه خروجی نیز شامل میشود. برای شبکههای عصبی بازگشتی، جایی که سیگنال ممکن است چندین بار از لایهای عبور کند، عمق CAP ممکن است به طور بالقوه نامحدود باشد.
شبکههای عمیق و شبکههای کمعمق
هیچ مرز واضحی برای عمق وجود ندارد که یادگیری کمعمق را از یادگیری عمیق جدا کند؛ اما بهطور معمول توافق بر این است که برای یادگیری عمیق که شامل لایههای غیرخطی متعدد است، عمق مسیر تخصیص اعتبار (CAP) باید بیشتر از دو باشد.
گره پایه در شبکه عصبی یک ادراک است که شبیه به نورون در یک شبکه عصبی بیولوژیکی عمل میکند. سپس ما ادراک چندلایه (MLP) داریم. هر مجموعه ورودی توسط مجموعهای از وزنها و انحرافات تغییر میکند؛ هر لبه وزن منحصر به فرد خود را دارد و هر گره انحراف خاص خود را دارد.
دقت پیشبینی یک شبکه عصبی بستگی به وزنها و انحرافات آن دارد.
فرایند بهبود دقت شبکه عصبی آموزش نامیده میشود. خروجی از شبکهای با انتشار به جلو (forward propagation) با مقداری که میدانیم صحیح است مقایسه میشود.
تابع هزینه یا تابع ضرر، تفاوت بین خروجی تولیدشده و خروجی واقعی است.
هدف از آموزش این است که هزینه آموزش را تا حد ممکن کوچک کنیم در حالی که میلیونها نمونه آموزشی را پردازش میکنیم. برای این کار، شبکه وزنها و انحرافات را تغییر میدهد تا پیشبینی با خروجی صحیح تطابق یابد.
زمانی که شبکه بهخوبی آموزش داده شود، پتانسیل این را دارد که پیشبینی دقیقی هر بار انجام دهد.
وقتی الگو پیچیده میشود و میخواهید کامپیوتر آنها را شناسایی کند، باید به سراغ شبکههای عصبی بروید. در چنین سناریوهای الگوهای پیچیده، شبکه عصبی از تمامی الگوریتمهای رقابتی دیگر پیشی میگیرد.
امروزه پردازندههای گرافیکی (GPU) وجود دارند که قادرند شبکههای عصبی عمیق را سریعتر از همیشه آموزش دهند. شبکههای عصبی عمیق در حال انقلاب در زمینه هوش مصنوعی هستند.
کامپیوترها ثابت کردهاند که در انجام محاسبات تکراری و پیروی از دستورالعملهای دقیق بسیار خوب عمل میکنند، اما در شناسایی الگوهای پیچیده چندان موفق نبودهاند.
اگر مشکل شناسایی الگوهای ساده باشد، یک ماشین بردار پشتیبان (SVM) یا یک طبقهبند رگرسیون لجستیک میتواند بهخوبی این کار را انجام دهد، اما زمانی که پیچیدگی الگو افزایش مییابد، چارهای جز استفاده از شبکههای عصبی عمیق نیست.
بنابراین، برای الگوهای پیچیده مانند صورت انسان، شبکههای عصبی کمعمق ناکارآمد هستند و تنها گزینه موجود استفاده از شبکههای عصبی عمیق با لایههای بیشتر است. شبکههای عمیق قادرند با شکستن الگوهای پیچیده به الگوهای سادهتر، وظیفه خود را انجام دهند. به عنوان مثال، برای شناسایی صورت انسان، یک شبکه عمیق از لبهها برای شناسایی بخشهایی مانند لبها، بینی، چشمها، گوشها و غیره استفاده کرده و سپس این اجزا را دوباره ترکیب میکند تا صورت انسان را بسازد.
دقت پیشبینیهای صحیح به قدری بالا رفته است که اخیراً در یک چالش شناسایی الگو که توسط گوگل برگزار شد، یک شبکه عمیق موفق به شکست دادن انسان شد.
ایده شبکهای از ادراکات لایهای مدتی است که مطرح شده است؛ در این زمینه، شبکههای عمیق شبیه به مغز انسان عمل میکنند. اما یکی از معایب این فناوری این است که زمان زیادی برای آموزش نیاز دارد، که یک محدودیت سختافزاری است.
با این حال، پردازندههای گرافیکی با عملکرد بالا اخیراً قادر به آموزش چنین شبکههای عمیقی در کمتر از یک هفته شدهاند؛ در حالی که پردازندههای مرکزی سریعتر ممکن بود هفتهها یا شاید ماهها زمان میبرد تا همان کار را انجام دهند.
انتخاب شبکه عمیق
چگونه باید یک شبکه عصبی عمیق را انتخاب کنیم؟ ابتدا باید تصمیم بگیریم که آیا در حال ساخت یک طبقهبند هستیم یا میخواهیم الگوهایی در دادهها پیدا کنیم و آیا از یادگیری نظارتنشده استفاده خواهیم کرد. برای استخراج الگوها از یک مجموعه داده بدون برچسب، از ماشین بولتزمن محدود (Restricted Boltzmann Machine) یا خودرمزگذار (Auto Encoder) استفاده میکنیم.
در هنگام انتخاب یک شبکه عصبی عمیق باید به نکات زیر توجه کنیم:
-
برای پردازش متن، تحلیل احساسات، تجزیه و تحلیل و شناسایی موجودیتها از شبکه عصبی بازگشتی (Recurrent Net) یا شبکه تنسور عصبی بازگشتی (Recursive Neural Tensor Network یا RNTN) استفاده میکنیم.
-
برای هر مدل زبانی که در سطح کاراکتر عمل میکند، از شبکه عصبی بازگشتی استفاده میکنیم.
-
برای شناسایی تصویر از شبکه باور عمیق (Deep Belief Network یا DBN) یا شبکه کانولوشنی (Convolutional Network) استفاده میکنیم.
-
برای شناسایی اشیاء از RNTN یا شبکه کانولوشنی استفاده میکنیم.
-
برای شناسایی گفتار از شبکه عصبی بازگشتی استفاده میکنیم.
-
بهطور کلی، شبکههای باور عمیق و پرسپترونهای چندلایه با واحدهای خطی اصلاحشده (ReLU) گزینههای خوبی برای طبقهبندی هستند.
-
برای تحلیل سریهای زمانی، همیشه توصیه میشود که از شبکه عصبی بازگشتی استفاده کنید.
شبکههای عصبی بیش از ۵۰ سال است که وجود دارند، اما تنها اکنون به شهرت رسیدهاند. دلیل این موضوع این است که آموزش آنها سخت است؛ وقتی سعی میکنیم آنها را با روشی به نام پس انتشار آموزش دهیم، با مشکلی به نام گرادیانهای ناپدید شونده یا منفجر شونده (Vanishing or Exploding Gradients) مواجه میشویم. وقتی این اتفاق میافتد، آموزش زمان بیشتری میبرد و دقت کاهش مییابد.
هنگام آموزش یک مجموعه داده، ما بهطور مداوم تابع هزینه (Cost Function) را محاسبه میکنیم که تفاوت بین خروجی پیشبینی شده و خروجی واقعی از مجموعه دادههای آموزشی برچسبگذاری شده است. سپس تابع هزینه با تنظیم مقادیر وزنها و انحرافات بهگونهای که کمترین مقدار بهدست آید، کمینه میشود. فرایند آموزش از گرادیان استفاده میکند که نرخ تغییرات تابع هزینه نسبت به تغییرات مقادیر وزن یا انحرافات است.
شبکههای بولتزمن محدود یا خودرمزگذارها – RBNs
در سال ۲۰۰۶، یک پیشرفت مهم در حل مشکل گرادیانهای ناپدید شونده به دست آمد. جف هینتون استراتژی جدیدی ابداع کرد که منجر به توسعه ماشین بولتزمن محدود (Restricted Boltzmann Machine – RBM) شد، که یک شبکه دو لایه کمعمق است.
لایه اول لایه قابل مشاهده (Visible Layer) و لایه دوم لایه پنهان (Hidden Layer) است. هر گره در لایه قابل مشاهده به هر گره در لایه پنهان متصل است. شبکه بهعنوان “محدود” شناخته میشود زیرا هیچکدام از دو لایه در همان سطح به هم متصل نمیشوند.
خودرمزگذارها (Autoencoders) شبکههایی هستند که دادههای ورودی را بهعنوان بردارها کدگذاری میکنند. این شبکهها یک نمایش پنهان یا فشرده از دادههای خام ایجاد میکنند. این بردارها در کاهش ابعاد مفید هستند؛ زیرا بردار دادههای خام را به ابعاد ضروری کمتری فشرده میکند. خودرمزگذارها با رمزگشاها (Decoders) جفت میشوند که امکان بازسازی دادههای ورودی را بر اساس نمایش پنهان آنها فراهم میکنند.
ماشین بولتزمن محدود (RBM) معادل ریاضی یک مترجم دوطرفه است. در یک پاس جلو (Forward Pass)، ورودیها گرفته شده و به مجموعهای از اعداد تبدیل میشوند که ورودیها را کدگذاری میکند. در یک پاس عقب (Backward Pass)، این مجموعه اعداد گرفته شده و به ورودیهای بازسازیشده ترجمه میشود. یک شبکه خوب آموزشدیده میتواند فرآیند پسانتشار را با دقت بالایی انجام دهد.
در هر دو مرحله، وزنها و انحرافات نقش حیاتی دارند؛ آنها به RBM کمک میکنند تا روابط بین ورودیها را رمزگشایی کند و تصمیم بگیرد کدام ورودیها برای شناسایی الگوها ضروری هستند. از طریق پاسهای جلو و عقب، RBM آموزش میبیند که ورودی را با وزنها و انحرافات مختلف بازسازی کند تا زمانی که ورودی و بازسازی آن تا حد امکان به یکدیگر نزدیک شوند.
نکته جالب در مورد RBM این است که دادهها نیازی به برچسبگذاری ندارند. این موضوع برای مجموعههای داده دنیای واقعی مانند عکسها، ویدیوها، صداها و دادههای حسگر که معمولاً بدون برچسب هستند بسیار مهم است. به جای برچسبگذاری دستی دادهها توسط انسانها، RBM به طور خودکار دادهها را مرتب میکند؛ با تنظیم مناسب وزنها و انحرافات، RBM قادر است ویژگیهای مهم را استخراج کرده و ورودی را بازسازی کند. RBM بخشی از خانواده شبکههای عصبی استخراج ویژگی است که برای شناسایی الگوهای ذاتی در دادهها طراحی شدهاند. اینها همچنین به نام خودرمزگذارها (Auto-Encoders) شناخته میشوند زیرا باید ساختار خود را کدگذاری کنند.

شبکه های باور عمیق – DBNs
شبکه های باور عمیق (DBNs) با ترکیب RBMها و معرفی یک روش آموزش هوشمند شکل میگیرند. این مدل جدید بالاخره مشکل گرادیانهای ناپدید شونده را حل میکند. جف هینتون RBMها را اختراع کرد و همچنین شبکههای باور عمیق را به عنوان جایگزینی برای پس انتشار (Backpropagation) معرفی نمود.
یک DBN از نظر ساختاری مشابه پرسپترون چندلایه (MLP) است، اما در زمینه آموزش تفاوتهای زیادی دارد. این آموزش است که باعث میشود DBNها نسبت به شبکههای کمعمق خود عملکرد بهتری داشته باشند.
یک DBN را میتوان بهصورت یک پشته از RBMها تجسم کرد، جایی که لایه پنهان یک RBM بهعنوان لایه قابل مشاهده RBM بالایی آن عمل میکند. اولین RBM برای بازسازی ورودی خود به دقت هرچه بیشتر آموزش داده میشود.
لایه پنهان اولین RBM بهعنوان لایه قابل مشاهده دومین RBM در نظر گرفته میشود و دومین RBM با استفاده از خروجیهای اولین RBM آموزش میبیند. این فرآیند تکرار میشود تا هر لایه در شبکه آموزش داده شود.
در یک DBN، هر RBM تمام ورودیها را یاد میگیرد. DBN بهطور کلی کار میکند و با تنظیم تدریجی ورودیها در یک دنباله، مدل به آرامی بهبود مییابد، مانند فوکوس کردن تدریجی لنز دوربین بر روی یک تصویر. پشتهای از RBMها عملکرد بهتری از یک RBM تنها دارد، مشابه این که یک پرسپترون چندلایه (MLP) عملکرد بهتری از یک پرسپترون تک دارد.
در این مرحله، RBMها الگوهای ذاتی در دادهها را شناسایی کردهاند اما بدون هیچگونه نام یا برچسب. برای اتمام آموزش DBN، باید برچسبها را به الگوها معرفی کنیم و شبکه را با استفاده از یادگیری نظارتشده بهطور دقیق تنظیم کنیم.
ما به یک مجموعه بسیار کوچک از نمونههای برچسبگذاریشده نیاز داریم تا ویژگیها و الگوها به نامی مرتبط شوند. این مجموعه کوچک از دادههای برچسبگذاریشده برای آموزش استفاده میشود. این مجموعه از دادههای برچسبگذاریشده میتواند در مقایسه با مجموعه داده اصلی بسیار کوچک باشد.
وزنها و انحرافات بهطور کمی تغییر میکنند که منجر به تغییرات جزئی در درک شبکه از الگوها و معمولاً افزایش کوچک در دقت کلی میشود.
آموزش همچنین میتواند در مدت زمان معقولی با استفاده از پردازندههای گرافیکی (GPU) تکمیل شود، که نتایج بسیار دقیقی در مقایسه با شبکههای کمعمق ارائه میدهد و ما همچنین راهحلی برای مشکل گرادیان ناپدید شونده میبینیم.
شبکههای مولد رقابتی (GANs)
شبکههای مولد رقابتی (Generative Adversarial Networks یا GANs) شبکههای عصبی عمیقی هستند که شامل دو شبکه هستند که در برابر یکدیگر قرار دارند، به همین دلیل نام “رقابتی” را دارند.
GANها برای اولین بار در مقالهای که در سال ۲۰۱۴ توسط محققان دانشگاه مونترال منتشر شد معرفی شدند. یان لکان، متخصص هوش مصنوعی فیسبوک، در اشاره به GANها، آموزش رقابتی را جالبترین ایده در دهه اخیر در یادگیری ماشین دانست.
پتانسیل GANها بسیار زیاد است، زیرا این شبکهها میتوانند یاد بگیرند که هر نوع توزیع دادهای را شبیهسازی کنند. GANها میتوانند بهگونهای آموزش ببینند که دنیای موازی مشابه دنیای واقعی ما را در هر حوزهای بسازند: تصاویر، موسیقی، گفتار، نثر. آنها بهنوعی هنرمندان رباتی هستند و خروجی آنها بسیار چشمگیر است.
در یک GAN، یک شبکه عصبی به نام مولد (Generator) دادههای جدیدی تولید میکند، در حالی که شبکه دیگر، تمییزدهنده (Discriminator)، آنها را از نظر اصالت ارزیابی میکند.
فرض کنید میخواهیم ارقام دستنویس مشابه آنچه در مجموعه داده MNIST پیدا میشود، که از دنیای واقعی گرفته شدهاند، تولید کنیم. کار تمییزدهنده این است که هنگامی که نمونهای از مجموعه داده واقعی MNIST به آن نشان داده میشود، آنها را بهعنوان اصیل شناسایی کند.
حالا مراحل زیر را در GAN در نظر بگیرید:
-
شبکه مولد ورودیهایی به شکل اعداد تصادفی میگیرد و یک تصویر تولید میکند.
-
این تصویر تولیدشده بهعنوان ورودی به شبکه تمییزدهنده داده میشود، همراه با مجموعهای از تصاویر گرفتهشده از مجموعه داده واقعی.
-
تمییزدهنده هر دو تصویر واقعی و جعلی را دریافت کرده و احتمالها را باز میگرداند؛ یک عدد بین ۰ و ۱، که ۱ نشاندهنده پیشبینی اصالت و ۰ نشاندهنده جعلی بودن است.
بنابراین، شما یک حلقه بازخورد دوگانه دارید:
-
تمییزدهنده در یک حلقه بازخورد با حقیقت واقعی تصاویر، که ما آن را میدانیم، قرار دارد.
-
مولد در یک حلقه بازخورد با تمییزدهنده قرار دارد.
شبکه های عصبی بازگشتی – RNNs
شبکههای عصبی بازگشتی (Recurrent Neural Networks یا RNNs) شبکههای عصبی هستند که در آنها دادهها میتوانند در هر جهت جریان یابند. این شبکهها برای کاربردهایی مانند مدلسازی زبان یا پردازش زبان طبیعی (NLP) استفاده میشوند.
مفهوم پایهای که زیرساخت RNNها قرار دارد، استفاده از اطلاعات دنبالهای (Sequential Information) است. در یک شبکه عصبی معمولی، فرض بر این است که تمامی ورودیها و خروجیها مستقل از یکدیگر هستند. اما اگر بخواهیم کلمه بعدی یک جمله را پیشبینی کنیم، باید بدانیم کدام کلمات قبل از آن آمدهاند.
RNNها به دلیل تکرار همان وظیفه برای هر عنصر یک دنباله به این نام معروف هستند. خروجی آنها بر اساس محاسبات قبلی است. بنابراین میتوان گفت که RNNها حافظهای دارند که اطلاعاتی را از آنچه قبلاً محاسبه شده است، ذخیره میکند. در تئوری، RNNها میتوانند از اطلاعات در دنبالههای بسیار طولانی استفاده کنند، اما در واقعیت، آنها فقط قادرند به چند مرحله قبلی نگاه کنند.
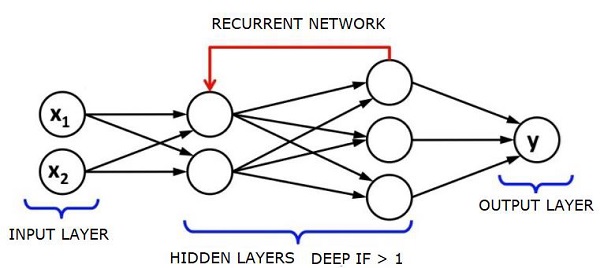
شبکههای حافظه بلندمدت کوتاهمدت (Long Short-Term Memory Networks یا LSTMs) رایجترین نوع شبکههای عصبی بازگشتی هستند.
همراه با شبکههای عصبی کانولوشنی، RNNها بهعنوان بخشی از یک مدل برای تولید توضیحات برای تصاویر بدون برچسب استفاده شدهاند. شگفتانگیز است که این فرآیند چطور بهخوبی عمل میکند.
شبکه های عصبی کانولوشنی عمیق – CNNs
اگر تعداد لایهها را در یک شبکه عصبی افزایش دهیم تا آن را عمیقتر کنیم، پیچیدگی شبکه افزایش مییابد و این امکان را میدهد که توابع پیچیدهتری مدلسازی شوند. با این حال، تعداد وزنها و انحرافات بهطور نمایی افزایش مییابد. در واقع، یادگیری چنین مسائل پیچیدهای میتواند برای شبکههای عصبی معمولی غیرممکن شود. این موضوع منجر به یک راهحل میشود: شبکههای عصبی کانولوشنی (CNNs).
CNNها بهطور گستردهای در بینایی ماشین استفاده میشوند و همچنین در مدلسازی صوتی برای شناسایی گفتار خودکار نیز به کار رفتهاند.
ایده پشت شبکههای عصبی کانولوشنی، ایده فیلتر متحرکی است که از تصویر عبور میکند. این فیلتر متحرک یا کانولوشن، بر یک ناحیه خاص از گرهها اعمال میشود که بهطور مثال ممکن است پیکسلها باشند، جایی که فیلتر اعمال شده برابر با ۰.۵ برابر مقدار گره است.
یان لکان، محقق معروف، پیشگام شبکههای عصبی کانولوشنی بود. فیسبوک بهعنوان نرمافزار شناسایی چهره از این شبکهها استفاده میکند. CNNها به راهحل اصلی پروژههای بینایی ماشین تبدیل شدهاند. شبکههای کانولوشنی لایههای زیادی دارند. در چالش Imagenet، یک ماشین در سال ۲۰۱۵ توانست انسان را در شناسایی اشیاء شکست دهد.
در یک کلام، شبکههای عصبی کانولوشنی (CNNs) شبکههای عصبی چندلایه هستند. این لایهها گاهی اوقات تا ۱۷ لایه یا بیشتر هستند و دادههای ورودی را بهعنوان تصاویر در نظر میگیرند.
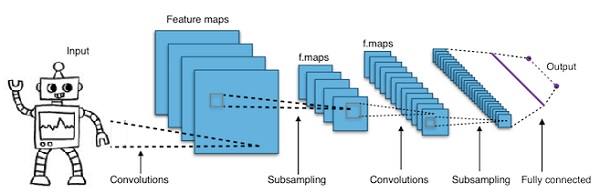
CNNها بهطور چشمگیری تعداد پارامترهایی را که باید تنظیم شوند کاهش میدهند. بنابراین، CNNها بهطور کارآمدی ابعاد بالای تصاویر خام را مدیریت میکنند.
اگر به دنبال یادگیری پایتون بهصورت حرفهای هستید، دوره تخصصی پایتون بهترین گزینه برای شماست. در این دوره، مباحث پیشرفته پایتون را بهطور کامل پوشش داده و مهارتهای لازم برای برنامه نویسی در پروژههای پیچیده و دنیای واقعی را به دست خواهید آورد.
راستی! برای دریافت مطالب جدید در کانال تلگرام یا پیج اینستاگرام سورس باران عضو شوید.
- انتشار: 24 آگوست 2025
دسته بندی موضوعات
- آموزش ارز دیجیتال
- آموزش برنامه نویسی
- آموزش متنی برنامه نویسی
- اطلاعیه و سایر مطالب
- پروژه برنامه نویسی
- دوره های تخصصی برنامه نویسی
- رپورتاژ
- فیلم های آموزشی
- ++C
- ADO.NET
- Adobe Flash
- Ajax
- AngularJS
- apache
- ARM
- Asp.Net
- ASP.NET MVC
- AVR
- Bootstrap
- CCNA
- CCNP
- CMD
- CSS
- Dreameaver
- EntityFramework
- HTML
- IOS
- jquery
- Linq
- Mysql
- Oracle
- PHP
- PHPMyAdmin
- Rational Rose
- silver light
- SQL Server
- Stimulsoft Reports
- Telerik
- UML
- VB.NET&VB6
- WPF
- Xml
- آموزش های پروژه محور
- اتوکد
- الگوریتم تقریبی
- امنیت
- اندروید
- اندروید استودیو
- بک ترک
- بیسیک فور اندروید
- پایتون
- جاوا
- جاوا اسکریپت
- جوملا
- دلفی
- دوره آموزش Go
- دوره های رایگان پیشنهادی
- زامارین
- سئو
- ساخت CMS
- سی شارپ
- شبکه و مجازی سازی
- طراحی الگوریتم
- طراحی بازی
- طراحی وب
- فتوشاپ
- فریم ورک codeigniter
- فلاتر
- کانستراکت
- کریستال ریپورت
- لاراول
- معماری کامپیوتر
- مهندسی اینترنت
- هوش مصنوعی
- یونیتی
- کتاب های آموزشی
- Android
- ASP.NET
- AVR
- LINQ
- php
- Workflow
- اچ تی ام ال
- بانک اطلاعاتی
- برنامه نویسی سوکت
- برنامه نویسی موبایل
- پاسکال
- پایان نامه
- پایتون
- جاوا
- جاوا اسکریپت
- جی کوئری
- داده کاوی
- دلفی
- رباتیک
- سئو
- سایر کتاب ها
- سخت افزار
- سی اس اس
- سی پلاس پلاس
- سی شارپ
- طراحی الگوریتم
- فتوشاپ
- مقاله
- مهندسی نرم افزار
- هک و امنیت
- هوش مصنوعی
- ویژوال بیسیک
- نرم افزار و ابزار برنامه نویسی
- وردپرس










