
در این پیاده سازی یادگیری عمیق با پایتون، هدف ما پیشبینی دادههای افت مشتری یا از دست دادن مشتری برای یک بانک خاص است. یعنی پیشبینی اینکه کدام مشتریان احتمالاً خدمات این بانک را ترک خواهند کرد. دادههای استفادهشده نسبتاً کوچک هستند و شامل ۱۰,۰۰۰ ردیف و ۱۴ ستون هستند. ما از توزیع Anaconda استفاده میکنیم و از فریمورکهایی مانند Theano، TensorFlow و Keras بهره میبریم. Keras بر اساس TensorFlow و Theano ساخته شده است که بهعنوان backend های آن عمل میکنند.
|
1 2 3 4 5 6 7 8 9 |
# شبکه عصبی مصنوعی # نصب Theano pip install --upgrade theano # نصب TensorFlow pip install upgrade tensorflow # نصب Keras pip install --upgrade keras |
گام ۱: پیشپردازش دادهها
|
1 2 3 4 5 6 7 8 9 |
In[]: # Importing the libraries import numpy as np import matplotlib.pyplot as plt import pandas as pd # Importing the database dataset = pd.read_csv('Churn_Modelling.csv') |
گام ۲
ما ماتریسهای ویژگیهای دادهها و متغیر هدف را میسازیم که ستون ۱۴، با برچسب “Exited” است.
ظاهر اولیه دادهها به صورت زیر است:
|
1 2 3 4 |
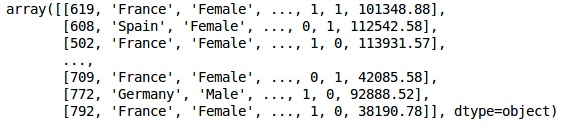
In[]: X = dataset.iloc[:, 3:13].values Y = dataset.iloc[:, 13].values X |
خروجی
گام ۳
|
1 |
Y |
خروجی
|
1 |
array([1, 0, 1, ..., 1, 1, 0], dtype = int64) |
گام ۴
ما برای سادهتر کردن تحلیل، متغیرهای رشتهای را کدگذاری میکنیم. از تابع LabelEncoder از ScikitLearn برای کدگذاری خودکار برچسبهای مختلف در ستونها با مقادیری بین ۰ تا n_classes-1 استفاده میکنیم.
|
1 2 3 4 5 6 |
from sklearn.preprocessing import LabelEncoder, OneHotEncoder labelencoder_X_1 = LabelEncoder() X[:,1] = labelencoder_X_1.fit_transform(X[:,1]) labelencoder_X_2 = LabelEncoder() X[:, 2] = labelencoder_X_2.fit_transform(X[:, 2]) X |
خروجی
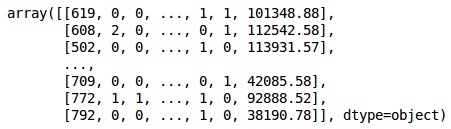
در خروجی بالا، نام کشورهای مختلف با مقادیر ۰، ۱ و ۲ جایگزین شدهاند؛ در حالی که مرد و زن با ۰ و ۱ جایگزین شدهاند.
گام ۵: برچسبگذاری دادههای کدگذاریشده
ما از همان کتابخانه ScikitLearn و تابع دیگری به نام OneHotEncoder استفاده میکنیم تا فقط شماره ستون را ارسال کرده و یک متغیر dummy ایجاد کنیم.
|
1 2 3 4 |
onehotencoder = OneHotEncoder(categorical features = [1]) X = onehotencoder.fit_transform(X).toarray() X = X[:, 1:] X |
خروجی
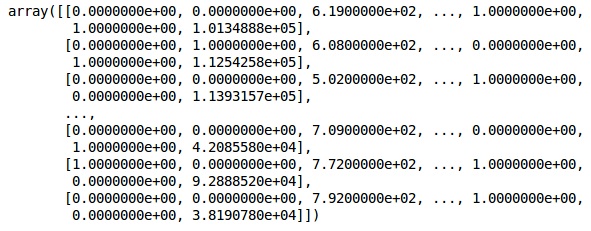
ما همیشه دادههای خود را به بخشهای آموزشی و آزمایشی تقسیم میکنیم؛ مدل خود را روی دادههای آموزشی آموزش داده و سپس دقت مدل را روی دادههای آزمایشی بررسی میکنیم که به ارزیابی کارایی مدل کمک میکند.
گام ۶
ما از تابع train_test_split کتابخانه ScikitLearn برای تقسیم دادهها به مجموعه آموزشی و تست استفاده میکنیم. نسبت تقسیم دادهها به صورت ۸۰:۲۰ حفظ میشود.
|
1 2 3 |
#Splitting the dataset into the Training set and the Test Set from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2) |
گام ۷
در این کد، ما دادههای آموزشی را با استفاده از تابع StandardScaler فیت و تبدیل میکنیم. ما مقیاسبندی خود را استاندارد میکنیم تا از همان روش فیتشده برای تبدیل/مقیاسبندی دادههای تست استفاده کنیم.
|
1 |
# Feature Scaling |
|
1 2 3 4 |
fromsklearn.preprocessing import StandardScaler sc = StandardScaler() X_train = sc.fit_transform(X_train) X_test = sc.transform(X_test) |
خروجی
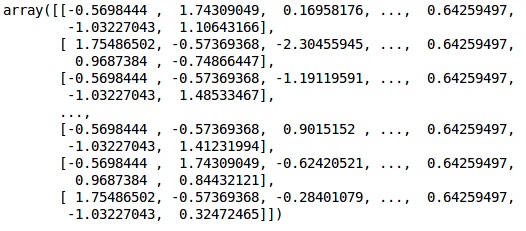
دادهها اکنون به درستی مقیاسبندی شدهاند. در نهایت، ما با پیشپردازش دادهها تمام کردهایم. حالا، شروع به ساخت مدل خود میکنیم.
گام ۸
ما ماژولهای مورد نیاز را در اینجا وارد میکنیم. ما به ماژول Sequential برای راهاندازی شبکه عصبی و ماژول Dense برای افزودن لایههای پنهان نیاز داریم.
|
1 2 3 4 |
# Importing the Keras libraries and packages import keras from keras.models import Sequential from keras.layers import Dense |
گام ۹
ما مدل را به نام “Classifier” مینامیم چون هدف ما طبقهبندی از دست دادن مشتریان است. سپس از ماژول Sequential برای راهاندازی استفاده میکنیم.
|
1 2 |
#Initializing Neural Network classifier = Sequential() |
گام ۱۰
ما لایههای پنهان را یکی یکی با استفاده از تابع Dense اضافه میکنیم. در کد زیر، تعدادی آرگومان وجود دارد.
اولین پارامتر ما output_dim است. این تعداد گرههایی است که به این لایه اضافه میکنیم. پارامتر init برای مقداردهی اولیه به روش کاهش تصادفی شیب (Stochastic Gradient Descent) استفاده میشود. در یک شبکه عصبی، به هر گره وزنی اختصاص میدهیم. در شروع، وزنها باید نزدیک به صفر باشند و ما وزنها را به طور تصادفی با استفاده از تابع uniform مقداردهی اولیه میکنیم. پارامتر input_dim فقط برای لایه اول نیاز است زیرا مدل از تعداد متغیرهای ورودی ما اطلاعی ندارد. در اینجا تعداد کل متغیرهای ورودی ۱۱ است. در لایه دوم، مدل به طور خودکار تعداد متغیرهای ورودی را از لایه اول پنهان میشناسد.
کد زیر را برای اضافه کردن لایه ورودی و اولین لایه پنهان اجرا کنید:
|
1 2 |
classifier.add(Dense(units = 6, kernel_initializer = 'uniform', activation = 'relu', input_dim = 11)) |
|
1 2 |
classifier.add(Dense(units = 6, kernel_initializer = 'uniform', activation = 'relu')) |
|
1 2 |
classifier.add(Dense(units = 1, kernel_initializer = 'uniform', activation = 'sigmoid')) |
گام ۱۱
کامپایل کردن شبکه عصبی (ANN)
ما تا کنون لایههای مختلفی را به مدل خود اضافه کردهایم. حالا باید آنها را با استفاده از متد compile کامپایل کنیم. آرگومانهایی که در کامپایل نهایی اضافه میشوند، کنترل کاملی بر روی شبکه عصبی خواهند داشت، بنابراین باید در این مرحله دقت کنیم.
در اینجا یک توضیح مختصر در مورد آرگومانها آمده است:
اولین آرگومان Optimizer است. این یک الگوریتم است که برای پیدا کردن مجموعه بهینه وزنها استفاده میشود. این الگوریتم به نام Stochastic Gradient Descent (SGD) شناخته میشود. در اینجا، ما یکی از انواع آن به نام Adam optimizer را استفاده میکنیم. الگوریتم SGD وابسته به خطا است، بنابراین دومین پارامتر loss است. اگر متغیر وابسته ما دودویی باشد، از تابع خطای لگاریتمی به نام binary_crossentropy استفاده میکنیم، و اگر متغیر وابسته ما بیش از دو دسته در خروجی داشته باشد، از categorical_crossentropy استفاده میکنیم. ما میخواهیم عملکرد شبکه عصبی خود را بر اساس دقت بهبود دهیم، بنابراین metrics را به دقت (accuracy) اضافه میکنیم.
|
1 2 |
# Compiling Neural Network classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy']) |
گام ۱۲
در این مرحله، چندین کد باید اجرا شوند.
آموزش شبکه عصبی با استفاده از مجموعه دادههای آموزشی
حالا ما مدل خود را روی دادههای آموزشی آموزش میدهیم. از متد fit برای آموزش مدل استفاده میکنیم. همچنین وزنها را برای بهبود کارایی مدل بهینه میکنیم. برای این کار باید وزنها را بروزرسانی کنیم. Batch size تعداد مشاهداتی است که پس از آن وزنها بروزرسانی میشوند. Epoch تعداد کل تکرارها است. مقادیر batch size و epoch از طریق روش آزمون و خطا انتخاب میشوند.
|
1 |
classifier.fit(X_train, y_train, batch_size = 10, epochs = 50) |
|
1 2 3 |
# Predicting the Test set results y_pred = classifier.predict(X_test) y_pred = (y_pred > 0.5) |
هدف ما این است که پیشبینی کنیم آیا مشتری با دادههای زیر بانک را ترک خواهد کرد یا خیر:
-
جغرافیا: اسپانیا
-
امتیاز اعتباری: ۵۰۰
-
جنسیت: زن
-
سن: ۴۰
-
مدت عضویت: ۳ سال
-
مانده حساب: ۵۰۰۰۰
-
تعداد محصولات: ۲
-
آیا کارت اعتباری دارد؟ بله
-
آیا عضو فعال است؟ بله
برای پیشبینی چنین مشاهدهای میتوانیم از مدل استفاده کنیم.
گام ۱۳
پیشبینی نتایج مجموعه تست
نتیجه پیشبینی احتمال ترک مشتری از شرکت را به شما میدهد. ما این احتمال را به مقادیر دودویی ۰ و ۱ تبدیل خواهیم کرد.
|
1 2 3 |
# پیشبینی نتایج مجموعه تست y_pred = classifier.predict(X_test) y_pred = (y_pred > 0.5) |
|
1 2 3 4 |
# پیشبینی یک مشاهده جدید new_prediction = classifier.predict(sc.transform (np.array([[0.0, 0, 500, 1, 40, 3, 50000, 2, 1, 1, 40000]]))) new_prediction = (new_prediction > 0.5) |
گام ۱۴
این آخرین گام است که در آن عملکرد مدل خود را ارزیابی میکنیم. ما نتایج اصلی را داریم و به این ترتیب میتوانیم ماتریس سردرگمی (Confusion Matrix) را بسازیم تا دقت مدل خود را بررسی کنیم.
ساخت ماتریس سردرگمی (Confusion Matrix)
|
1 2 3 |
from sklearn.metrics import confusion_matrix cm = confusion_matrix(y_test, y_pred) print (cm) |
خروجی
|
1 2 3 |
loss: 0.3384 acc: 0.8605 [ [1541 54] [230 175] ] |
|
1 |
Accuracy = 1541+175/2000=0.858 |
پیشنهاد ویژه : آموزش طراحی سایت با پایتون
الگوریتم پیشروی به جلو (Forward Propagation)
در این بخش، ما یاد خواهیم گرفت که چگونه کد بنویسیم تا پیشروی به جلو (پیشبینی) را برای یک شبکه عصبی ساده انجام دهیم.
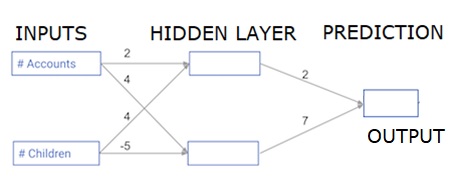
هر داده نقطه یک مشتری است. اولین ورودی تعداد حسابهایی است که دارند و ورودی دوم تعداد فرزندانی است که دارند. مدل پیشبینی خواهد کرد که این کاربر در سال آینده چه تعداد تراکنش انجام خواهد داد.
ورودی دادهها از پیش بارگذاری شده است و وزنها در یک دیکشنری به نام weights قرار دارند. آرایه وزنها برای اولین نود در لایه پنهان در weights['node_0'] و برای دومین نود در لایه پنهان در weights['node_1'] قرار دارند.
وزنهای وارد شده به نود خروجی نیز در weights موجود هستند.
تابع فعالسازی ReLU (Rectified Linear Activation Function)
یک “تابع فعالسازی” تابعی است که در هر نود شبکه عصبی کار میکند. این تابع ورودی نود را به یک خروجی تبدیل میکند.
تابع فعالسازی ReLU (که به معنی Rectified Linear Unit) است، در شبکههای بسیار پرتوان استفاده میشود. این تابع یک عدد را به عنوان ورودی میگیرد و اگر ورودی منفی باشد، مقدار ۰ را بازمیگرداند، و اگر ورودی مثبت باشد، همان ورودی را به عنوان خروجی بازمیگرداند.
در اینجا چند مثال آورده شده است:
- relu(4) = 4
- relu(-2) = 0
در ادامه، تعریف تابع relu() را پر میکنیم:
- ما از تابع
max()برای محاسبه مقدار خروجی تابع ReLU استفاده میکنیم. - ما تابع
relu()را رویnode_0_inputاعمال میکنیم تا مقدارnode_0_outputرا محاسبه کنیم. - ما تابع
relu()را رویnode_1_inputاعمال میکنیم تا مقدارnode_1_outputرا محاسبه کنیم.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
import numpy as np input_data = np.array([-1, 2]) weights = { 'node_0': np.array([3, 3]), 'node_1': np.array([1, 5]), 'output': np.array([2, -1]) } node_0_input = (input_data * weights['node_0']).sum() node_0_output = np.tanh(node_0_input) node_1_input = (input_data * weights['node_1']).sum() node_1_output = np.tanh(node_1_input) hidden_layer_output = np.array(node_0_output, node_1_output) output =(hidden_layer_output * weights['output']).sum() print(output) def relu(input): '''Define your relu activation function here''' # Calculate the value for the output of the relu function: output output = max(input,0) # Return the value just calculated return(output) # Calculate node 0 value: node_0_output node_0_input = (input_data * weights['node_0']).sum() node_0_output = relu(node_0_input) # Calculate node 1 value: node_1_output node_1_input = (input_data * weights['node_1']).sum() node_1_output = relu(node_1_input) # Put node values into array: hidden_layer_outputs hidden_layer_outputs = np.array([node_0_output, node_1_output]) # Calculate model output (do not apply relu) odel_output = (hidden_layer_outputs * weights['output']).sum() print(model_output)# Print model output |
خروجی
|
1 2 |
0.9950547536867305 -3 |
اعمال شبکه به چندین مشاهده/ردیف داده
در این بخش، ما یاد خواهیم گرفت که چگونه یک تابع به نام predict_with_network() تعریف کنیم. این تابع پیشبینیها را برای چندین مشاهده داده تولید میکند که از شبکه بالا به عنوان ورودی گرفته میشوند. وزنهای دادهشده در شبکه بالا نیز مورد استفاده قرار میگیرند. همچنین تعریف تابع relu() نیز استفاده خواهد شد.
بیایید یک تابع به نام predict_with_network() تعریف کنیم که دو آرگومان – input_data_row و weights را میپذیرد و پیشبینی مدل را به عنوان خروجی برمیگرداند.
ما مقادیر ورودی و خروجی برای هر نود را محاسبه کرده و آنها را در node_0_input, node_0_output, node_1_input, و node_1_output ذخیره میکنیم.
برای محاسبه مقدار ورودی یک نود، ما آرایههای مربوطه را با هم ضرب کرده و مجموع آنها را محاسبه میکنیم.
برای محاسبه مقدار خروجی یک نود، ما تابع relu() را به مقدار ورودی نود اعمال میکنیم. از یک حلقه for برای تکرار روی input_data استفاده میکنیم.
ما همچنین از تابع predict_with_network() برای تولید پیشبینیها برای هر ردیف از دادههای ورودی – input_data_row استفاده میکنیم و پیشبینیها را به results اضافه میکنیم.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# Define predict_with_network() def predict_with_network(input_data_row, weights): # Calculate node 0 value node_0_input = (input_data_row * weights['node_0']).sum() node_0_output = relu(node_0_input) # Calculate node 1 value node_1_input = (input_data_row * weights['node_1']).sum() node_1_output = relu(node_1_input) # Put node values into array: hidden_layer_outputs hidden_layer_outputs = np.array([node_0_output, node_1_output]) # Calculate model output input_to_final_layer = (hidden_layer_outputs*weights['output']).sum() model_output = relu(input_to_final_layer) # Return model output return(model_output) # Create empty list to store prediction results results = [] for input_data_row in input_data: # Append prediction to results results.append(predict_with_network(input_data_row, weights)) print(results)# Print results |
خروجی
|
1 |
[0, 12] |
در اینجا از تابع relu() استفاده کردهایم که relu(26) = 26 و relu(-13) = 0 است و همینطور برای سایر مقادیر.
شبکه عصبی با چند لایه پنهان عمیق
در این بخش، ما کدی مینویسیم تا پیشروی به جلو (forward propagation) را برای یک شبکه عصبی با دو لایه پنهان انجام دهیم. هر لایه پنهان شامل دو نود است. داده ورودی به عنوان input_data از قبل بارگذاری شده است. نودهای لایه پنهان اول به نامهای node_0_0 و node_0_1 شناخته میشوند.
وزنهای مربوط به این نودها از قبل بارگذاری شدهاند و در weights['node_0_0'] و weights['node_0_1'] قرار دارند.
نودهای لایه پنهان دوم به نامهای node_1_0 و node_1_1 هستند. وزنهای مربوط به این نودها در weights['node_1_0'] و weights['node_1_1'] قرار دارند.
در نهایت، خروجی مدل با استفاده از وزنهای weights['output'] و نودهای لایه پنهان دوم محاسبه میشود.
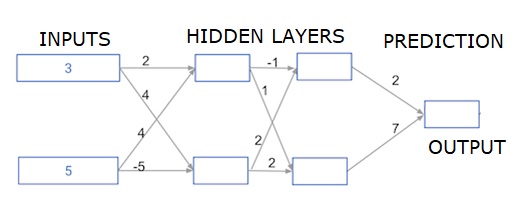
ما ورودی node_0_0_input را با استفاده از وزنهای weights['node_0_0'] و داده ورودی input_data محاسبه میکنیم. سپس تابع ReLU را اعمال میکنیم تا node_0_0_output به دست آید.
ما همین کار را برای node_0_1_input انجام میدهیم تا node_0_1_output را به دست آوریم.
ما ورودی node_1_0_input را با استفاده از وزنهای weights['node_1_0'] و خروجیهای لایه پنهان اول (hidden_0_outputs) محاسبه میکنیم. سپس تابع ReLU را اعمال میکنیم تا node_1_0_output به دست آید.
ما همین کار را برای node_1_1_input انجام میدهیم تا node_1_1_output را به دست آوریم.
ما خروجی مدل model_output را با استفاده از وزنهای weights['output'] و خروجیهای لایه پنهان دوم (hidden_1_outputs) محاسبه میکنیم. در اینجا تابع ReLU را به خروجی مدل اعمال نمیکنیم.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
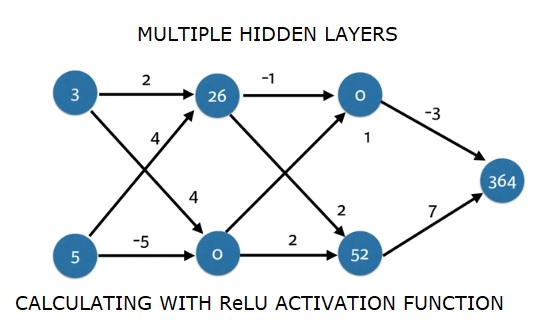
import numpy as np input_data = np.array([3, 5]) weights = { 'node_0_0': np.array([2, 4]), 'node_0_1': np.array([4, -5]), 'node_1_0': np.array([-1, 1]), 'node_1_1': np.array([2, 2]), 'output': np.array([2, 7]) } def predict_with_network(input_data): # Calculate node 0 in the first hidden layer node_0_0_input = (input_data * weights['node_0_0']).sum() node_0_0_output = relu(node_0_0_input) # Calculate node 1 in the first hidden layer node_0_1_input = (input_data*weights['node_0_1']).sum() node_0_1_output = relu(node_0_1_input) # Put node values into array: hidden_0_outputs hidden_0_outputs = np.array([node_0_0_output, node_0_1_output]) # Calculate node 0 in the second hidden layer node_1_0_input = (hidden_0_outputs*weights['node_1_0']).sum() node_1_0_output = relu(node_1_0_input) # Calculate node 1 in the second hidden layer node_1_1_input = (hidden_0_outputs*weights['node_1_1']).sum() node_1_1_output = relu(node_1_1_input) # Put node values into array: hidden_1_outputs hidden_1_outputs = np.array([node_1_0_output, node_1_1_output]) # Calculate model output: model_output model_output = (hidden_1_outputs*weights['output']).sum() # Return model_output return(model_output) output = predict_with_network(input_data) print(output) |
خروجی
|
1 |
364 |
راستی! برای دریافت مطالب جدید در کانال تلگرام یا پیج اینستاگرام سورس باران عضو شوید.
- انتشار: 26 آگوست 2025
دسته بندی موضوعات
- آموزش ارز دیجیتال
- آموزش برنامه نویسی
- آموزش متنی برنامه نویسی
- اطلاعیه و سایر مطالب
- پروژه برنامه نویسی
- دوره های تخصصی برنامه نویسی
- رپورتاژ
- فیلم های آموزشی
- ++C
- ADO.NET
- Adobe Flash
- Ajax
- AngularJS
- apache
- ARM
- Asp.Net
- ASP.NET MVC
- AVR
- Bootstrap
- CCNA
- CCNP
- CMD
- CSS
- Dreameaver
- EntityFramework
- HTML
- IOS
- jquery
- Linq
- Mysql
- Oracle
- PHP
- PHPMyAdmin
- Rational Rose
- silver light
- SQL Server
- Stimulsoft Reports
- Telerik
- UML
- VB.NET&VB6
- WPF
- Xml
- آموزش های پروژه محور
- اتوکد
- الگوریتم تقریبی
- امنیت
- اندروید
- اندروید استودیو
- بک ترک
- بیسیک فور اندروید
- پایتون
- جاوا
- جاوا اسکریپت
- جوملا
- دلفی
- دوره آموزش Go
- دوره های رایگان پیشنهادی
- زامارین
- سئو
- ساخت CMS
- سی شارپ
- شبکه و مجازی سازی
- طراحی الگوریتم
- طراحی بازی
- طراحی وب
- فتوشاپ
- فریم ورک codeigniter
- فلاتر
- کانستراکت
- کریستال ریپورت
- لاراول
- معماری کامپیوتر
- مهندسی اینترنت
- هوش مصنوعی
- یونیتی
- کتاب های آموزشی
- Android
- ASP.NET
- AVR
- LINQ
- php
- Workflow
- اچ تی ام ال
- بانک اطلاعاتی
- برنامه نویسی سوکت
- برنامه نویسی موبایل
- پاسکال
- پایان نامه
- پایتون
- جاوا
- جاوا اسکریپت
- جی کوئری
- داده کاوی
- دلفی
- رباتیک
- سئو
- سایر کتاب ها
- سخت افزار
- سی اس اس
- سی پلاس پلاس
- سی شارپ
- طراحی الگوریتم
- فتوشاپ
- مقاله
- مهندسی نرم افزار
- هک و امنیت
- هوش مصنوعی
- ویژوال بیسیک
- نرم افزار و ابزار برنامه نویسی
- وردپرس










