
هوش مصنوعی با پایتون – پکیج NLTK

هوش مصنوعی با پایتون – پکیج NLTK
در این درس از مجموعه آموزش برنامه نویسی سایت سورس باران، ما یاد خواهیم گرفت که چگونه با پکیج Natural Language Toolkit) NLTK) شروع به کار کنیم.
پيش نياز
اگر می خواهیم با پردازش زبان طبیعی برنامه هایی ایجاد کنیم، تغییر در زمینه کار را دشوارتر می کند. عامل زمینه بر نحوه درک یک جمله خاص توسط دستگاه تأثیر می گذارد. از این رو، ما باید برنامه های زبان طبیعی را با استفاده از رویکردهای یادگیری ماشین توسعه دهیم تا ماشین همچنین بتواند روشی را که انسان می تواند زمینه را درک کند، درک کند.
پیشنهاد ویژه : پکیج آموزش پایتون مختص بازار کار
برای ساخت چنین برنامه هایی از پکیج پایتون به نام NLTK (پکیج زبان ابزار طبیعی) استفاده خواهیم کرد.
وارد کردن پکیج NLTK
ما قبل از استفاده از NLTK باید آن را نصب کنیم. با کمک دستور زیر قابل نصب است –
|
1 |
pip install nltk |
برای ساخت یک پکیج conda برای NLTK ، از دستور زیر استفاده کنید –
|
1 |
conda install -c anaconda nltk |
اکنون پس از نصب پکیج NLTK، باید آن را از طریق خط فرمان پایتون وارد کنیم. ما می توانیم آن را با نوشتن دستور زیر در خط فرمان وارد کنیم –
|
1 |
>>> import nltk |
بارگیری داده های NLTK
اکنون پس از وارد کردن NLTK ، باید داده های مورد نیاز را بارگیری کنیم. این کار با کمک دستور زیر در خط فرمان انجام می شود –
|
1 |
>>> nltk.download () |
نصب پکیج های ضروری دیگر
برای ساخت برنامه های پردازش زبان طبیعی با استفاده از NLTK ، ما باید پکیج های لازم را نصب کنیم. پکیج ها به شرح زیر است –
gensim
این یک کتابخانه مدل سازی معنایی قوی است که برای بسیاری از برنامه ها مفید است. با اجرای دستور زیر می توانیم آن را نصب کنیم –
|
1 |
pip install gensim |
pattern
برای کارکرد صحیح بسته gensim استفاده می شود. با اجرای دستور زیر می توانیم آن را نصب کنیم
|
1 |
pip install pattern |
مفهوم توکن سازی، ریشه یابی و لماتیزاسیون
در این بخش، خواهیم فهمید که توکن سازی ، ریشه یابی و لماتیزاسیون چیست.
توکن سازی
این ممکن است به عنوان روند شکستن متن داده شده نیز گفته شود. به عنوان مثال توالی کاراکتر به واحدهای کوچکتر به نام توکن تعریف شود. نشانه ها ممکن است کلمات ، اعداد یا علائم نگارشی باشند. به آن تقسیم بندی کلمه نیز گفته می شود. در زیر یک مثال ساده از توکن سازی وجود دارد –
ورودی –
Mango, banana, pineapple and apple all are fruits.
خروجی

روند شکستن متن داده شده را می توان با کمک در تعیین مرزهای کلمه انجام داد. پایان یک کلمه و آغاز یک کلمه جدید را مرز کلمه می نامند. سیستم نوشتاری و ساختار تایپی کلمات بر مرزها تأثیر می گذارد.
در ماژول Python NLTK، پکیج های مختلفی در رابطه با توکن سازی داریم که می توانیم متناسب با نیاز خود متن را به توکن تقسیم کنیم. برخی از پکیج ها به شرح زیر است –
پکیج sent_tokenize
همانطور که از نامش پیداست، این پکیج متن ورودی را به جملات تقسیم می کند. ما می توانیم این پکیج را با کمک کد پایتون زیر وارد کنیم –
|
1 |
from nltk.tokenize import sent_tokenize |
پکیج word_tokenize
این پکیج متن ورودی را به کلمات تقسیم می کند. ما می توانیم این پکیج را با کمک کد پایتون زیر وارد کنیم –
|
1 |
from nltk.tokenize import word_tokenize |
پکیج WordPunctTokenizer
این پکیج متن ورودی را به کلمات و همچنین علائم نگارشی تقسیم می کند. ما می توانیم این پکیج را با کمک کد پایتون زیر وارد کنیم –
|
1 |
from nltk.tokenize import WordPuncttokenizer |
ریشه یابی
هنگام کار با کلمات ، به دلایل دستوری با تغییرات زیادی روبرو می شویم. مفهوم تغییرات در اینجا بدان معنی است که ما باید با اشکال مختلف همان واژه ها مانند دموکراسی ، دموکراتیک و دموکراتیک سازی کنار بیاییم. برای ماشین ها بسیار ضروری است که درک کنند این کلمات مختلف شکل پایه یکسانی دارند. بدین ترتیب استخراج اشکال پایه کلمات در حالی که در حال تحلیل متن هستیم مفید خواهد بود.
ما می توانیم با ریشه یابی به این مهم برسیم. به این ترتیب می توان گفت که stemming فرآیند ابتکاری استخراج اشکال پایه کلمات با خرد کردن انتهای کلمات است.
در ماژول Python NLTK، پکیج های مختلفی در رابطه با stemming داریم. از این پکیج ها می توان برای بدست آوردن اشکال پایه کلمه استفاده کرد. این پکیج ها از الگوریتم ها استفاده می کنند. برخی از پکیج ها به شرح زیر است –
پکیج PorterStemmer
این پکیج پایتون از الگوریتم Porter برای استخراج فرم پایه استفاده می کند. ما می توانیم این پکیج را با کمک کد پایتون زیر وارد کنیم –
|
1 |
from nltk.stem.porter import PorterStemmer |
به عنوان مثال، اگر کلمه‘writing’ را به عنوان ورودی این پایه بنویسیم ، پس از ریشه یابی کلمه ‘write’ بدست خواهیم آورد.
پکیج LancasterStemmer
این پکیج پایتون از الگوریتم Lancaster’s برای استخراج فرم پایه استفاده می کند. ما می توانیم این پکیج را با کمک کد پایتون زیر وارد کنیم –
|
1 |
from nltk.stem.lancaster import LancasterStemmer |
به عنوان مثال، اگر کلمه‘writing’ را به عنوان ورودی این پایه بنویسیم ، پس از ریشه یابی کلمه ‘write’ بدست خواهیم آورد.
پکیج SnowballStemmer
این پکیج پایتون از الگوریتم گلوله برفی برای استخراج فرم پایه استفاده می کند. ما می توانیم این پکیج را با کمک کد پایتون زیر وارد کنیم –
|
1 |
from nltk.stem.snowball import SnowballStemmer |
به عنوان مثال، اگر کلمه‘writing’ را به عنوان ورودی این پایه بنویسیم ، پس از ریشه یابی کلمه ‘write’ بدست خواهیم آورد.
تمام این الگوریتم ها از سختگیری متفاوت برخوردارند. اگر این سه پایه را مقایسه کنیم، پایه های Porter کمترین و Lancaster سخت ترین است. Snowball stemmer از نظر سرعت و همچنین سخت گیری خوب است.
لماتیزاسیون
همچنین با استفاده از لماتیزاسیون می توانیم شکل پایه کلمات را استخراج کنیم. اساساً این کار را با استفاده از واژگان و تجزیه و تحلیل واژگان کلمات انجام می دهد، به طور معمول فقط حذف انتهای عطف است. به این نوع شکل پایه هر کلمه لما گفته می شود.
تفاوت اصلی بین ریشه یابی و لماتیزه کردن، استفاده از واژگان و تجزیه و تحلیل ریخت شناسی کلمات است. تفاوت دیگر این است که ریشه معمولاً کلمات مرتبط با اشتقاق را فرو می ریزد در حالی که لماتیزاسیون معمولاً اشکال مختلف عطف لما را فرو می ریزد. به عنوان مثال ، اگر کلمه saw را به عنوان کلمه ورودی ارائه دهیم، ممکن است ریشه یابی کلمه “s” را برگرداند اما لماتیزاسیون بسته به اینکه فعل یا اسم استفاده شده باشد، کلمه را see یا saw را می بیند.
در ماژول Python NLTK، پکیج زیر مربوط به فرآیند لماتیزاسیون وجود دارد که می توانیم از آن برای بدست آوردن اشکال پایه کلمه استفاده کنیم –
پکیج WordNetLemmatizer
این پکیج بسته به نوع استفاده از آن به عنوان اسم یا فعل، شکل اصلی کلمه را استخراج می کند. ما می توانیم این بسته را با کمک کد پایتون زیر وارد کنیم –
|
1 |
from nltk.stem import WordNetLemmatizer |
تکه تکه کردن: تقسیم داده ها به تکه ها
این یکی از فرایندهای مهم در پردازش زبان طبیعی است. وظیفه اصلی تکه تکه کردن (Chunking) ، شناسایی قسمت های گفتار و عبارات کوتاه مانند عبارات اسمی است. ما در حال حاضر روند توکن سازی، ایجاد رمزها را مطالعه کرده ایم. Chunking در اصل برچسب گذاری آن نشانه ها است. به عبارت دیگر، chunking ساختار جمله را به ما نشان می دهد.
در بخش زیر ، با انواع مختلف Chunking آشنا خواهیم شد.
انواع chunking
دو نوع تقسیم وجود دارد. انواع آنها به شرح زیر است –
Chunking up
در این فرآیند تکه تکه کردن object, things و غیره به سمت عمومی تر شدن حرکت می کنند و زبان انتزاعی می شود. احتمال توافق بیشتر است. در این فرآیند، بزرگنمایی می کنیم. به عنوان مثال، اگر این سوال را که “اتومبیل ها برای چه هدفی هستند” تمرکز کنیم؟ ممکن است پاسخ “حمل و نقل” را دریافت کنیم.
Chunking down
در این فرآیند تکه تکه کردن، object, things و غیره به سمت خاص تر شدن حرکت می کنند و زبان بیشتر نفوذ می کند. ساختار عمیق تر در تقسیم پایین بررسی می شود. در این فرآیند، ما بزرگ نمایی می کنیم. به عنوان مثال ، اگر سوال “به طور خاص در مورد یک ماشین بگویید” ما اطلاعاتی با جزئیات ریزتر در مورد ماشین به دست خواهیم آورد.
مثال
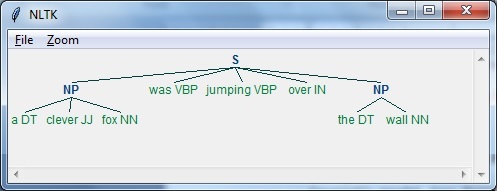
در این مثال، ما با استفاده از ماژول NLTK در پایتون، متن-کلمه اسم را دسته بندی می کنیم ، دسته ای از کلمات که عبارات اسمی را در جمله پیدا می کند –
برای اجرای عبارت chunking این مراحل را در پایتون دنبال کنید –
- مرحله 1 – در این مرحله ، باید گرامر را برای chunking تعریف کنیم. این شامل قوانینی است که باید از آنها پیروی کنیم.
- مرحله 2 – در این مرحله ، باید یک تجزیه کننده تکه ایجاد کنیم. این دستور زبان را تجزیه می کند و نتیجه می دهد.
- مرحله 3 – در این مرحله آخر، خروجی در قالب درخت تولید می شود.
اجازه دهید پکیجج NLTK لازم را به شرح زیر وارد کنیم –
|
1 |
import nltk |
حال ، باید جمله را تعریف کنیم. در اینجا ، DT به معنی تعیین کننده است، VBP به معنی فعل ، JJ به معنی صفت، IN به معنای حرف اضافه و NN به معنای اسم است.
|
1 2 |
sentence=[("a","DT"),("clever","JJ"),("fox","NN"),("was","VBP"), ("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")] |
اکنون، ما باید دستور زبان را ارائه دهیم. در اینجا، ما دستور زبان را به صورت بیان منظم ارائه خواهیم داد.
|
1 |
grammar = "NP:{<DT>?<JJ>*<NN>}" |
ما باید تجزیه کننده ای را تعریف کنیم که دستور زبان را تجزیه کند.
|
1 |
parser_chunking = nltk.RegexpParser(grammar) |
تجزیه کننده جمله را به شرح زیر تجزیه می کند –
|
1 |
parser_chunking.parse(sentence) |
بعد، ما باید خروجی بگیریم. خروجی در متغیر ساده ای به نام output_chunk تولید می شود.
|
1 |
Output_chunk = parser_chunking.parse(sentence) |
با اجرای کد زیر، می توانیم خروجی خود را به شکل درخت ترسیم کنیم.
|
1 |
output.draw () |
مدل (Bag of Word (BoW
(Bag of Word (BoW، مدلی در پردازش زبان طبیعی، اساساً برای استخراج ویژگی ها از متن استفاده می شود تا متن بتواند در مدل سازی به گونه ای که در الگوریتم های یادگیری ماشین استفاده می شود.
حال این سوال پیش می آید که چرا ما باید ویژگی ها را از متن استخراج کنیم. به این دلیل است که الگوریتم های یادگیری ماشین نمی توانند با داده های خام کار کنند و آنها به داده های عددی نیاز دارند تا بتوانند اطلاعات معنی دار را از آن استخراج کنند. به تبدیل داده های متنی به داده های عددی، استخراج ویژگی یا رمزگذاری ویژگی گفته می شود.
چگونه کار می کند
این روش بسیار ساده برای استخراج ویژگی ها از متن است. فرض کنید که ما یک سند متنی داریم و می خواهیم آن را به داده های عددی تبدیل کنیم یا بگوییم می خواهیم ویژگی ها را از آن استخراج کنیم سپس اول از همه این مدل واژگان را از کلمات سند استخراج می کند. سپس با استفاده از ماتریس اصطلاحات مدلی، مدلی را ایجاد می کند. به این ترتیب ، BoW سند را فقط به عنوان یک کلمه نشان می دهد. هرگونه اطلاعات در مورد ترتیب یا ساختار کلمات در سند کنار گذاشته می شود.
مفهوم ماتریس اصطلاح سند
الگوریتم BoW با استفاده از ماتریس اصطلاحات سند، مدلی را ایجاد می کند. همانطور که از نام آن پیداست، ماتریس اصطلاح ماتریس تعداد کلمات مختلفی است که در سند رخ می دهد. با کمک این ماتریس می توان سند متن را به صورت ترکیبی وزنی از کلمات مختلف نشان داد. با تنظیم آستانه و انتخاب کلماتی که معنادارتر هستند، می توان یک هیستوگرام از تمام کلمات موجود در اسناد ساخت که می تواند به عنوان بردار ویژگی استفاده شود. در زیر مثالی برای درک مفهوم ماتریس اصطلاحات سند آمده است –
مثال
فرض کنید دو جمله زیر داریم –
جمله 1 – We are using the Bag of Words model.
جمله 2 -Bag of Words model is used for extracting the features.
اکنون ، با در نظر گرفتن این دو جمله، 13 کلمه متمایز زیر را داریم –
- we
- are
- using
- the
- bag
- of
- words
- model
- is
- used
- for
- extracting
- features
اکنون، باید با استفاده از تعداد کلمات در هر جمله ، برای هر جمله هیستوگرام بسازیم –
جمله 1 – [1،1،1،1،1،1،1،1،0،0،0،0،0،0]
جمله 2 – [0،0،0،1،1،1،1،1،1،1،1،1،1،1]
به این ترتیب، ما بردارهای ویژگی را داریم که استخراج شده اند. هر بردار ویژگی 13 بعدی است زیرا 13 کلمه مجزا داریم.
مفهوم آمار
مفهوم آمار (TermFrequency-Inverse Document Frequency (tf-idf نامیده می شود. هر کلمه ای در سند مهم است. این آمار به ما کمک می کند تا اهمیت هر کلمه را درک کنیم.
فرکانس تعداد (tf)
این اندازه گیری میزان دفعات نمایش هر کلمه در یک سند است. با تقسیم تعداد هر کلمه بر تعداد کل کلمات در یک سند مشخص می توان آن را بدست آورد.
فرکانس سند معکوس (idf)
این معیار اندازه گیری منحصر به فرد یک کلمه برای این سند در مجموعه اسناد ارائه شده است. برای محاسبه idf و فرمول برداری از بردار ویژگی متمایز، ما باید وزن کلمات متداول را کاهش دهیم و کلمات کمیاب را وزن کنیم.
ساخت مدل Bag of Words در NLTK
در این بخش، ما مجموعه ای از رشته ها را با استفاده از CountVectorizer برای ایجاد بردارها از این جملات تعریف خواهیم کرد.
|
1 |
from sklearn.feature_extraction.text import CountVectorize |
حال مجموعه جملات را تعریف کنید.
|
1 2 3 4 5 6 7 8 |
Sentences = ['We are using the Bag of Word model', 'Bag of Word model is used for extracting the features.'] vectorizer_count = CountVectorizer() features_text = vectorizer.fit_transform(Sentences).todense() print(vectorizer.vocabulary_) |
برنامه فوق مانند شکل زیر خروجی ایجاد می کند. این نشان می دهد که ما در دو جمله بالا 13 کلمه مشخص داریم
|
1 2 |
{'we': 11, 'are': 0, 'using': 10, 'the': 8, 'bag': 1, 'of': 7, 'word': 12, 'model': 6, 'is': 5, 'used': 9, 'for': 4, 'extracting': 2, 'features': 3} |
اینها بردارهای ویژگی (متن به فرم عددی) هستند که می توانند برای یادگیری ماشین استفاده شوند.
حل مسائل
در این بخش، ما چند مشکل مرتبط را حل خواهیم کرد.
پیش بینی دسته
در مجموعه ای از اسناد، نه تنها کلمات بلکه دسته بندی کلمات نیز مهم است. در کدام دسته از متن یک کلمه خاص قرار می گیرد. به عنوان مثال، ما می خواهیم پیش بینی کنیم که آیا یک جمله داده شده به دسته ایمیل، اخبار، ورزش، کامپیوتر و غیره تعلق دارد. در مثال زیر ، ما می خواهیم از tf-idf برای تنظیم یک بردار ویژگی برای یافتن دسته اسناد استفاده کنیم. ما از داده های 20 مجموعه گروه خبری sklearn استفاده خواهیم کرد.
ما باید پکیج های لازم را وارد کنیم –
|
1 2 3 4 |
from sklearn.datasets import fetch_20newsgroups from sklearn.naive_bayes import MultinomialNB from sklearn.feature_extraction.text import TfidfTransformer from sklearn.feature_extraction.text import CountVectorizer |
نقشه دسته را مشخص کنید. ما از پنج دسته مختلف به نام های دین، خودرو، ورزش، الکترونیک و فضا استفاده می کنیم
|
1 2 |
category_map = {'talk.religion.misc':'Religion','rec.autos''Autos', 'rec.sport.hockey':'Hockey','sci.electronics':'Electronics', 'sci.space': 'Space'} |
مجموعه آموزش را ایجاد کنید –
|
1 2 |
training_data = fetch_20newsgroups(subset = 'train', categories = category_map.keys(), shuffle = True, random_state = 5) |
یک بردار شمارش کننده بسازید و تعداد واژه ها را استخراج کنید –
|
1 2 3 |
vectorizer_count = CountVectorizer() train_tc = vectorizer_count.fit_transform(training_data.data) print("\nDimensions of training data:", train_tc.shape) |
ترانسفورماتور tf-idf به صورت زیر ایجاد می شود –
|
1 2 |
tfidf = TfidfTransformer() train_tfidf = tfidf.fit_transform(train_tc) |
اکنون، داده های تست را تعریف کنید –
|
1 2 3 4 5 6 7 |
input_data = [ 'Discovery was a space shuttle', 'Hindu, Christian, Sikh all are religions', 'We must have to drive safely', 'Puck is a disk made of rubber', 'Television, Microwave, Refrigrated all uses electricity' ] |
داده های فوق به ما کمک می کند تا یک طبقه بندی کننده چند جمله ای ساده لوح بیز را آموزش دهیم –
|
1 |
classifier = MultinomialNB().fit(train_tfidf, training_data.target) |
داده های ورودی را با استفاده از بردار شمارش کننده تغییر دهید –
|
1 |
input_tc = vectorizer_count.transform(input_data) |
اکنون ، ما داده های برداری شده را با استفاده از ترانسفورماتور tfidf تبدیل خواهیم کرد –
|
1 |
input_tfidf = tfidf.transform(input_tc) |
ما دسته بندی های خروجی را پیش بینی خواهیم کرد –
|
1 |
predictions = classifier.predict(input_tfidf) |
خروجی به صورت زیر تولید می شود –
|
1 2 3 |
for sent, category in zip(input_data, predictions): print('\nInput Data:', sent, '\n Category:', \ category_map[training_data.target_names[category]]) |
خروجی زیر را ایجاد می کند –
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
Dimensions of training data: (2755, 39297) Input Data: Discovery was a space shuttle Category: Space Input Data: Hindu, Christian, Sikh all are religions Category: Religion Input Data: We must have to drive safely Category: Autos Input Data: Puck is a disk made of rubber Category: Hockey Input Data: Television, Microwave, Refrigrated all uses electricity Category: Electronics |
جنسیت یاب
در این بیان مسئله، یک طبقه بندی آموزش داده می شود تا جنسیت (زن یا مرد) را با ارائه نام پیدا کند. برای ساخت بردار ویژگی و آموزش طبقه بندی نیاز به استفاده از روش ابتکاری داریم. ما از داده های برچسب خورده در پکیج scikit-learn استفاده خواهیم کرد. در زیر کد پایتون برای ساخت یک جنسیت یاب وجود دارد –
اجازه دهید پکیج های لازم را وارد کنیم –
|
1 2 3 4 5 |
import random from nltk import NaiveBayesClassifier from nltk.classify import accuracy as nltk_accuracy from nltk.corpus import names |
حال باید حرف آخر N را از کلمه ورودی استخراج کنیم. این حروف به عنوان ویژگی عمل می کنند
|
1 2 3 4 5 |
def extract_features(word, N = 2): last_n_letters = word[-N:] return {'feature': last_n_letters.lower()} if __name__=='__main__': |
داده های آموزش را با استفاده از نام های دارای برچسب (مرد و زن) موجود در NLTK ایجاد کنید –
|
1 2 3 4 5 6 |
male_list = [(name, 'male') for name in names.words('male.txt')] female_list = [(name, 'female') for name in names.words('female.txt')] data = (male_list + female_list) random.seed(5) random.shuffle(data) |
اکنون، داده های تست به شرح زیر ایجاد می شوند –
|
1 |
namesInput = ['Rajesh', 'Gaurav', 'Swati', 'Shubha'] |
تعداد نمونه های مورد استفاده برای آموزش و تست را با کد زیر تعریف کنید
|
1 |
train_sample = int(0.8 * len(data)) |
اکنون، ما باید با طول های مختلف تکرار کنیم تا بتوان دقت را مقایسه کرد –
|
1 2 3 4 5 6 |
for i in range(1, 6): print('\nNumber of end letters:', i) features = [(extract_features(n, i), gender) for (n, gender) in data] train_data, test_data = features[:train_sample], features[train_sample:] classifier = NaiveBayesClassifier.train(train_data) |
دقت طبقه بندی را می توان به شرح زیر محاسبه کرد –
|
1 2 |
accuracy_classifier = round(100 * nltk_accuracy(classifier, test_data), 2) print('Accuracy = ' + str(accuracy_classifier) + '%') |
اکنون می توانیم خروجی را پیش بینی کنیم –
|
1 2 |
for name in namesInput: print(name, '==>', classifier.classify(extract_features(name, i))) |
برنامه فوق خروجی زیر را ایجاد می کند –
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
Number of end letters: 1 Accuracy = 74.7% Rajesh -> female Gaurav -> male Swati -> female Shubha -> female Number of end letters: 2 Accuracy = 78.79% Rajesh -> male Gaurav -> male Swati -> female Shubha -> female Number of end letters: 3 Accuracy = 77.22% Rajesh -> male Gaurav -> female Swati -> female Shubha -> female Number of end letters: 4 Accuracy = 69.98% Rajesh -> female Gaurav -> female Swati -> female Shubha -> female Number of end letters: 5 Accuracy = 64.63% Rajesh -> female Gaurav -> female Swati -> female Shubha -> female |
در خروجی فوق، می بینیم که دقت در حداکثر تعداد حروف انتهایی دو است و با افزایش تعداد حروف انتهایی، در حال کاهش است.
مدل سازی موضوع: شناسایی الگوها در داده های متنی
ما می دانیم که به طور کلی اسناد در موضوعات دسته بندی می شوند. گاهی لازم است الگوهای متن را مشخص کنیم که با موضوع خاصی مطابقت دارند. تکنیک انجام این کار مدل سازی موضوع نامیده می شود. به عبارت دیگر، می توان گفت که مدل سازی موضوع تکنیکی برای کشف مضامین انتزاعی یا ساختار پنهان در مجموعه اسناد ارائه شده است.
ما می توانیم از تکنیک مدل سازی موضوع در سناریوهای زیر استفاده کنیم –
طبقه بندی متن
با کمک مدلسازی موضوع می توان طبقه بندی را بهبود بخشید زیرا کلمات مشابه را به جای استفاده از هر کلمه جداگانه به عنوان یک ویژگی، با هم گروه می کند.
سیستم پیشنهادی
با کمک مدلسازی مبحث، می توانیم سیستم های پیشنهادی را با استفاده از اقدامات تشابه ایجاد کنیم.
الگوریتم های مدل سازی موضوع
مدلسازی مبحث را می توان با استفاده از الگوریتم ها پیاده سازی کرد. الگوریتم ها به شرح زیر است –
تخصیص پنهان دیریکله (LDA)
این الگوریتم محبوب ترین مدل سازی موضوع است. از مدل های گرافیکی احتمالی برای پیاده سازی مدل سازی موضوع استفاده می کند. برای استفاده از الگوریتم LDA باید بسته gensim را در پایتون وارد کنیم.
تحلیل معنایی نهفته (LDA) یا نمایه سازی معنایی نهفته (LSI)
این الگوریتم بر اساس جبر خطی است. اساساً از مفهوم SVD (تجزیه ارزش واحد) در ماتریس اصطلاح سند استفاده می کند.
فاکتورگیری نامنفی ماتریس(NMF)
این نیز بر اساس جبر خطی است.
تمام الگوریتم های ذکر شده در بالا برای مدل سازی موضوع دارای تعداد موضوعات به عنوان یک پارامتر ، Document-Word Matrix به عنوان ورودی و (WTM (Word Topic Matrix و (TDM (Topic Document Matrix به عنوان خروجی هستند.
لیست جلسات قبل آموزش هوش مصنوعی با برنامه نویسی پایتون
- آموزش هوش مصنوعی با برنامه نویسی پایتون – مفهوم کلی
- شروع آموزش هوش مصنوعی با برنامه نویسی پایتون
- یادگیری ماشین در هوش مصنوعی با برنامه نویسی پایتون
- هوش مصنوعی با برنامه نویسی پایتون، آماده سازی داده ها
- هوش مصنوعی با پایتون، یادگیری نظارت شده و طبقه بندی
- هوش مصنوعی با برنامه نویسی پایتون – یادگیری تحت نظارت: رگرسیون
- هوش مصنوعی با برنامه نویسی پایتون – برنامه نویسی منطقی
- هوش مصنوعی با پایتون – یادگیری بدون نظارت: خوشه بندی
- هوش مصنوعی با پایتون – پردازش زبان طبیعی



.svg)
دیدگاه شما