
هوش مصنوعی با پایتون – یادگیری بدون نظارت: خوشه بندی

هوش مصنوعی با پایتون – یادگیری بدون نظارت: خوشه بندی
در این درس از مجموعه آموزش برنامه نویسی سایت سورس باران، ما به هوش مصنوعی با پایتون – یادگیری بدون نظارت: خوشه بندی خواهیم پرداخت.
الگوریتم های یادگیری ماشین بدون نظارت هیچ ناظری برای ارائه هر نوع راهنمایی ندارند. به همین دلیل است که آنها با آنچه هوش مصنوعی واقعی می نامند بسیار همسو هستند.
پیشنهاد ویژه : پکیج آموزش طراحی وب سایت با پایتون و جنگو
در یادگیری بدون نظارت، هیچ پاسخ صحیحی و هیچ معلمی برای راهنمایی وجود ندارد. الگوریتم ها برای یادگیری باید الگوی جالب توجه در داده ها را کشف کنند.
خوشه بندی چیست؟
اساساً، این یک نوع روش یادگیری بدون نظارت و یک روش معمول برای تجزیه و تحلیل داده های آماری است که در بسیاری از زمینه ها استفاده می شود. خوشه بندی عمدتاً وظیفه ای است برای تقسیم مجموعه مشاهدات به زیرمجموعه هایی که خوشه نامیده می شوند، به گونه ای که مشاهدات در یک خوشه به یک معنا مشابه هستند و با مشاهدات خوشه های دیگر شباهت ندارند. با کلمات ساده می توان گفت که هدف اصلی خوشه بندی گروه بندی داده ها بر اساس شباهت و عدم تشابه است.
به عنوان مثال، نمودار زیر نوع مشابهی از داده ها را در خوشه های مختلف نشان می دهد –
الگوریتم های خوشه بندی داده ها
در زیر چند الگوریتم معمول برای خوشه بندی داده ها آورده شده است –
الگوریتم K-Means
الگوریتم خوشه بندی K-mean یکی از الگوریتم های معروف برای خوشه بندی داده ها است. ما باید فرض کنیم که تعداد خوشه ها از قبل مشخص هستند. به این خوشه بندی تخت نیز گفته می شود. این یک الگوریتم خوشه ای تکراری است. مراحل داده شده در زیر برای این الگوریتم باید دنبال شود –
مرحله 1 – ما باید تعداد زیر گروه های K مورد نظر را مشخص کنیم.
مرحله 2 – تعداد خوشه ها و هر نقطه داده را که به طور تصادفی به یک خوشه اختصاص داده را درست کنید. یا به عبارت دیگر ما باید اطلاعات خود را بر اساس تعداد خوشه ها طبقه بندی کنیم.
در این مرحله، باید centroids خوشه ای محاسبه شود.
از آنجا که این یک الگوریتم تکرار شونده است، ما باید مکان های K centroids را با هر تکرار به روز کنیم تا زمانی که optima جهانی را پیدا کنیم یا به عبارت دیگر centroids در مکان های مطلوب خود برسند.
کد زیر به پیاده سازی الگوریتم خوشه بندی K-means در پایتون کمک می کند. ما قصد داریم از ماژول Scikit-learn استفاده کنیم.
اجازه دهید پکیج های لازم را وارد کنیم –
|
1 2 3 4 |
import matplotlib.pyplot as plt import seaborn as sns; sns.set() import numpy as np from sklearn.cluster import KMeans |
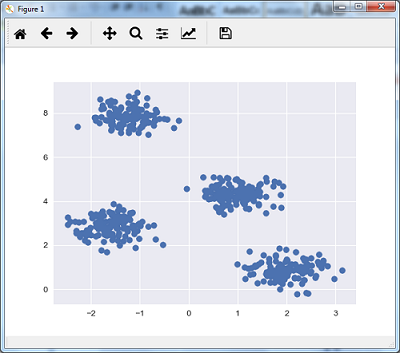
کد زیر با استفاده از make_blob از پکیج sklearn.dataset به تولید مجموعه داده دو بعدی شامل چهار حباب کمک می کند.
|
1 2 3 4 |
rom sklearn.datasets.samples_generator import make_blobs X, y_true = make_blobs(n_samples = 500, centers = 4, cluster_std = 0.40, random_state = 0) |
ما می توانیم مجموعه داده را با استفاده از کد زیر تجسم کنیم –
|
1 2 |
plt.scatter(X[:, 0], X[:, 1], s = 50); plt.show() |
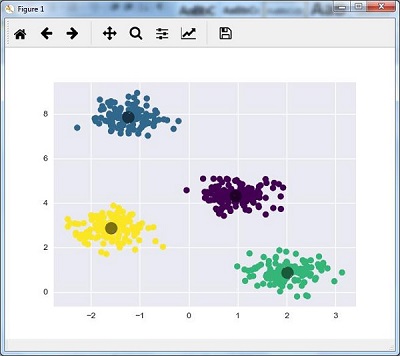
در اینجا، ما در حال آماده سازی kmeans برای الگوریتم KMeans هستیم، با پارامتر مورد نیاز چند خوشه (n_clusters).
|
1 |
kmeans = KMeans (n_clusters = 4) |
ما باید مدل K-means را با داده های ورودی آموزش دهیم.
|
1 2 3 4 5 |
kmeans.fit(X) y_kmeans = kmeans.predict(X) plt.scatter(X[:, 0], X[:, 1], c = y_kmeans, s = 50, cmap = 'viridis') centers = kmeans.cluster_centers_ |
کدی که در زیر آورده شده است به ما کمک می کند تا یافته های دستگاه را بر اساس داده های خود و متناسب با تعداد خوشه هایی که باید پیدا کنیم، ترسیم و تجسم کنیم.
|
1 2 |
plt.scatter(centers[:, 0], centers[:, 1], c = 'black', s = 200, alpha = 0.5); plt.show() |
الگوریتم تغییر میانگین
این الگوریتم خوشه بندی محبوب و قدرتمند دیگری است که در یادگیری بدون نظارت استفاده می شود. هیچ فرضی نمی دهد از این رو الگوریتمی غیر پارامتری است. همچنین به آن خوشه بندی سلسله مراتبی یا آنالیز خوشه تغییر میانگین گفته می شود. موارد زیر مراحل کلی این الگوریتم است –
- اول از همه، ما باید با نقاط داده های اختصاص داده شده به یک خوشه برای خود شروع کنیم.
- مرحله بعد، این محاسبه centroids و به روز رسانی محل centroids جدید.
- با تکرار این فرآیند، قله خوشه را نزدیکتر می کنیم یعنی به سمت منطقه با تراکم بالاتر می رویم.
- این الگوریتم در مرحله ای متوقف می شود که دیگر centroids حرکت نمی کنند.
با کمک کد زیر ما در حال اجرای الگوریتم خوشه بندی میانگین تغییر در پایتون هستیم. ما قصد داریم از ماژول Scikit-learn استفاده کنیم.
اجازه دهید پکیج های لازم را وارد کنیم –
|
1 2 3 4 5 |
import numpy as np from sklearn.cluster import MeanShift import matplotlib.pyplot as plt from matplotlib import style style.use("ggplot") |
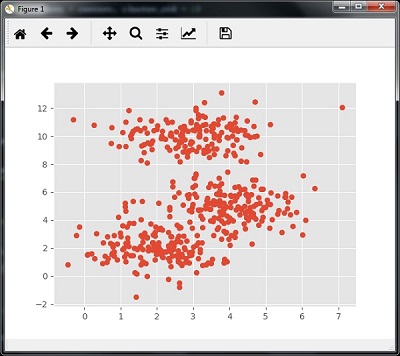
کد زیر با استفاده از make_blob از پکیج sklearn.dataset به تولید مجموعه داده دو بعدی شامل چهار حباب کمک می کند.
|
1 |
from sklearn.datasets.samples_generator import make_blobs |
ما می توانیم مجموعه داده را با کد زیر تجسم کنیم
|
1 2 3 4 |
centers = [[2,2],[4,5],[3,10]] X, _ = make_blobs(n_samples = 500, centers = centers, cluster_std = 1) plt.scatter(X[:,0],X[:,1]) plt.show() |
اکنون، ما باید مدل خوشه Mean Shift را با داده های ورودی آموزش دهیم.
|
1 2 3 4 |
ms = MeanShift() ms.fit(X) labels = ms.labels_ cluster_centers = ms.cluster_centers_ |
کد زیر مراکز خوشه و تعداد خوشه مورد انتظار را طبق داده های ورودی چاپ می کند –
|
1 2 3 4 5 6 |
print(cluster_centers) n_clusters_ = len(np.unique(labels)) print("Estimated clusters:", n_clusters_) [[ 3.23005036 3.84771893] [ 3.02057451 9.88928991]] Estimated clusters: 2 |
کدی که در زیر آورده شده است به شما کمک می کند تا یافته های دستگاه را بر اساس داده های ما و تجهیزات را با توجه به تعداد خوشه هایی که باید پیدا کنید، تجسم کنید.
|
1 2 3 4 5 6 |
colors = 10*['r.','g.','b.','c.','k.','y.','m.'] for i in range(len(X)): plt.plot(X[i][0], X[i][1], colors[labels[i]], markersize = 10) plt.scatter(cluster_centers[:,0],cluster_centers[:,1], marker = "x",color = 'k', s = 150, linewidths = 5, zorder = 10) plt.show() |
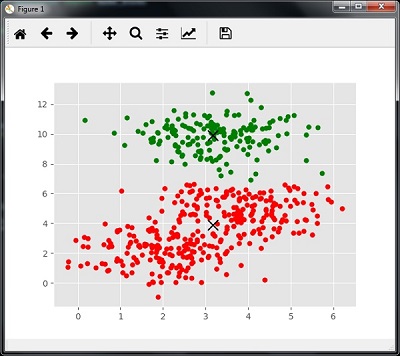
اندازه گیری عملکرد خوشه بندی
داده های دنیای واقعی به طور طبیعی به تعداد خوشه های متمایز سازماندهی نشده است. به همین دلیل، تجسم و استنتاج آسان نیست. به همین دلیل است که باید عملکرد خوشه بندی و همچنین کیفیت آن را بسنجیم. می توان آن را با کمک تجزیه و تحلیل شبح انجام داد.
آنالیز Silhouette
از این روش می توان با اندازه گیری فاصله بین خوشه ها، کیفیت خوشه بندی را بررسی کرد. اساساً، این یک روش برای ارزیابی پارامترها مانند تعداد خوشه ها با دادن نمره Silhouette فراهم می کند. این نمره معیاری است که میزان نزدیک بودن هر نقطه در یک خوشه به نقاط خوشه های همسایه را اندازه گیری می کند.
آنالیز نمرات Silhouette
دامنه نمره [1 ، 1-] است. در زیر تجزیه و تحلیل این نمره –
- نمره 1+ – نمره نزدیک 1+ نشان می دهد که نمونه از خوشه همسایه فاصله دارد.
- نمره 0 – نمره 0 نشان می دهد که نمونه در مرز تصمیم گیری بین دو خوشه همسایه قرار دارد یا بسیار نزدیک است.
- نمره 1- – نمره منفی نشان می دهد که نمونه ها به خوشه های اشتباه تقسیم شده اند.
محاسبه نمرات Silhouette
در این بخش، ما نحوه محاسبه نمره Silhouette را یاد خواهیم گرفت.
نمره شبح را می توان با استفاده از فرمول زیر محاسبه کرد –
نمره شباهت $ $ = \ frac {\ چپ (p-q \ راست)} {حداکثر \ چپ (p ، q \ راست)} $ $
در اینجا ، 𝑝 میانگین فاصله تا نقاط نزدیکترین خوشه است که نقطه داده بخشی از آن نیست. و ، 𝑞 میانگین فاصله درون خوشه تا تمام نقاط خوشه خود است.
برای یافتن تعداد بهینه خوشه ها ، باید الگوریتم خوشه بندی را مجدداً با وارد کردن ماژول متریک از بسته sklearn اجرا کنیم. در مثال زیر، الگوریتم خوشه بندی K-means را برای یافتن تعداد بهینه خوشه ها اجرا خواهیم کرد –
همانطور که نشان داده شده پکیج های لازم را وارد کنید:
|
1 2 3 4 |
import matplotlib.pyplot as plt import seaborn as sns; sns.set() import numpy as np from sklearn.cluster import KMeans |
با کمک کد زیر، با استفاده از make_blob از بسته sklearn.dataset ، مجموعه داده ای دو بعدی را که شامل چهار blobs است، تولید خواهیم کرد.
|
1 2 3 |
from sklearn.datasets.samples_generator import make_blobs X, y_true = make_blobs(n_samples = 500, centers = 4, cluster_std = 0.40, random_state = 0) |
متغیرها را همانطور که نشان داده شده اولیه کنید
|
1 2 |
scores = [] values = np.arange(2, 10) |
ما باید مدل K-means را از طریق تمام مقادیر تکرار کنیم و همچنین باید آن را با داده های ورودی آموزش دهیم.
|
1 2 3 |
for num_clusters in values: kmeans = KMeans(init = 'k-means++', n_clusters = num_clusters, n_init = 10) kmeans.fit(X) |
اکنون، با استفاده از معیار فاصله اقلیدسی، نمره silhouette را برای مدل خوشه بندی فعلی تخمین بزنید –
|
1 2 |
score = metrics.silhouette_score(X, kmeans.labels_, metric = 'euclidean', sample_size = len(X)) |
کد زیر به نمایش تعداد خوشه ها و همچنین نمره silhouette کمک می کند.
|
1 2 3 |
print("\nNumber of clusters =", num_clusters) print("Silhouette score =", score) scores.append(score) |
شما خروجی زیر را دریافت خواهید کرد –
|
1 2 3 4 5 |
Number of clusters = 9 Silhouette score = 0.340391138371 num_clusters = np.argmax(scores) + values[0] print('\nOptimal number of clusters =', num_clusters) |
اکنون، خروجی تعداد بهینه خوشه ها به شرح زیر است:
|
1 |
Optimal number of clusters = 2 |
یافتن نزدیکترین همسایگان
اگر می خواهیم سیستم های توصیه کننده ای مانند سیستم پیشنهاد دهنده فیلم بسازیم، باید مفهوم یافتن نزدیکترین همسایگان را درک کنیم. به این دلیل است که سیستم پیشنهاد دهنده از مفهوم نزدیکترین همسایگان استفاده می کند.
مفهوم یافتن نزدیکترین همسایگان ممکن است به عنوان فرآیند یافتن نزدیکترین نقطه به نقطه ورودی از مجموعه دیتای داده شده تعریف شود. کاربرد اصلی این الگوریتم KNN) K-نزدیکترین همسایگان) ساخت سیستم های طبقه بندی است که یک نقطه داده را در نزدیکی نقطه داده ورودی به کلاسهای مختلف طبقه بندی می کند.
کد پایتون که در زیر آورده شده است در یافتن نزدیکترین همسایگان K مجموعه داده داده شده کمک می کند –
پکیج های لازم را مانند تصویر زیر وارد کنید. در اینجا ، ما از ماژول NearestNeighbours موجود در پکیج sklearn استفاده می کنیم
|
1 2 3 |
import numpy as np import matplotlib.pyplot as plt from sklearn.neighbors import NearestNeighbors |
اجازه دهید اکنون داده های ورودی را تعریف کنیم –
|
1 2 |
A = np.array([[3.1, 2.3], [2.3, 4.2], [3.9, 3.5], [3.7, 6.4], [4.8, 1.9], [8.3, 3.1], [5.2, 7.5], [4.8, 4.7], [3.5, 5.1], [4.4, 2.9],]) |
اکنون ، باید نزدیکترین همسایگان را تعریف کنیم –
|
1 |
k = 3 |
ما همچنین باید داده های آزمایشی که نزدیکترین همسایگان از آنها پیدا می شود را ارائه دهیم –
|
1 |
test_data = [3.3 ، 2.9] |
کد زیر می تواند داده های ورودی تعریف شده توسط ما را تجسم و ترسیم کند –
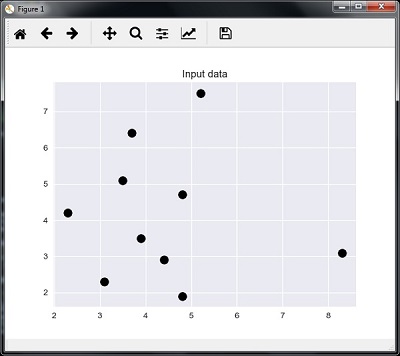
اکنون، ما باید نزدیکترین همسایه K را بسازیم. این شی نیز باید آموزش ببیند
|
1 2 |
knn_model = NearestNeighbors(n_neighbors = k, algorithm = 'auto').fit(X) distances, indices = knn_model.kneighbors([test_data]) |
اکنون می توانیم نزدیکترین همسایگان K را به صورت زیر چاپ کنیم
|
1 2 3 |
print("\nK Nearest Neighbors:") for rank, index in enumerate(indices[0][:k], start = 1): print(str(rank) + " is", A[index]) |
ما می توانیم نزدیکترین همسایگان را به همراه نقطه داده آزمون تست کنیم
|
1 2 3 4 5 6 7 8 |
plt.figure() plt.title('Nearest neighbors') plt.scatter(A[:, 0], X[:, 1], marker = 'o', s = 100, color = 'k') plt.scatter(A[indices][0][:][:, 0], A[indices][0][:][:, 1], marker = 'o', s = 250, color = 'k', facecolors = 'none') plt.scatter(test_data[0], test_data[1], marker = 'x', s = 100, color = 'k') plt.show() |
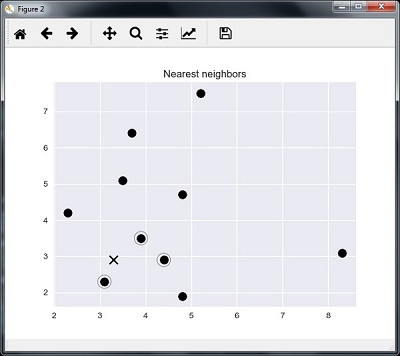
خروجی
K نزدیکترین همسایگان
|
1 2 3 |
1 is [ 3.1 2.3] 2 is [ 3.9 3.5] 3 is [ 4.4 2.9] |
K- طبقه بندی نزدیکترین همسایگان
(طبقه بندی K-Nearest Neighbours (KNN یک مدل طبقه بندی است که از الگوریتم نزدیکترین همسایگان برای طبقه بندی یک دیتای داده شده استفاده می کند. ما الگوریتم KNN را در بخش آخر پیاده سازی کرده ایم ، اکنون می خواهیم طبقه بندی کننده KNN را با استفاده از آن الگوریتم بسازیم.
مفهوم طبقه بندی KNN
مفهوم اساسی طبقه بندی نزدیکترین همسایه K یافتن یک عدد از پیش تعریف شده است، به عنوان مثال “k” – نمونه های آموزشی نزدیکترین فاصله به یک نمونه جدید، که باید طبقه بندی شود. نمونه های جدید برچسب خود را از همسایگان دریافت می کنند. طبقه بندی کننده های KNN دارای یک کاربر ثابت برای تعداد همسایگان تعیین شده هستند. برای مسافت، فاصله استاندارد اقلیدسی رایج ترین انتخاب است.
طبقه بندی KNN به جای ایجاد قوانینی برای یادگیری، مستقیماً روی نمونه های آموخته شده کار می کند. الگوریتم KNN از ساده ترین الگوریتم های یادگیری ماشین است. در تعداد زیادی از مشکلات طبقه بندی و رگرسیون، به عنوان مثال، شناسایی شخصیت یا تجزیه و تحلیل تصویر، کاملاً موفق بوده است.
مثال
ما در حال ساخت یک طبقه بندی KNN برای شناسایی ارقام هستیم. برای این، ما از مجموعه داده MNIST استفاده خواهیم کرد. ما این کد را در Jupyter Notebook می نویسیم.
پکیج های لازم را مانند تصویر زیر وارد کنید.
در اینجا ما از ماژول KNeighborsClassifier موجود در پکیج sklearn.neighbours استفاده می کنیم
|
1 2 3 4 5 6 7 |
from sklearn.datasets import * import pandas as pd %matplotlib inline from sklearn.neighbors import KNeighborsClassifier import matplotlib.pyplot as plt import numpy as np |
کد زیر تصویر عدد را برای تأیید اینکه چه تصویری را باید آزمایش کنیم نمایش می دهد –
|
1 2 3 |
def Image_display(i): plt.imshow(digit['images'][i],cmap = 'Greys_r') plt.show() |
اکنون، ما باید مجموعه داده MNIST را بارگیری کنیم. در واقع 1797 تصویر وجود دارد اما ما از 1600 تصویر اول به عنوان نمونه آموزش استفاده می کنیم و 197 تصویر باقیمانده را برای تست نگهداری می کنیم.
|
1 2 |
digit = load_digits() digit_d = pd.DataFrame(digit['data'][0:1600]) |
اکنون، با نمایش تصاویر می توانیم خروجی را به صورت زیر مشاهده کنیم –
|
1 |
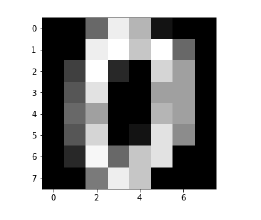
Image_display(0) |
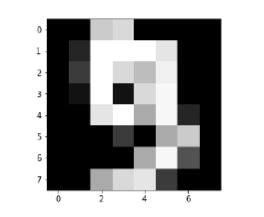
(Image_display(0
تصویر 0 به شرح زیر نمایش داده می شود:
(Image_display(9
تصویر 9 به شرح زیر نمایش داده می شود:
()digit.keys
اکنون، ما باید مجموعه داده های آموزش و تست را ایجاد کنیم و مجموعه داده های آزمایش را به طبقه بندی کننده های KNN ارائه دهیم.
|
1 2 3 4 |
train_x = digit['data'][:1600] train_y = digit['target'][:1600] KNN = KNeighborsClassifier(20) KNN.fit(train_x,train_y) |
خروجی زیر سازنده طبقه بندی K نزدیکترین همسایه را ایجاد می کند –
|
1 2 3 |
KNeighborsClassifier(algorithm = 'auto', leaf_size = 30, metric = 'minkowski', metric_params = None, n_jobs = 1, n_neighbors = 20, p = 2, weights = 'uniform') |
ما باید نمونه آزمایشی را با ارائه هر تعداد دلخواه بیشتر از 1600، که نمونه های آموزشی بود، ایجاد کنیم.
|
1 2 3 |
test = np.array(digit['data'][1725]) test1 = test.reshape(1,-1) Image_display(1725) |
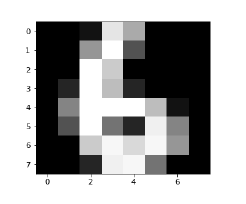
(Image_display(6
تصویر 6 به شرح زیر نمایش داده می شود:
اکنون داده های تست را به شرح زیر پیش بینی خواهیم کرد –
|
1 |
KNN.predict(test1) |
کد فوق خروجی زیر را ایجاد می کند –
|
1 |
array([6]) |
اکنون، موارد زیر را در نظر بگیرید –
|
1 |
digit['target_names'] |
کد فوق خروجی زیر را ایجاد می کند –
|
1 |
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) |
لیست جلسات قبل آموزش هوش مصنوعی با برنامه نویسی پایتون
- آموزش هوش مصنوعی با برنامه نویسی پایتون – مفهوم کلی
- شروع آموزش هوش مصنوعی با برنامه نویسی پایتون
- یادگیری ماشین در هوش مصنوعی با برنامه نویسی پایتون
- هوش مصنوعی با برنامه نویسی پایتون، آماده سازی داده ها
- هوش مصنوعی با پایتون، یادگیری نظارت شده و طبقه بندی
- هوش مصنوعی با برنامه نویسی پایتون – یادگیری تحت نظارت: رگرسیون
- هوش مصنوعی با برنامه نویسی پایتون – برنامه نویسی منطقی
یک دیدگاه
-
مجتبی
5 سال پیشسلام من میخواستم یک متغیر تعریف کنم مانندی اینa=’bookو میخوام بدونم که این aاز لحاظ گرامر چه نوع است یعنی فعل است اسم است صفت است یا دیگر
حالا چه نوع کود بنویسم



.svg)
دیدگاه شما