
آموزش جنگل تصادفی در یادگیری ماشین با پایتون

آموزش جنگل تصادفی در یادگیری ماشین با پایتون
در این درس از مجموعه آموزش برنامه نویسی سایت سورس باران، به آموزش جنگل تصادفی در یادگیری ماشین با پایتون خواهیم پرداخت.
پیشنهاد ویژه : آموزش طراحی وب سایت با پایتون
معرفی جنگل تصادفی در یادگیری ماشین با پایتون
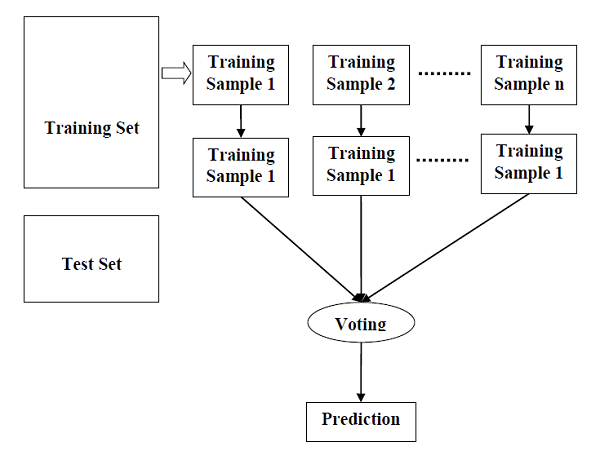
جنگل تصادفی یک الگوریتم یادگیری تحت نظارت است که هم برای طبقه بندی و هم برای رگرسیون استفاده می شود. اما با این حال ، عمدتا برای مشکلات طبقه بندی استفاده می شود. همانطور که می دانیم یک جنگل از درختان تشکیل شده است و تعداد بیشتر درختان به معنای جنگل مقاوم تر است. به همین ترتیب، الگوریتم جنگل تصادفی، درختان تصمیم گیری را روی نمونه های داده ایجاد می کند و سپس پیش بینی را از هر یک از آنها می گیرد و در نهایت با استفاده از رأی گیری بهترین راه حل را انتخاب می کند. این یک روش گروهی است که از یک درخت تصمیم گیری بهتر است زیرا با میانگین گیری از نتیجه ، بیش از حد مناسب را کاهش می دهد.
کار الگوریتم جنگل تصادفی
ما می توانیم کار الگوریتم جنگل تصادفی را با کمک مراحل زیر درک کنیم –
- مرحله 1 – ابتدا با انتخاب نمونه های تصادفی از یک مجموعه داده مشخص شروع کنید.
- مرحله 2 – بعد، این الگوریتم برای هر نمونه یک درخت تصمیم گیری می کند. سپس نتیجه پیش بینی را از هر درخت تصمیم به دست می آورد.
- مرحله 3 – در این مرحله، رای گیری برای هر نتیجه پیش بینی شده انجام می شود.
- مرحله 4 – در آخر بیشترین نتیجه پیش بینی را به عنوان نتیجه پیش بینی نهایی انتخاب کنید.
نمودار زیر عملکرد آن را نشان می دهد –
پیاده سازی در پایتون
ابتدا با وارد کردن بسته های لازم پایتون شروع کنید –
|
1 2 3 |
import numpy as np import matplotlib.pyplot as plt import pandas as pd |
بعد ، مجموعه داده iris را از لینک وب خود به شرح زیر بارگیری کنید –
|
1 |
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data" |
در مرحله بعد، باید نام ستون ها را به شرح زیر به مجموعه داده اختصاص دهیم –
|
1 |
headernames = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class'] |
اکنون ، ما باید مجموعه داده ها را برای pandas dataframe به شرح زیر بخوانیم –
|
1 2 |
dataset = pd.read_csv(path, names=headernames) dataset.head() |
| sepal-length | sepal-width | petal-length | petal-width | Class | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
پیش پردازش داده ها با کمک خطوط زیر انجام می شود –
|
1 2 |
X = dataset.iloc[:, :-1].values y = dataset.iloc[:, 4].values |
بعد ، ما داده ها را به تقسیم قطار و آزمون تقسیم می کنیم. کد زیر مجموعه داده ها را به 70٪ داده های آموزشی و 30٪ داده های آزمایش تقسیم می کند –
|
1 2 |
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30) |
بعد ، مدل را با کمک کلاس RandomForestClassifier از sklearn به شرح زیر آموزش دهید –
|
1 2 3 |
from sklearn.ensemble import RandomForestClassifier classifier = RandomForestClassifier(n_estimators=50) classifier.fit(X_train, y_train) |
سرانجام ، ما باید پیش بینی کنیم. این را می توان با کمک اسکریپت زیر انجام داد –
|
1 |
y_pred = classifier.predict(X_test) |
بعد ، نتایج را به شرح زیر چاپ کنید –
|
1 2 3 4 5 6 7 8 9 |
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score result = confusion_matrix(y_test, y_pred) print("Confusion Matrix:") print(result) result1 = classification_report(y_test, y_pred) print("Classification Report:",) print (result1) result2 = accuracy_score(y_test,y_pred) print("Accuracy:",result2) |
خروجی
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
Confusion Matrix: [ [14 0 0] [ 0 18 1] [ 0 0 12] ] Classification Report: precision recall f1-score support Iris-setosa 1.00 1.00 1.00 14 Iris-versicolor 1.00 0.95 0.97 19 Iris-virginica 0.92 1.00 0.96 12 micro avg 0.98 0.98 0.98 45 macro avg 0.97 0.98 0.98 45 weighted avg 0.98 0.98 0.98 45 Accuracy: 0.9777777777777777 |
جوانب مثبت و منفی جنگل تصادفی
جوانب مثبت
موارد زیر مزایای الگوریتم جنگل تصادفی است –
- با میانگین گیری یا ترکیب نتایج حاصل از درختهای تصمیم مختلف، بر مشکل تجهیزات اضافی غلبه می کند.
- جنگل های تصادفی برای طیف وسیعی از داده ها از یک درخت تصمیم گیری خوب کار می کنند.
- واریانس جنگل تصادفی کمتر از درخت تک تصمیم است.
- جنگل های تصادفی بسیار انعطاف پذیر و دارای دقت بسیار بالایی هستند.
- مقیاس گذاری داده ها در الگوریتم جنگل تصادفی نیاز ندارد. این دقت خوب را حتی پس از ارائه داده بدون مقیاس گذاری حفظ می کند.
- مقیاس گذاری داده ها در الگوریتم جنگل تصادفی نیاز ندارد. این دقت خوب را حتی پس از ارائه داده بدون مقیاس گذاری حفظ می کند.
جوانب منفی
موارد زیر معایب الگوریتم جنگل تصادفی است –
- پیچیدگی اصلی ترین عیب الگوریتم های جنگل تصادفی است.
- ساخت جنگل های تصادفی بسیار دشوارتر و زمانبرتر از درختان تصمیم گیر است.
- برای اجرای الگوریتم جنگل تصادفی به منابع محاسباتی بیشتری نیاز است.
- در مواردی که مجموعه بزرگی از درختان تصمیم گیری داشته باشیم، از شهود کمتری برخوردار است.
- روند پیش بینی با استفاده از جنگل های تصادفی در مقایسه با الگوریتم های دیگر بسیار وقت گیر است.
لیست جلسات قبل آموزش یادگیری ماشین با پایتون
- آموزش یادگیری ماشین با پایتون
- مبانی یادگیری ماشین با پایتون
- آموزش اکوسیستم یادگیری ماشین با پایتون
- آموزش متدها در یادگیری ماشین با پایتون
- آموزش بارگیری داده ها برای پروژه های یادگیری ماشین
- آموزش درک داده ها با آمار در یادگیری ماشین
- آموزش آماده سازی داده ها در یادگیری ماشین با پایتون
- آموزش انتخاب ویژگی داده ها در یادگیری ماشین با پایتون
- آموزش طبقه بندی در یادگیری ماشین با پایتون
- آموزش رگرسیون لجستیک در یادگیری ماشین با پایتون
- آموزش ماشین بردار پشتیبان در یادگیری ماشین با پایتون
- آموزش درخت تصمیم در یادگیری ماشین با پایتون
- آموزش Naïve Bayes در یادگیری ماشین با پایتون
یک دیدگاه
-
مهدی
3 سال پیشکوتاه و موثر
سپاس فراوان از اشتراک گذاریتون و خسته نباشید.



.svg)
دیدگاه شما