
هوش مصنوعی با پایتون – تجزیه و تحلیل داده های سری زمانی

هوش مصنوعی با پایتون – تجزیه و تحلیل داده های سری زمانی
پیش بینی مورد بعدی در یک توالی ورودی مشخص، مفهوم مهم دیگری در یادگیری ماشین است. در این درس از مجموعه آموزش برنامه نویسی سایت سورس باران، به شما توضیح مفصلی در مورد تجزیه و تحلیل داده های سری زمانی می دهد.
پیشنهاد ویژه : آموزش طراحی سایت با پایتون
مقدمه
منظور از داده های سری زمانی، داده هایی است که در یک سری از بازه های زمانی خاص قرار دارد. اگر می خواهیم پیش بینی توالی را در یادگیری ماشین ایجاد کنیم، پس باید با داده ها و زمان متوالی کنار بیاییم. داده های سری چکیده ای از داده های متوالی است. ترتیب داده ها از ویژگی های مهم داده های ترتیبی است.
مفهوم کلی تجزیه و تحلیل توالی یا تجزیه و تحلیل سری زمانی
تجزیه و تحلیل توالی یا تجزیه و تحلیل سری زمانی است که برای پیش بینی بعدی در یک توالی ورودی داده شده بر اساس قبلی مشاهده شده است. پیش بینی می تواند در مورد موارد بعدی باشد: نماد، عدد، آب و هوای روز بعد، ترم بعدی در سخنرانی و غیره
مثال
برای درک پیش بینی توالی مثال زیر را در نظر بگیرید. در اینجا A ، B ، C ، D مقادیر داده شده هستند و شما باید مقدار E را با استفاده از یک مدل پیش بینی توالی پیش بینی کنید.

نصب پکیج های مفید
برای تجزیه و تحلیل داده های سری زمانی با استفاده از پایتون ، ما باید پکیج های زیر را نصب کنیم –
Pandas
Pandas یک کتابخانه منبع باز دارای مجوز BSD است که دارای کارایی بالا، سهولت استفاده از ساختار داده ها و ابزار تجزیه و تحلیل داده ها برای پایتون است. با کمک دستور زیر می توانید Pandas را نصب کنید –
|
1 |
pip install pandas |
اگر از Anaconda استفاده می کنید و می خواهید با استفاده از مدیر پکیج conda نصب کنید، می توانید از دستور زیر استفاده کنید –
|
1 |
conda install -c anaconda pandas |
hmmlearn
این یک کتابخانه منبع باز دارای مجوز BSD است که از الگوریتم ها و مدل های ساده ای برای یادگیری مدل های مخفی مارکوف (HMM) در پایتون تشکیل شده است. با کمک دستور زیر می توانید آن را نصب کنید –
|
1 |
pip install hmmlearn |
اگر از Anaconda استفاده می کنید و می خواهید با استفاده از مدیر بسته conda نصب کنید ، می توانید از دستور زیر استفاده کنید –
|
1 |
conda install -c omnia hmmlearn |
PyStruct
این یک کتابخانه یادگیری و پیش بینی ساختاری است. الگوریتم های یادگیری اجرا شده در PyStruct دارای نام هایی از قبیل زمینه های تصادفی مشروط (CRF)، شبکه های تصادفی حداکثر حاشیه مارکوف (M3N) یا ماشین های بردار پشتیبانی ساختاری هستند. با کمک دستور زیر می توانید آن را نصب کنید –
|
1 |
pip install pystruct |
CVXOPT
برای بهینه سازی convex بر اساس زبان برنامه نویسی پایتون استفاده می شود. همچنین یک بسته نرم افزاری رایگان است. با کمک دستور زیر می توانید آن را نصب کنید –
|
1 |
pip install cvxopt |
اگر از Anaconda استفاده می کنید و می خواهید با استفاده از مدیر پکیج conda نصب کنید ، می توانید از دستور زیر استفاده کنید –
|
1 |
conda install -c anaconda cvdoxt |
Pandas: رسیدگی ، برش و استخراج آمار از داده های سری زمانی
اگر مجبور باشید با داده های سری زمانی کار کنید ، Pandas ابزاری بسیار مفید است. با کمک Pandas می توانید موارد زیر را انجام دهید –
- با استفاده از بسته pd.date_range محدوده ای از تاریخ ها را ایجاد کنید
- Pandas را با استفاده از بسته pd.Series فهرست کنید
- با استفاده از بسته ts.resample نمونه گیری مجدد را انجام دهید
- فرکانس را تغییر دهید
مثال
مثال زیر نشان می دهد که شما با استفاده از Pandas داده های سری زمانی را مدیریت و برش می دهید. توجه داشته باشید که در اینجا ما از داده های Monthly Arctic Oscillation استفاده می کنیم که می تواند از ماهانه.ao.index.b50.current.ascii دانلود شود و برای استفاده ما به قالب متن تبدیل شود.
مدیریت داده های سری زمانی
برای مدیریت داده های سری زمانی، باید مراحل زیر را انجام دهید –
اولین مرحله شامل وارد کردن پکیج های زیر است –
|
1 2 3 |
import numpy as np import matplotlib.pyplot as plt import pandas as pd |
بعداً، تابعی را تعریف کنید که داده ها را از فایل ورودی بخواند، همانطور که در کدی که در زیر آورده شده است ،
|
1 2 |
def read_data(input_file): input_data = np.loadtxt(input_file, delimiter = None) |
اکنون، این داده ها را به سری های زمانی تبدیل کنید. برای این منظور، محدوده تاریخ سری های زمانی ما را ایجاد کنید. در این مثال، ما یک ماه را به عنوان فراوانی داده ها نگه می داریم. فایل ما دارای داده هایی است که از ژانویه 1950 شروع می شود.
|
1 |
dates = pd.date_range('1950-01', periods = input_data.shape[0], freq = 'M') |
در این مرحله، ما داده های سری زمانی را با کمک سری Pandas ایجاد می کنیم، همانطور که در زیر نشان داده شده است –
|
1 2 3 4 |
output = pd.Series(input_data[:, index], index = dates) return output if __name__=='__main__': |
همانطور که در اینجا نشان داده شده است مسیر فایل ورودی را وارد کنید –
|
1 |
input_file = "/Users/admin/AO.txt" |
همانطور که در اینجا نشان داده شده است، ستون را به قالب باربرگ تبدیل کنید –
|
1 |
timeseries = read_data(input_file) |
در آخر، داده ها را با استفاده از دستورات نشان داده شده رسم و تجسم کنید –
|
1 2 3 |
plt.figure() timeseries.plot() plt.show() |
همانطور که در تصاویر زیر نشان داده شده است، نقشه ها را مشاهده خواهید کرد –
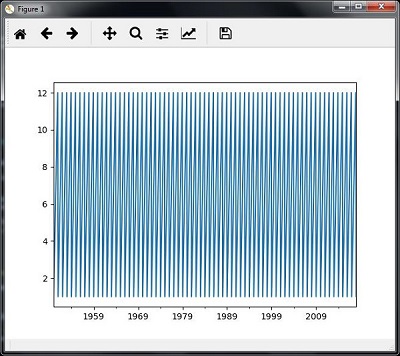
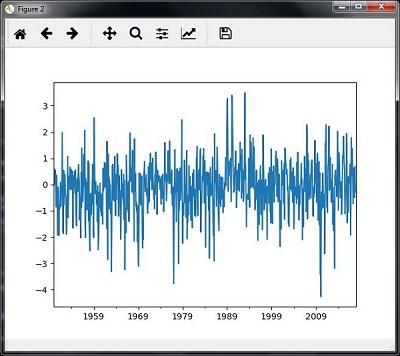
برش داده های سری زمانی
برش شامل بازیابی تنها بخشی از داده های سری زمانی است. به عنوان بخشی از مثال، ما داده ها را فقط از سال 1980 تا 1990 برش می دهیم. کد زیر را که این کار را انجام می دهد مشاهده کنید –
|
1 2 3 4 |
timeseries['1980':'1990'].plot() <matplotlib.axes._subplots.AxesSubplot at 0xa0e4b00> plt.show() |
وقتی کد برش داده های سری زمانی را اجرا می کنید، می توانید نمودار زیر را همانطور که در تصویر نشان داده شده است مشاهده کنید –
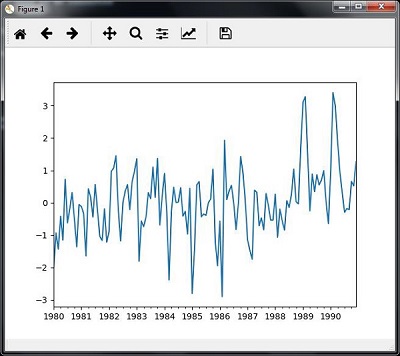
استخراج آمار از داده های سری زمانی
در مواردی که نیاز به نتیجه گیری مهم دارید، باید از داده های ارائه شده برخی از آمارها را استخراج کنید. میانگین، واریانس، همبستگی، حداکثر مقدار و حداقل مقدار برخی از این آمارها هستند. اگر می خواهید چنین آماری را از داده های سری زمانی مشخص استخراج کنید ، می توانید از کد زیر استفاده کنید –
میانگین
همانطور که در اینجا نشان داده شده است، برای یافتن میانگین می توانید از تابع ()mean استفاده کنید –
|
1 |
timeseries.mean() |
سپس خروجی که برای مثال مورد بحث مشاهده خواهید کرد –
|
1 |
-0.11143128165238671 |
بیشترین
همانطور که در اینجا نشان داده شده است ، برای یافتن حداکثر می توانید از تابع ()max استفاده کنید –
|
1 |
timeseries.max () |
سپس خروجی که برای مثال مورد بحث مشاهده خواهید کرد –
|
1 |
3.4952999999999999 |
کمترین
همانطور که در اینجا نشان داده شده است ، برای یافتن حداقل می توانید از تابع ()min استفاده کنید –
|
1 |
timeseries.min () |
سپس خروجی که برای مثال مورد بحث مشاهده خواهید کرد –
|
1 |
-4.2656999999999998 |
ارائه همه آمار همزمان
اگر می خواهید همه آمارها را همزمان محاسبه کنید، می توانید از تابع ()describe همانطور که در اینجا نشان داده شده است استفاده کنید –
|
1 |
timeseries.describe () |
سپس خروجی که برای مثال مورد بحث مشاهده خواهید کرد –
|
1 2 3 4 5 6 7 8 9 |
count 817.000000 mean -0.111431 std 1.003151 min -4.265700 25% -0.649430 50% -0.042744 75% 0.475720 max 3.495300 dtype: float64 |
نمونه گیری مجدد
می توانید داده ها را با فرکانس زمانی دیگر مثال بزنید. دو پارامتر برای انجام نمونه گیری مجدد عبارتند از:
بازه زمانی (Time period)
روش (Method)
نمونه گیری مجدد با ()mean
شما می توانید از کد زیر برای نمونه سازی مجدد داده ها با متد ()mean استفاده کنید، که روش پیش فرض است –
|
1 2 3 |
timeseries_mm = timeseries.resample("A").mean() timeseries_mm.plot(style = 'g--') plt.show() |
سپس، می توانید نمودار زیر را به عنوان خروجی نمونه برداری با استفاده از ()mean مشاهده کنید –
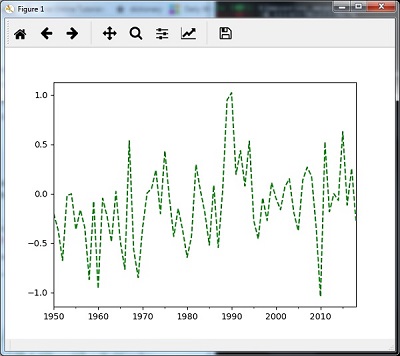
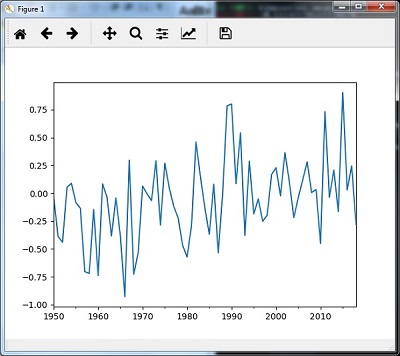
نمونه گیری مجدد با ()median
برای نمونه سازی مجدد داده ها با استفاده از متد ()median می توانید از کد زیر استفاده کنید –
|
1 2 3 |
timeseries_mm = timeseries.resample("A").median() timeseries_mm.plot() plt.show() |
سپس، می توانید نمودار زیر را به عنوان خروجی نمونه گیری مجدد با ()median مشاهده کنید:
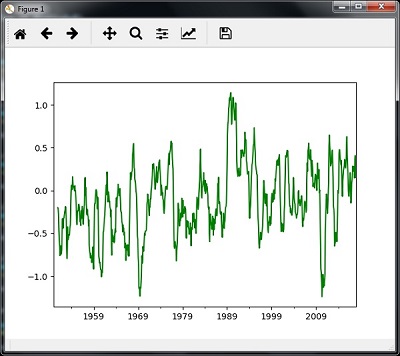
میانگین متحرک
برای محاسبه میانگین متحرک می توانید از کد زیر استفاده کنید –
|
1 2 |
timeseries.rolling(window = 12, center = False).mean().plot(style = '-g') plt.show() |
سپس، می توانید نمودار زیر را به عنوان خروجی میانگین متحرک مشاهده کنید –
تجزیه و تحلیل داده های متوالی توسط مدل پنهان مارکوف (HMM)
HMM یک مدل آماری است که به طور گسترده ای برای داده های دارای تداوم و توسعه پذیری مانند تجزیه و تحلیل بورس سری زمانی، معاینه سلامت و تشخیص گفتار استفاده می شود. این بخش به طور مفصل با تجزیه و تحلیل داده های متوالی با استفاده از مدل پنهان مارکوف (HMM) سروکار دارد.
مدل پنهان مارکوف (HMM)
HMM یک مدل تصادفی است که براساس مفهوم زنجیره مارکوف ساخته می شود و این فرض را می گیرد که احتمال آماری که در آینده وجود دارد بستگی به وضعیت روند فعلی دارد و نه هر حالت قبل از آن. به عنوان مثال، هنگام پرتاب یک سکه، نمی توان گفت که نتیجه پنجمین پرتاب شیر است. این به این دلیل است که یک سکه هیچ حافظه ای ندارد و نتیجه بعدی به نتیجه قبلی بستگی ندارد.
از نظر ریاضی، HMM از متغیرهای زیر تشکیل شده است –
(States (S
این مجموعه ای از حالتهای پنهان است که در HMM وجود دارد. با S نشان داده می شود.
(Output symbols (O
مجموعه ای از نمادهای خروجی ممکن است که در HMM وجود دارد. با O نشان داده می شود.
ماتریس احتمال انتقال حالت (A)
این احتمال انتقال از یک حالت به هر حالت دیگر است. با A مشخص می شود.
ماتریس احتمال انتشار (B)
این احتمال انتشار / مشاهده نمادی در یک حالت خاص است. با B مشخص می شود.
ماتریس احتمال قبلی (Π)
این احتمال شروع در یک حالت خاص از حالت های مختلف سیستم است. این با Π نشان داده می شود.
از این رو ، یک HMM ممکن است به عنوان (𝝀 = (S ، O ، A ، B ، 𝝅 تعریف شود ،
جایی که،
- {S = {s1، s2،…، sN مجموعه ای از N حالت های ممکن است
- {O = {o1، o2،…، oM مجموعه ای از نمادهای مشاهده ممکن M است ،
- A ماتریس احتمال انتقال حالت (N𝒙N (TPM است ،
- B یک ماتریس مشاهده یا احتمال انتشار (N𝒙M (EPM است ،
π یک بردار توزیع احتمال اولیه حالت N بعدی است.
مثال: تجزیه و تحلیل داده های بازار سهام
در این مثال، ما می خواهیم داده های بازار سهام را مرحله به مرحله تجزیه و تحلیل کنیم تا در مورد نحوه کار HMM با داده های متوالی یا سری زمانی ایده بگیریم. لطفا توجه داشته باشید که ما این مثال را در پایتون پیاده سازی می کنیم.
پکیج های لازم را مانند تصویر زیر وارد کنید –
|
1 2 |
import datetime import warnings |
همانطور که در اینجا نشان داده شده است، اکنون از داده های بازار سهام از پکیج matpotlib.finance استفاده کنید –
|
1 2 3 4 5 6 7 8 9 10 |
import numpy as np from matplotlib import cm, pyplot as plt from matplotlib.dates import YearLocator, MonthLocator try: from matplotlib.finance import quotes_historical_yahoo_och1 except ImportError: from matplotlib.finance import ( quotes_historical_yahoo as quotes_historical_yahoo_och1) from hmmlearn.hmm import GaussianHMM |
داده ها را از تاریخ شروع و تاریخ پایان دانلود کنید، یعنی بین دو تاریخ خاص همانطور که در اینجا نشان داده شده است –
|
1 2 3 |
start_date = datetime.date(1995, 10, 10) end_date = datetime.date(2015, 4, 25) quotes = quotes_historical_yahoo_och1('INTC', start_date, end_date) |
در این مرحله، ما هر روز نقل قول های پایانی را استخراج می کنیم. برای این کار، از دستور زیر استفاده کنید –
|
1 |
closing_quotes = np.array([quote[2] for quote in quotes]) |
اکنون، ما حجم سهام معامله شده هر روز را استخراج خواهیم کرد. برای این کار، از دستور زیر استفاده کنید –
|
1 |
volumes = np.array([quote[5] for quote in quotes])[1:] |
در اینجا، با استفاده از کدی که در زیر نشان داده شده ، درصد اختلاف قیمت های بسته شدن سهام را در نظر بگیرید –
|
1 2 3 |
diff_percentages = 100.0 * np.diff(closing_quotes) / closing_quotes[:-] dates = np.array([quote[0] for quote in quotes], dtype = np.int)[1:] training_data = np.column_stack([diff_percentages, volumes]) |
در این مرحله، Gaussian HMM را ایجاد و آموزش دهید. برای این کار از کد زیر استفاده کنید –
|
1 2 3 4 |
hmm = GaussianHMM(n_components = 7, covariance_type = 'diag', n_iter = 1000) with warnings.catch_warnings(): warnings.simplefilter('ignore') hmm.fit(training_data) |
اکنون، با استفاده از دستورات نشان داده شده، داده ها را با استفاده از مدل HMM تولید کنید –
|
1 2 |
num_samples = 300 samples, _ = hmm.sample(num_samples) |
سرانجام در این مرحله درصد اختلاف و حجم سهام معامله شده به عنوان خروجی را به صورت نمودار ترسیم و تجسم می کنیم.
برای ترسیم و تجسم درصد اختلافات از کد زیر استفاده کنید –
|
1 2 3 |
plt.figure() plt.title('Difference percentages') plt.plot(np.arange(num_samples), samples[:, 0], c = 'black') |
برای ترسیم و تجسم حجم سهام معامله شده از کد زیر استفاده کنید –
|
1 2 3 4 5 |
plt.figure() plt.title('Volume of shares') plt.plot(np.arange(num_samples), samples[:, 1], c = 'black') plt.ylim(ymin = 0) plt.show() |
لیست جلسات قبل آموزش هوش مصنوعی با برنامه نویسی پایتون
- آموزش هوش مصنوعی با برنامه نویسی پایتون – مفهوم کلی
- شروع آموزش هوش مصنوعی با برنامه نویسی پایتون
- یادگیری ماشین در هوش مصنوعی با برنامه نویسی پایتون
- هوش مصنوعی با برنامه نویسی پایتون، آماده سازی داده ها
- هوش مصنوعی با پایتون، یادگیری نظارت شده و طبقه بندی
- هوش مصنوعی با برنامه نویسی پایتون – یادگیری تحت نظارت: رگرسیون
- هوش مصنوعی با برنامه نویسی پایتون – برنامه نویسی منطقی
- هوش مصنوعی با پایتون – یادگیری بدون نظارت: خوشه بندی
- هوش مصنوعی با پایتون – پردازش زبان طبیعی
- هوش مصنوعی با پایتون – پکیج NLTK



.svg)
دیدگاه شما