
هوش مصنوعی با پایتون – تشخیص گفتار

هوش مصنوعی با پایتون – تشخیص گفتار
در این درس از مجموعه آموزش برنامه نویسی سایت سورس باران، ما در مورد تشخیص گفتار با استفاده از هوش مصنوعی با پایتون یاد خواهیم گرفت.
گفتار اساسی ترین وسیله ارتباطی انسان بزرگسال است. هدف اساسی پردازش گفتار فراهم آوردن تعامل بین انسان و ماشین است.
سیستم پردازش گفتار عمدتا سه وظیفه دارد –
- اول، تشخیص گفتار که به دستگاه اجازه می دهد کلمات، عبارات و جملاتی را که ما صحبت می کنیم را تشخیص دهد.
- دوم، پردازش زبان طبیعی به دستگاه اجازه می دهد تا صحبت ما را بفهمد ، و
- سوم، سنتز گفتار برای اجازه دادن به دستگاه برای صحبت کردن.
این درسبر شناخت گفتار، روند درک کلماتی است که توسط انسان گفته می شود. به یاد داشته باشید که سیگنال های گفتاری با کمک میکروفون گرفته می شوند و سپس باید توسط سیستم قابل درک باشد.
ساخت یک تشخیص دهنده گفتار
تشخیص گفتار یا تشخیص خودکار گفتار (ASR) مرکز توجه پروژه های هوش مصنوعی مانند رباتیک است. بدون ASR، نمی توان یک ربات شناختی را در تعامل با یک انسان تصور کرد. با این حال، ساخت یک تشخیص گفتار کاملاً آسان نیست.
پیشنهاد ویژه : پکیج آموزش پروژه محور پایتون
مشکلات در ایجاد سیستم تشخیص گفتار
توسعه سیستم تشخیص گفتار با کیفیت بالا واقعاً یک مشکل دشوار است. دشواری فن آوری تشخیص گفتار را می توان به طور گسترده ای در کنار تعدادی از ابعاد مشخص کرد که در زیر بحث شده است –
- اندازه واژگان – اندازه واژگان بر سهولت ایجاد ASR تأثیر می گذارد. برای درک بهتر اندازه واژگان زیر را در نظر بگیرید.
- یک واژگان با ابعاد کوچک از 2 تا 100 کلمه تشکیل شده است، به عنوان مثال، مانند سیستم منوی صوتی
- یک واژگان با اندازه متوسط از چندین 100 تا 1000 هزار کلمه تشکیل شده است، به عنوان مثال، مانند کار بازیابی پایگاه داده
- یک واژگان با ابعاد بزرگ، مانند یک دیکته، از 10000 هزار کلمه تشکیل شده است.
توجه داشته باشید که هرچه اندازه واژگان بزرگتر باشد، تشخیص آن دشوارتر است.
- ویژگی های کانال – کیفیت کانال نیز یک بعد مهم است. به عنوان مثال، گفتار انسانی شامل پهنای باند بالا با دامنه فرکانس کامل است، در حالی که گفتار تلفنی از پهنای باند کم با دامنه فرکانس محدود تشکیل شده است. توجه داشته باشید که در مورد دوم دشوارتر است.
- حالت گفتاری – سهولت ایجاد ASR به حالت گفتاری نیز بستگی دارد، یعنی اینکه سخنرانی در حالت کلمه ای جداگانه یا حالت کلمه متصل باشد یا در حالت گفتار مداوم باشد. توجه داشته باشید که تشخیص گفتار مداوم دشوارتر است.
- سبک صحبت کردن – سخنرانی خوانده شده ممکن است به سبک رسمی یا خود به خودی و گفتگوی با سبک عامیانه باشد. تشخیص مورد دوم دشوارتر است.
- وابستگی بلندگو – گفتار می تواند وابسته به بلندگو، تطبیق دهنده بلندگو یا مستقل از بلندگو باشد.
- نوع نویز – نویز عامل دیگری است که باید هنگام ایجاد ASR مورد توجه قرار گیرد. نسبت سیگنال به نویز ممکن است در محدوده های مختلف باشد، بسته به محیط صوتی که کمتر در مقایسه با بیشتر سر و صدای زمینه مشاهده می کند –
- اگر نسبت سیگنال به نویز بیشتر از 30dB باشد ، آن را به عنوان دامنه بالا در نظر می گیرند
- اگر نسبت سیگنال به نویز بین 30dB تا 10db باشد، به عنوان SNR متوسط در نظر گرفته می شود
- اگر نسبت سیگنال به نویز کمتر از 10dB باشد، به عنوان دامنه کم در نظر گرفته می شود
به عنوان مثال، نوع سر و صدای پس زمینه مانند سر و صدای ساکن، غیر انسانی، گفتار پس زمینه و کراس لک توسط بلندگوهای دیگر نیز به دشواری مشکل کمک می کند.
- ویژگی های میکروفون – کیفیت میکروفون ممکن است خوب ، متوسط یا کمتر از حد متوسط باشد. همچنین ، فاصله بین دهان و تلفن میکرو ممکن است متفاوت باشد. این عوامل همچنین باید برای سیستم های تشخیص در نظر گرفته شود.
با وجود این دشواری ها، محققان روی جنبه های مختلف گفتار مانند درک سیگنال گفتار، بلندگو و شناسایی لهجه ها بسیار کار کردند.
برای ساخت یک تشخیص گفتار باید مراحل زیر را دنبال کنید –
تجسم سیگنال های صوتی – خواندن از یک فایل و کار بر روی آن
این اولین گام در ساخت سیستم تشخیص گفتار است زیرا درک درستی از ساختار سیگنال صوتی می دهد. برخی از مراحل معمول که می تواند برای کار با سیگنال های صوتی دنبال شود ، به شرح زیر است –
ضبط
وقتی باید سیگنال صوتی را از یک فایل بخوانید، ابتدا آن را با استفاده از میکروفون ضبط کنید.
نمونه گیری
هنگام ضبط با میکروفون، سیگنال ها به صورت دیجیتالی ذخیره می شوند. اما برای کار بر روی آن، دستگاه به آنها در شکل عددی گسسته نیاز دارد. از این رو ما باید نمونه برداری را در یک فرکانس مشخص انجام دهیم و سیگنال را به شکل عددی گسسته تبدیل کنیم. انتخاب فرکانس بالا برای نمونه گیری به این معنی است که وقتی انسان به سیگنال گوش می دهد ، آن را به عنوان یک سیگنال صوتی مداوم احساس می کند.
مثال
مثال زیر یک روش گام به گام برای تجزیه و تحلیل یک سیگنال صوتی را با استفاده از پایتون نشان می دهد که در یک فایل ذخیره شده است. فرکانس این سیگنال صوتی 44100 HZ است.
پکیج های لازم را همانطور که در اینجا نشان داده شده وارد کنید –
|
1 2 3 |
import numpy as np import matplotlib.pyplot as plt from scipy.io import wavfile |
اکنون، فایل صوتی ذخیره شده را بخوانید. این دو مقدار را برمی گرداند: فرکانس نمونه برداری و سیگنال صوتی. همانطور که در اینجا نشان داده شده است ، مسیر فایل صوتی را در آن ذخیره کنید.
|
1 |
frequency_sampling, audio_signal = wavfile.read("/Users/admin/audio_file.wav") |
پارامترهایی مانند فرکانس نمونه برداری از سیگنال صوتی، نوع داده سیگنال و مدت زمان آن را با استفاده از دستورات نشان داده شده نمایش دهید –
|
1 2 3 4 |
print('\nSignal shape:', audio_signal.shape) print('Signal Datatype:', audio_signal.dtype) print('Signal duration:', round(audio_signal.shape[0] / float(frequency_sampling), 2), 'seconds') |
این مرحله شامل نرمال سازی سیگنال است که در زیر نشان داده شده است –
|
1 |
audio_signal = audio_signal / np.power(2, 15) |
در این مرحله، ما در حال استخراج 100 مقدار اول از این سیگنال برای تجسم هستیم. برای این منظور از دستورات زیر استفاده کنید –
|
1 2 |
audio_signal = audio_signal [:100] time_axis = 1000 * np.arange(0, len(signal), 1) / float(frequency_sampling) |
اکنون، سیگنال را با استفاده از دستورات زیر تجسم کنید –
|
1 2 3 4 5 |
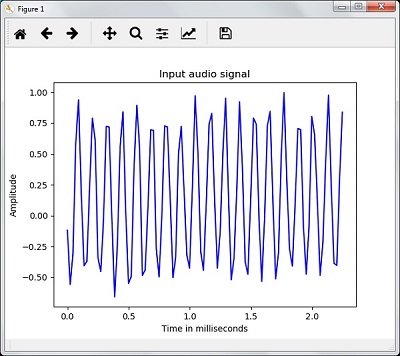
plt.plot(time_axis, signal, color='blue') plt.xlabel('Time (milliseconds)') plt.ylabel('Amplitude') plt.title('Input audio signal') plt.show() |
شما می توانید یک نمودار خروجی و داده های استخراج شده برای سیگنال صوتی فوق را مشاهده کنید همانطور که در تصویر اینجا نشان داده شده است
|
1 2 3 |
Signal shape: (132300,) Signal Datatype: int16 Signal duration: 3.0 seconds |
مشخص کردن سیگنال صوتی: تبدیل به دامنه فرکانس
مشخص کردن یک سیگنال صوتی شامل تبدیل سیگنال دامنه زمان به دامنه فرکانس و درک اجزای فرکانس آن است. این یک مرحله مهم است زیرا اطلاعات زیادی در مورد سیگنال می دهد. برای انجام این تحول می توانید از یک ابزار ریاضی مانند تبدیل فوریه استفاده کنید.
مثال
مثال زیر گام به گام نحوه مشخص کردن سیگنال را با استفاده از پایتون نشان می دهد که در یک فایل ذخیره شده است. توجه داشته باشید که در اینجا ما از ابزار ریاضی تبدیل فوریه برای تبدیل آن به دامنه فرکانس استفاده می کنیم.
همانطور که در اینجا نشان داده شده ، بسته های لازم را وارد کنید –
|
1 2 3 |
import numpy as np import matplotlib.pyplot as plt from scipy.io import wavfile |
اکنون، فایل صوتی ذخیره شده را بخوانید. این دو مقدار را برمی گرداند: فرکانس نمونه برداری و سیگنال صوتی. مسیر فایل صوتی را که در آن ذخیره شده است ارائه دهید همانطور که در فرمان اینجا نشان داده شده است –
|
1 |
frequency_sampling, audio_signal = wavfile.read("/Users/admin/sample.wav") |
در این مرحله، ما پارامترهایی مانند فرکانس نمونه برداری از سیگنال صوتی، نوع داده سیگنال و مدت زمان آن را با استفاده از دستورات زیر نمایش می دهیم –
|
1 2 3 4 |
print('\nSignal shape:', audio_signal.shape) print('Signal Datatype:', audio_signal.dtype) print('Signal duration:', round(audio_signal.shape[0] / float(frequency_sampling), 2), 'seconds') |
در این مرحله، ما باید سیگنال را عادی کنیم، همانطور که در دستور زیر نشان داده شده است –
|
1 |
audio_signal = audio_signal / np.power(2, 15) |
این مرحله شامل استخراج طول و نیم طول سیگنال است. برای این منظور از دستورات زیر استفاده کنید –
|
1 2 |
length_signal = len(audio_signal) half_length = np.ceil((length_signal + 1) / 2.0).astype(np.int) |
اکنون، ما باید از ابزارهای ریاضیات برای تبدیل به دامنه فرکانس استفاده کنیم. در اینجا ما از تغییر شکل فوریه استفاده می کنیم.
|
1 |
signal_frequency = np.fft.fft(audio_signal) |
اکنون نرمال سازی سیگنال دامنه فرکانس را انجام دهید و آنرا مربع کنید –
|
1 2 |
signal_frequency = abs(signal_frequency[0:half_length]) / length_signal signal_frequency **= 2 |
بعد، طول و نیم طول سیگنال تبدیل شده را استخراج کنید –
|
1 |
len_fts = len(signal_frequency) |
توجه داشته باشید که سیگنال تبدیل شده فوریه باید برای موارد بزرگ و همچنین بزرگ تنظیم شود.
|
1 2 3 4 |
if length_signal % 2: signal_frequency[1:len_fts] *= 2 else: signal_frequency[1:len_fts-1] *= 2 |
اکنون قدرت را در دسی بل استخراج کنید –
|
1 |
signal_power = 10 * np.log10(signal_frequency) |
فرکانس را برای محور X در کیلو هرتز تنظیم کنید –
|
1 |
x_axis = np.arange(0, len_half, 1) * (frequency_sampling / length_signal) / 1000.0 |
اکنون، توصیف سیگنال را به صورت زیر تجسم کنید –
|
1 2 3 4 5 |
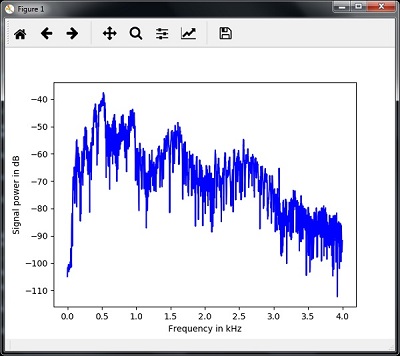
plt.figure() plt.plot(x_axis, signal_power, color='black') plt.xlabel('Frequency (kHz)') plt.ylabel('Signal power (dB)') plt.show() |
همانطور که در تصویر زیر نشان داده شده است، می توانید نمودار خروجی کد بالا را مشاهده کنید –
تولید سیگنال صوتی یکنواخت
دو مرحله ای که تاکنون مشاهده کرده اید برای یادگیری سیگنال ها مهم هستند. اکنون، اگر می خواهید سیگنال صوتی را با برخی پارامترهای از پیش تعریف شده تولید کنید، این مرحله نیز مفید خواهد بود. توجه داشته باشید که این مرحله سیگنال صوتی را در یک پرونده خروجی ذخیره می کند.
مثال
در مثال زیر، ما قصد داریم با استفاده از پایتون یک سیگنال یکنواخت تولید کنیم که در یک فایل ذخیره می شود. برای این، شما باید مراحل زیر را انجام دهید –
پکیج های لازم را همانطور که نشان داده شده وارد کنید –
|
1 2 3 |
import numpy as np import matplotlib.pyplot as plt from scipy.io.wavfile import write |
فایلی را تهیه کنید که فایل خروجی باید در آن ذخیره شود
|
1 |
output_file = 'audio_signal_generated.wav' |
همانطور که نشان داده شده است، پارامترهای مورد نظر خود را مشخص کنید –
|
1 2 3 4 5 |
duration = 4 # in seconds frequency_sampling = 44100 # in Hz frequency_tone = 784 min_val = -4 * np.pi max_val = 4 * np.pi |
در این مرحله، ما می توانیم سیگنال صوتی را تولید کنیم، همانطور که نشان داده شده است –
|
1 2 |
t = np.linspace(min_val, max_val, duration * frequency_sampling) audio_signal = np.sin(2 * np.pi * tone_freq * t) |
اکنون، فایل صوتی را در فایل خروجی ذخیره کنید –
|
1 |
write(output_file, frequency_sampling, signal_scaled) |
همانطور که نشان داده شده، 100 مقدار اول را برای نمودار ما استخراج کنید –
|
1 2 |
audio_signal = audio_signal[:100] time_axis = 1000 * np.arange(0, len(signal), 1) / float(sampling_freq) |
اکنون، سیگنال صوتی تولید شده را به صورت زیر تجسم کنید –
|
1 2 3 4 5 |
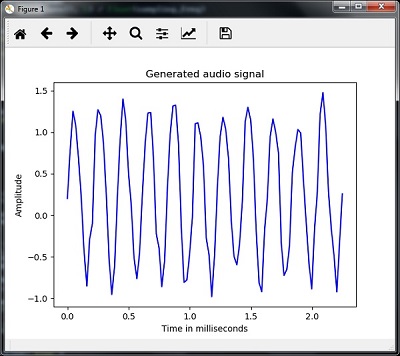
plt.plot(time_axis, signal, color='blue') plt.xlabel('Time in milliseconds') plt.ylabel('Amplitude') plt.title('Generated audio signal') plt.show() |
شما می توانید همانطور که در شکل نشان داده شده است، طرح را مشاهده کنید –
استخراج ویژگی از گفتار
این مهمترین مرحله در ساخت یک تشخیص دهنده گفتار است زیرا پس از تبدیل سیگنال گفتار به دامنه فرکانس، باید آن را به شکل قابل استفاده از بردار ویژگی تبدیل کنیم. برای این منظور می توانیم از تکنیک های مختلف استخراج ویژگی مانند MFCC ، PLP ، PLP-RASTA و غیره استفاده کنیم.
مثال
در مثال زیر، ما می خواهیم با استفاده از روش MFCC، گام به گام با استفاده از پایتون ویژگی ها را از سیگنال استخراج کنیم.
همانطور که در اینجا نشان داده شده، پکیج های لازم را وارد کنید –
|
1 2 3 4 |
import numpy as np import matplotlib.pyplot as plt from scipy.io import wavfile from python_speech_features import mfcc, logfbank |
اکنون، فایل صوتی ذخیره شده را بخوانید. این دو مقدار – فرکانس نمونه برداری و سیگنال صوتی را برمی گرداند. مسیر فایل صوتی را در جایی که ذخیره شده ارائه دهید.
|
1 |
frequency_sampling, audio_signal = wavfile.read("/Users/admin/audio_file.wav") |
توجه داشته باشید که در اینجا ما 15000 نمونه اول را برای تجزیه و تحلیل در نظر می گیریم.
|
1 |
audio_signal = audio_signal[:15000] |
برای استخراج ویژگی های MFCC از تکنیک های MFCC استفاده کرده و دستور زیر را اجرا کنید –
|
1 |
features_mfcc = mfcc(audio_signal, frequency_sampling) |
همانطور که نشان داده شده است، پارامترهای MFCC را چاپ کنید –
|
1 2 |
print('\nMFCC:\nNumber of windows =', features_mfcc.shape[0]) print('Length of each feature =', features_mfcc.shape[1]) |
اکنون، با استفاده از دستورات زیر، ویژگی های MFCC را ترسیم و تجسم کنید –
|
1 2 3 |
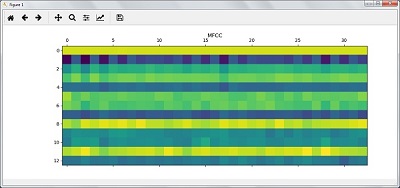
features_mfcc = features_mfcc.T plt.matshow(features_mfcc) plt.title('MFCC') |
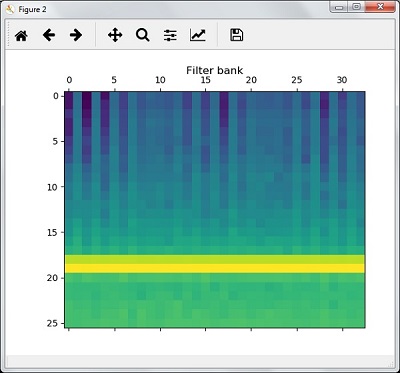
در این مرحله، ما با ویژگی های فیلتر بانک کار می کنیم همانطور که نشان داده شده است –
استخراج ویژگی های فیلتر بانک –
|
1 |
filterbank_features = logfbank(audio_signal, frequency_sampling) |
اکنون، پارامترهای فیلتربانک را چاپ کنید.
|
1 2 |
print('\nFilter bank:\nNumber of windows =', filterbank_features.shape[0]) print('Length of each feature =', filterbank_features.shape[1]) |
اکنون ، ویژگی های فیلتربانک را ترسیم و تجسم کنید.
|
1 2 3 4 |
filterbank_features = filterbank_features.T plt.matshow(filterbank_features) plt.title('Filter bank') plt.show() |
در نتیجه مراحل بالا ، می توانید خروجی های زیر را مشاهده کنید: شکل 1 برای MFCC و شکل 2 برای فیلتر بانک
تشخیص کلمات گفتاری
تشخیص گفتار به این معنی است که وقتی انسان در حال صحبت است، یک ماشین آن را درک می کند. در اینجا ما برای تحقق بخشیدن به آن از API گفتار Google در پایتون استفاده می کنیم. برای این کار باید پکیج های زیر را نصب کنیم –
- Pyaudio – با استفاده از دستور pip install Pyaudio قابل نصب است.
- SpeechRecognition – این پکیج را می توان با استفاده از pip install SpeechRecognition نصب کرد.
- Google-Speech-API – با استفاده از دستور pip install google-api-python-client قابل نصب است.
مثال
برای درک درستی از تشخیص کلمات گفتاری، مثال زیر را مشاهده کنید –
پکیج های لازم را همانطور که نشان داده شده وارد کنید –
|
1 |
import speech_recognition as sr |
همانطور که در زیر نشان داده شده است، یک شی ایجاد کنید –
|
1 |
recording = sr.Recognizer() |
اکنون، ماژول ()Microphone صدا را به عنوان ورودی می گیرد –
|
1 2 3 |
with sr.Microphone() as source: recording.adjust_for_ambient_noise(source) print("Please Say something:") audio = recording.listen(source) |
اکنون google API صدا را تشخیص می دهد و خروجی می دهد.
|
1 2 3 4 |
try: print("You said: \n" + recording.recognize_google(audio)) except Exception as e: print(e) |
می توانید خروجی زیر را مشاهده کنید –
|
1 2 |
Please Say Something: You said: |
به عنوان مثال، اگر گفتید tutorialspoint.com، سیستم آن را به صورت زیر به درستی تشخیص می دهد –
|
1 |
tutorialspoint.com |
لیست جلسات قبل آموزش هوش مصنوعی با برنامه نویسی پایتون
- آموزش هوش مصنوعی با برنامه نویسی پایتون – مفهوم کلی
- شروع آموزش هوش مصنوعی با برنامه نویسی پایتون
- یادگیری ماشین در هوش مصنوعی با برنامه نویسی پایتون
- هوش مصنوعی با برنامه نویسی پایتون، آماده سازی داده ها
- هوش مصنوعی با پایتون، یادگیری نظارت شده و طبقه بندی
- هوش مصنوعی با برنامه نویسی پایتون – یادگیری تحت نظارت: رگرسیون
- هوش مصنوعی با برنامه نویسی پایتون – برنامه نویسی منطقی
- هوش مصنوعی با پایتون – یادگیری بدون نظارت: خوشه بندی
- هوش مصنوعی با پایتون – پردازش زبان طبیعی
- هوش مصنوعی با پایتون – پکیج NLTK
- هوش مصنوعی با پایتون – تجزیه و تحلیل داده های سری زمانی



.svg)
دیدگاه شما