
آموزش الگوریتم های رگرسیون در یادگیری ماشین با پایتون

آموزش الگوریتم های رگرسیون در یادگیری ماشین با پایتون
در این درس از مجموعه آموزش برنامه نویسی سایت سورس باران، به آموزش الگوریتم های رگرسیون در یادگیری ماشین با پایتون خواهیم پرداخت.
پیشنهاد ویژه : پکیج آموزش طراحی وب سایت با پایتون و جنگو
مقدمه ای برای رگرسیون
رگرسیون یکی دیگر از ابزارهای آماری و یادگیری ماشین مهم و پرکاربرد است. هدف اصلی وظایف مبتنی بر رگرسیون پیش بینی برچسب های خروجی یا پاسخ هایی است که مقادیر عددی ادامه دار برای داده های ورودی داده شده است. خروجی براساس آنچه مدل در مرحله آموزش آموخته است، خواهد بود. اساساً، مدلهای رگرسیونی از ویژگیهای داده ورودی (متغیرهای مستقل) و مقادیر خروجی عددی پیوسته مربوطه (متغیرهای وابسته یا نتیجه) برای یادگیری ارتباط خاص بین ورودی ها و خروجیهای مربوطه استفاده می کنند.
انواع مدل های رگرسیون
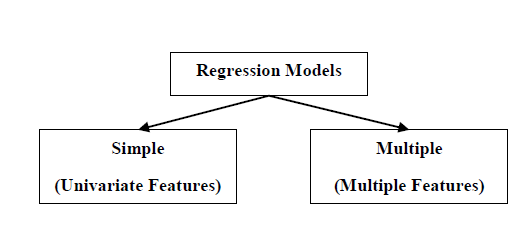
مدل های رگرسیون از دو نوع زیر هستند –
- مدل رگرسیون ساده – این ابتدایی ترین مدل رگرسیون است که در آن پیش بینی ها از یک ویژگی واحد و غیر متغیر داده ها شکل می گیرد.
- مدل رگرسیون چندگانه – همانطور که از نامش پیداست ، در این مدل رگرسیون پیش بینی ها از چندین ویژگی داده شکل می گیرد.
ساخت یک Regressor در پایتون
مدل Regressor در پایتون می تواند درست مانند ما طبقه بندی کننده ساخته شود. Scikit-learn ، یک کتابخانه پایتون برای یادگیری ماشین نیز می تواند برای ساخت یک رگرسیون در پایتون استفاده شود.
در مثال زیر، ما مدل رگرسیون اساسی را ایجاد خواهیم کرد که یک خط برای داده ها دارد یعنی رگرسیون خطی. مراحل لازم برای ساخت یک رگرسیون در پایتون به شرح زیر است –
مرحله 1: وارد کردن بسته پایتون لازم
برای ساخت رگرسیون با استفاده از scikit-learn ، باید آن را به همراه سایر بسته های لازم وارد کنیم. ما می توانیم با استفاده از اسکریپت زیر وارد کنیم –
|
1 2 3 4 |
import numpy as np from sklearn import linear_model import sklearn.metrics as sm import matplotlib.pyplot as plt |
مرحله 2: وارد کردن مجموعه داده
پس از وارد کردن بسته لازم، به یک مجموعه داده برای ساخت مدل پیش بینی رگرسیون نیاز داریم. ما می توانیم آن را از مجموعه داده های sklearn وارد کنیم یا طبق نیاز خود از یکی دیگر استفاده کنیم. ما می خواهیم از داده های ورودی ذخیره شده خود استفاده کنیم. ما می توانیم آن را با کمک اسکریپت زیر وارد کنیم –
|
1 |
input = r'C:\linear.txt' |
بعد، ما باید این داده ها را بارگیری کنیم. ما برای بارگذاری از تابع np.loadtxt استفاده می کنیم.
|
1 2 |
input_data = np.loadtxt(input, delimiter=',') X, y = input_data[:, :-1], input_data[:, -1] |
مرحله 3: سازماندهی داده ها در مجموعه های آموزش و تست
از آنجا که ما باید مدل خود را بر اساس داده های غیبی آزمایش کنیم ، مجموعه داده خود را به دو قسمت تقسیم خواهیم کرد: یک مجموعه آموزش و یک مجموعه تست. دستور زیر آن را انجام می دهد –
|
1 2 3 4 5 6 |
training_samples = int(0.6 * len(X)) testing_samples = len(X) - num_training X_train, y_train = X[:training_samples], y[:training_samples] X_test, y_test = X[training_samples:], y[training_samples:] |
مرحله 4: ارزیابی و پیش بینی مدل
پس از تقسیم داده ها به آموزش و آزمایش ، ما باید مدل را بسازیم. برای این منظور از تابع LineaRegression () Scikit-learn استفاده خواهیم کرد. دستور زیر یک شی رگرسیون خطی ایجاد می کند.
|
1 |
reg_linear= linear_model.LinearRegression() |
بعد، این مدل را با نمونه های آموزش به شرح زیر آموزش دهید –
|
1 |
reg_linear.fit(X_train, y_train) |
اکنون ، سرانجام ما باید پیش بینی را با داده های تست انجام دهیم.
|
1 |
y_test_pred = reg_linear.predict(X_test) |
مرحله 5: طرح و تجسم
پس از پیش بینی ، می توانیم آن را با کمک اسکریپت زیر ترسیم و تجسم کنیم –
مثال
|
1 2 3 4 5 |
plt.scatter(X_test, y_test, color='red') plt.plot(X_test, y_test_pred, color='black', linewidth=2) plt.xticks(()) plt.yticks(()) plt.show() |
خروجی
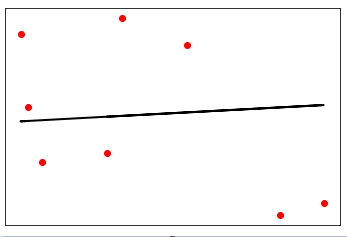
در خروجی فوق می توان خط رگرسیون بین نقاط داده را مشاهده کرد.
مرحله ششم: محاسبه عملکرد
ما همچنین می توانیم عملکرد مدل رگرسیون خود را با کمک معیارهای مختلف عملکرد به شرح زیر محاسبه کنیم –
مثال
|
1 2 3 4 5 6 |
print("Regressor model performance:") print("Mean absolute error(MAE) =", round(sm.mean_absolute_error(y_test, y_test_pred), 2)) print("Mean squared error(MSE) =", round(sm.mean_squared_error(y_test, y_test_pred), 2)) print("Median absolute error =", round(sm.median_absolute_error(y_test, y_test_pred), 2)) print("Explain variance score =", round(sm.explained_variance_score(y_test, y_test_pred), 2)) print("R2 score =", round(sm.r2_score(y_test, y_test_pred), 2)) |
خروجی
|
1 2 3 4 5 6 |
Regressor model performance: Mean absolute error(MAE) = 1.78 Mean squared error(MSE) = 3.89 Median absolute error = 2.01 Explain variance score = -0.09 R2 score = -0.09 |
انواع الگوریتم های رگرسیون ML
مفیدترین و محبوب ترین الگوریتم رگرسیون ML، الگوریتم رگرسیون خطی است که بیشتر به دو نوع تقسیم می شود –
- الگوریتم رگرسیون خطی ساده
- الگوریتم رگرسیون خطی چندگانه.
ما در مورد آن بحث خواهیم کرد و در درس بعد آن را در پایتون پیاده سازی خواهیم کرد.
کاربردها
کاربردهای الگوریتم های رگرسیون ML به شرح زیر است –
- پیش بینی یا تحلیل پیش بینی – یکی از مهمترین کاربردهای رگرسیون ، پیش بینی یا تحلیل پیش بینی است. به عنوان مثال ، ما می توانیم تولید ناخالص داخلی، قیمت نفت یا به عبارتی ساده داده های کمی را که با گذشت زمان تغییر می کند، پیش بینی کنیم.
- بهینه سازی – ما می توانیم فرایندهای تجاری را با کمک بازگشت بهینه کنیم. به عنوان مثال، یک مدیر فروشگاه می تواند یک مدل آماری برای درک زمان تحریک آمدن مشتری ایجاد کند.
- تصحیح خطا – در تجارت ، تصمیم گیری صحیح به همان اندازه بهینه سازی روند تجارت مهم است. رگرسیون می تواند به ما در تصمیم گیری صحیح و همچنین در تصحیح تصمیم قبلاً اجرا شده کمک کند.
- اقتصاد – این پرکاربردترین ابزار در اقتصاد است. ما می توانیم از رگرسیون برای پیش بینی عرضه، تقاضا، مصرف، سرمایه گذاری موجودی و غیره استفاده کنیم.
- امور مالی – یک شرکت مالی همیشه علاقه مند به به حداقل رساندن سبد ریسک است و می خواهد از عواملی که بر مشتریان تأثیر می گذارد مطلع شود. همه اینها را می توان با کمک مدل رگرسیون پیش بینی کرد.
لیست جلسات قبل آموزش یادگیری ماشین با پایتون
- آموزش یادگیری ماشین با پایتون
- مبانی یادگیری ماشین با پایتون
- آموزش اکوسیستم یادگیری ماشین با پایتون
- آموزش متدها در یادگیری ماشین با پایتون
- آموزش بارگیری داده ها برای پروژه های یادگیری ماشین
- آموزش درک داده ها با آمار در یادگیری ماشین
- آموزش آماده سازی داده ها در یادگیری ماشین با پایتون
- آموزش انتخاب ویژگی داده ها در یادگیری ماشین با پایتون
- آموزش طبقه بندی در یادگیری ماشین با پایتون
- آموزش رگرسیون لجستیک در یادگیری ماشین با پایتون
- آموزش ماشین بردار پشتیبان در یادگیری ماشین با پایتون
- آموزش درخت تصمیم در یادگیری ماشین با پایتون
- آموزش Naïve Bayes در یادگیری ماشین با پایتون
- آموزش جنگل تصادفی در یادگیری ماشین با پایتون



.svg)
دیدگاه شما