
آموزش الگوریتم های خوشه بندی در یادگیری ماشین با پایتون

آموزش الگوریتم های خوشه بندی در یادگیری ماشین با پایتون
در این درس از مجموعه آموزش برنامه نویسی سایت سورس باران، به آموزش الگوریتم های خوشه بندی در یادگیری ماشین با پایتون خواهیم پرداخت.
پیشنهاد ویژه : پکیج آموزش صفر تا صد پایتون
مقدمه ای بر خوشه بندی
روش های خوشه بندی یکی از مفیدترین روشهای ML بدون نظارت است. از این روشها برای یافتن شباهت و همچنین الگوهای رابطه در بین نمونه های داده استفاده می شود و سپس این نمونه ها را بر اساس ویژگیها به گروههایی تقسیم می کنیم که دارای شباهت هستند.
خوشه بندی مهم است زیرا گروه بندی ذاتی را در بین داده های بدون برچسب فعلی تعیین می کند. آنها اساساً برخی مفروضات را در مورد نقاط داده ارائه می دهند تا شباهت آنها را تشکیل دهد. هر فرض خوشه های مختلف اما به همان اندازه معتبری را ایجاد خواهد کرد.
به عنوان مثال ، در زیر نمودار نشان داده شده است که سیستم خوشه بندی نوع مشابهی از داده ها را در خوشه های مختلف گروه بندی کرده است –
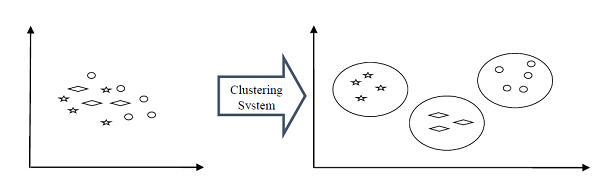
روشهای تشکیل خوشه
لازم نیست که خوشه ها به شکل کروی شکل بگیرند. موارد زیر برخی دیگر از روشهای تشکیل خوشه است –
مبتنی بر تراکم
در این روش ها ، خوشه ها به عنوان منطقه متراکم تشکیل می شوند. مزیت این روش ها این است که از دقت و همچنین توانایی خوبی برای ادغام دو خوشه برخوردارند. سابق. خوشه بندی فضایی مبتنی بر تراکم برنامه های دارای سر و صدا (DBSCAN) ، ترتیب ترتیب برای شناسایی ساختار خوشه بندی (OPTICS) و غیره
مبتنی بر سلسله مراتب
در این روش ها ، خوشه ها به عنوان ساختار نوع درخت و براساس سلسله مراتب تشکیل می شوند. آنها دو دسته دارند: Agglomerative (رویکرد پایین به بالا) و Divisive (رویکرد بالا به پایین). سابق. خوشه بندی با استفاده از نمایندگان (CURE) ، تکرار متعادل و کاهش خوشه بندی با استفاده از سلسله مراتب (BIRCH) و غیره
پارتیشن بندی
در این روش ها، خوشه ها با تقسیم شی ها به خوشه k تشکیل می شوند. تعداد خوشه ها برابر با تعداد پارتیشن ها خواهد بود. سابق. K-means ، خوشه بندی برنامه های بزرگ مبتنی بر جستجوی تصادفی (CLARANS).
شبکه
در این روش ها ، خوشه ها به صورت شبکه ای مانند ساختار تشکیل می شوند. مزیت این روش ها این است که تمام عملیات خوشه بندی انجام شده در این شبکه ها سریع و مستقل از تعداد اشیا data داده است. سابق. شبکه اطلاعات آماری (STING) ، خوشه بندی در تلاش (CLIQUE).
اندازه گیری عملکرد خوشه بندی
یکی از مهمترین مواردی که در مورد مدل ML مورد توجه قرار می گیرد ارزیابی عملکرد آن است یا می توان گفت کیفیت مدل آن است. در مورد الگوریتم های یادگیری نظارت شده ، ارزیابی کیفیت مدل ما آسان است زیرا ما قبلاً برای هر نمونه برچسب هایی داریم.
از طرف دیگر، در صورت الگوریتم های یادگیری بدون نظارت، ما چندان خوشبخت نیستیم زیرا با داده های بدون برچسب سر و کار داریم. اما هنوز برخی معیارها وجود دارد که به پزشک درک می کند که بسته به الگوریتم تغییر خوشه ها تغییر می کند.
قبل از اینکه به چنین معیارهایی فرو برویم ، باید بدانیم که این معیارها فقط عملکرد مقایسه ای مدل ها را با یکدیگر ارزیابی می کنند تا اندازه گیری اعتبار پیش بینی مدل. موارد زیر برخی از معیارهایی است که می توانیم برای اندازه گیری کیفیت مدل در الگوریتم های خوشه بندی استفاده کنیم –
آنالیز Silhouette
آنالیز Silhouette برای بررسی کیفیت مدل خوشه بندی با اندازه گیری فاصله بین خوشه ها استفاده می شود. در اصل راهی برای ارزیابی پارامترها مانند تعداد خوشه ها با کمک نمره Silhouette به ما ارائه می دهد. این نمره میزان نزدیک بودن هر نقطه در یک خوشه به نقاط خوشه های همسایه را اندازه گیری می کند.
تجزیه و تحلیل امتیاز Silhouette
دامنه نمره سیلوئت [-1 ، 1] است. تجزیه و تحلیل آن به شرح زیر است –
نمره 1+ – نمره نزدیک به 1+ نشان می دهد که نمونه از خوشه همسایه خود فاصله زیادی دارد.
0 نمره – 0 نمره سیلوئت نشان می دهد که نمونه در مرز تصمیم گیری است که دو خوشه همسایه را جدا می کند یا بسیار نزدیک است.
-1 نمره و منهای -1 نمره سیلوئت نشان می دهد که نمونه ها به خوشه های اشتباه تقسیم شده اند.
محاسبه نمره سیلوئت را می توان با استفاده از فرمول زیر انجام داد –
𝒔𝒊𝒍𝒉𝒐𝒖𝒆𝒕𝒕𝒆 𝒔𝒄𝒐𝒓𝒆=(𝒑−𝒒)/𝐦𝐚𝐱 (𝒑,𝒒)
در اینجا ، 𝑝 = میانگین فاصله تا نقاط نزدیکترین خوشه
و ، 𝑞 = میانگین فاصله درون خوشه تا تمام نقاط.
شاخص Davis-Bouldin
شاخص DB یکی دیگر از معیارهای خوب برای انجام تجزیه و تحلیل الگوریتم های خوشه بندی است. با کمک شاخص DB می توانیم نکات زیر را در مورد مدل خوشه بندی درک کنیم –
خوشه ها از یکدیگر فاصله خوبی دارند یا نه؟
خوشه ها چقدر متراکم هستند؟
ما می توانیم شاخص DB را با کمک فرمول زیر محاسبه کنیم –
DB = 1n∑i = 1nmaxj ≠ i (σi + σjd (ci، cj))
در اینجا ، 𝑛 = تعداد خوشه ها
σi = فاصله متوسط همه نقاط در خوشه 𝑖 از مرکز خوشه.
شاخص DB کمتر است ، مدل خوشه بندی بهتر است.
شاخص Dunn
این همانند شاخص DB کار می کند اما نقاط زیر وجود دارد که هر دو در آنها متفاوت است –
شاخص Dunn فقط بدترین حالت را در نظر می گیرد یعنی خوشه هایی که به هم نزدیک هستند در حالی که شاخص DB پراکندگی و جداسازی همه خوشه ها را در مدل خوشه بندی در نظر می گیرد.
شاخص Dunn با افزایش عملکرد افزایش می یابد در حالی که شاخص خوشه DB بهتر می شود وقتی خوشه ها دارای فاصله کافی و متراکم باشند.
ما می توانیم شاخص Dunn را با کمک فرمول زیر محاسبه کنیم –
D = min1≤i <j≤nP (i ، j) mix1≤i <k≤nq (k)
در اینجا ، 𝑖 ، 𝑗 ، 𝑘 = هر شاخص برای خوشه ها
𝑝 = فاصله بین خوشه ای
q = فاصله درون خوشه ای
انواع الگوریتم های خوشه بندی ML
موارد زیر مهمترین و مفیدترین الگوریتم های خوشه بندی ML هستند –
خوشه بندی K-means
این الگوریتم خوشه بندی Centroids را محاسبه می کند و تکرار می شود تا زمانی که مرکز بهینه را پیدا کند. فرض بر این است که تعداد خوشه ها از قبل مشخص است. به آن الگوریتم خوشه بندی مسطح نیز می گویند. تعداد خوشه های مشخص شده از داده ها توسط الگوریتم با ‘K’ در K-means نشان داده شده است.
الگوریتم تغییر میانگین
این یک الگوریتم خوشه بندی قدرتمند دیگری است که در یادگیری بدون نظارت استفاده می شود. برخلاف خوشه بندی K-means ، هیچ فرضی نمی دهد از این رو الگوریتمی غیر پارامتری است.
خوشه بندی سلسله مراتبی
این یک الگوریتم یادگیری بدون نظارت است که برای گروه بندی نقاط داده بدون برچسب با ویژگی های مشابه استفاده می شود.
ما در درس های آینده به طور کامل در مورد همه این الگوریتم ها بحث خواهیم کرد.
کاربرد های خوشه بندی
ما می توانیم خوشه بندی را در مناطق زیر مفید بدانیم –
جمع بندی و فشرده سازی داده ها – خوشه بندی به طور گسترده ای در مناطقی مورد استفاده قرار می گیرد که به جمع بندی ، فشرده سازی و کاهش داده ها نیز نیاز داریم. نمونه ها پردازش تصویر و کمی سازی بردار هستند.
سیستم های مشارکتی و تقسیم بندی مشتری – از آنجا که از خوشه بندی می توان برای یافتن محصولات مشابه یا همان نوع کاربران استفاده کرد ، می توان از آن در زمینه سیستم های مشترک و تقسیم بندی مشتری استفاده کرد.
به عنوان یک مرحله میانی کلیدی برای سایر کارهای داده کاوی انجام می دهد – تجزیه و تحلیل خوشه می تواند خلاصه ای فشرده از داده ها را برای طبقه بندی ، آزمایش ، تولید فرضیه ایجاد کند. از این رو ، به عنوان یک مرحله میانی اصلی برای سایر کارهای داده کاوی نیز عمل می کند.
تشخیص روند در داده های پویا – همچنین می توان از خوشه بندی برای ساخت روند در داده های پویا با ایجاد خوشه های مختلف از روندهای مشابه استفاده کرد.
تجزیه و تحلیل شبکه های اجتماعی – خوشه بندی می تواند در تجزیه و تحلیل شبکه های اجتماعی استفاده شود. مثالها توالیهایی را در تصاویر ، فیلمها یا فایلهای دیداری ایجاد می کنند.
تجزیه و تحلیل داده های بیولوژیکی – همچنین می توان از خوشه بندی برای ایجاد خوشه ای از تصاویر، فیلم ها استفاده کرد از این رو می توان با موفقیت در تجزیه و تحلیل داده های بیولوژیکی استفاده کرد.
لیست جلسات قبل آموزش یادگیری ماشین با پایتون
- آموزش یادگیری ماشین با پایتون
- مبانی یادگیری ماشین با پایتون
- آموزش اکوسیستم یادگیری ماشین با پایتون
- آموزش متدها در یادگیری ماشین با پایتون
- آموزش بارگیری داده ها برای پروژه های یادگیری ماشین
- آموزش درک داده ها با آمار در یادگیری ماشین
- آموزش آماده سازی داده ها در یادگیری ماشین با پایتون
- آموزش انتخاب ویژگی داده ها در یادگیری ماشین با پایتون
- آموزش طبقه بندی در یادگیری ماشین با پایتون
- آموزش رگرسیون لجستیک در یادگیری ماشین با پایتون
- آموزش ماشین بردار پشتیبان در یادگیری ماشین با پایتون
- آموزش درخت تصمیم در یادگیری ماشین با پایتون
- آموزش Naïve Bayes در یادگیری ماشین با پایتون
- آموزش جنگل تصادفی در یادگیری ماشین با پایتون
- آموزش الگوریتم های رگرسیون در یادگیری ماشین با پایتون



.svg)
دیدگاه شما