
آموزش الگوریتم K-Means در یادگیری ماشین با پایتون

آموزش الگوریتم K-Means در یادگیری ماشین با پایتون
در این درس از مجموعه آموزش برنامه نویسی سایت سورس باران، به آموزش الگوریتم K-Means در یادگیری ماشین با پایتون خواهیم پرداخت.
پیشنهاد ویژه : پکیج آموزش صفر تا صد پایتون
مقدمه ای بر الگوریتم K-Means
الگوریتم خوشه بندی K-mean مرکز سانروئیدها را محاسبه می کند و تکرار می شود تا زمانی که مرکز بهینه را پیدا کند. فرض بر این است که تعداد خوشه ها از قبل مشخص است. به آن الگوریتم خوشه بندی مسطح نیز می گویند. تعداد خوشه های مشخص شده از داده ها توسط الگوریتم با ‘K’ در K-means نشان داده شده است.
در این الگوریتم، نقاط داده به گونه ای به یک خوشه اختصاص داده می شوند که مجموع فاصله مربع بین نقاط داده و مرکز گرایش حداقل باشد. این قابل درک است که تنوع کمتر در خوشه ها منجر به ایجاد داده های مشابه بیشتری در درون خوشه می شود.
کار الگوریتم K-Means
ما می توانیم کار الگوریتم خوشه بندی K-Means را با کمک مراحل زیر درک کنیم –
مرحله 1 – ابتدا باید تعداد خوشه های K مشخص شود که باید توسط این الگوریتم تولید شوند.
مرحله 2 – بعد، به طور تصادفی K data را انتخاب کرده و هر نقطه داده را به یک خوشه اختصاص دهید. به عبارت ساده، داده ها را بر اساس تعداد نقاط داده طبقه بندی کنید.
مرحله 3 – اکنون مرکز خوشه ها را محاسبه می کند.
مرحله 4 – سپس، تکرار موارد زیر را ادامه دهید تا زمانی که مرکز بهینه را پیدا کنیم ، یعنی اختصاص نقاط داده به خوشه هایی که دیگر تغییر نمی کنند –
4.1 – ابتدا مجموع فاصله مربع شده بین نقاط داده و سانترویدها محاسبه می شود.
4.2 – اکنون، ما باید هر نقطه داده را به خوشه نزدیک تر از خوشه دیگر (مرکز مرکز) اختصاص دهیم.
4.3 – سرانجام با در نظر گرفتن میانگین تمام نقاط داده آن خوشه، سانترویدها را برای خوشه ها محاسبه کنید.
K-means برای حل مشکل از رویکرد حداکثر انتظار و انتظار پیروی می کند. مرحله Expectation برای تخصیص نقاط داده به نزدیکترین خوشه و مرحله حداکثر برای محاسبه مرکز گرایش هر خوشه استفاده می شود.
در حالی که با الگوریتم K-means کار می کنیم، باید از موارد زیر مراقبت کنیم –
در حالی که با الگوریتم های خوشه بندی از جمله K-Means کار می کنید، توصیه می شود داده ها استاندارد شود زیرا این الگوریتم ها از اندازه گیری مبتنی بر فاصله برای تعیین شباهت بین نقاط داده استفاده می کنند.
با توجه به ماهیت تکراری K-Means و مقداردهی اولیه تصادفی سانترویدها، K-Means ممکن است در یک بهینه محلی بچسبد و ممکن است به بهینه جهانی همگرا نشود. به همین دلیل است که توصیه می شود از مقداردهی اولیه متفاوت سانترویدها استفاده شود.
پیاده سازی در پایتون
دو مثال زیر از اجرای الگوریتم خوشه بندی K-Means به ما در درک بهتر آن کمک می کند –
مثال 1
این یک مثال ساده برای درک نحوه کار k-mean است. در این مثال ، ما قصد داریم ابتدا مجموعه داده 2D را که شامل 4 حباب مختلف است تولید کنیم و پس از آن الگوریتم k-means را برای دیدن نتیجه اعمال خواهیم کرد.
ابتدا، ما با وارد کردن بسته های لازم شروع خواهیم کرد –
|
1 2 3 4 5 6 |
%matplotlib inline import matplotlib.pyplot as plt import seaborn as sns; sns.set() import numpy as np from sklearn.cluster import KMeans |
کد زیر 2D را تولید می کند، شامل چهار حباب –
|
1 2 |
from sklearn.datasets.samples_generator import make_blobs X, y_true = make_blobs(n_samples=400, centers=4, cluster_std=0.60, random_state=0) |
بعد، کد زیر به ما کمک می کند مجموعه داده را تجسم کنیم –
|
1 2 |
plt.scatter(X[:, 0], X[:, 1], s=20); plt.show() |
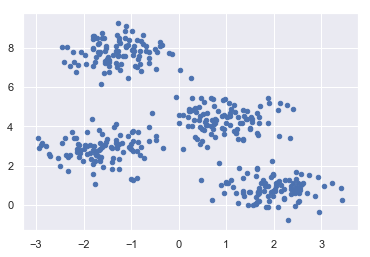
بعد یک شی از KMeans به همراه فراهم کردن تعداد خوشه ، ساخت مدل و پیش بینی به شرح زیر انجام دهید –
|
1 2 3 |
kmeans = KMeans (n_clusters = 4) kmeans.fit (X) y_kmeans = kmeans.predict (X) |
اکنون، با کمک کد زیر می توانیم مراکز خوشه ای را که توسط k-means Python برآورد شده است ترسیم و تجسم کنیم –
|
1 2 3 4 |
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=20, cmap='summer') centers = kmeans.cluster_centers_ plt.scatter(centers[:, 0], centers[:, 1], c='blue', s=100, alpha=0.9); plt.show() |
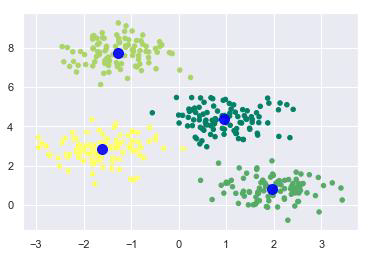
مثال 2
بیایید به یک مثال دیگر برویم که در آن قصد داریم خوشه بندی K-means را روی مجموعه داده های ارقام ساده اعمال کنیم. K-means بدون استفاده از اطلاعات اصلی برچسب ، سعی در شناسایی ارقام مشابه دارد.
ابتدا ، ما با وارد کردن بسته های لازم شروع خواهیم کرد –
|
1 2 3 4 5 6 |
%matplotlib inline import matplotlib.pyplot as plt import seaborn as sns; sns.set() import numpy as np from sklearn.cluster import KMeans |
بعد، مجموعه داده عددی را از sklearn بارگیری کرده و از آن یک شی make درست کنید. همچنین می توانیم تعداد ردیف ها و ستون ها را به صورت زیر در این مجموعه پیدا کنیم –
|
1 2 3 |
from sklearn.datasets import load_digits digits = load_digits() digits.data.shape |
خروجی
|
1 |
(1797, 64) |
خروجی فوق نشان می دهد که این مجموعه داده دارای 1797 نمونه با 64 ویژگی است.
ما می توانیم خوشه بندی را مانند نمونه 1 بالا انجام دهیم –
|
1 2 3 4 5 |
fig, ax = plt.subplots(2, 5, figsize=(8, 3)) centers = kmeans.cluster_centers_.reshape(10, 8, 8) for axi, center in zip(ax.flat, centers): axi.set(xticks=[], yticks=[]) axi.imshow(center, interpolation='nearest', cmap=plt.cm.binary) |
خروجی
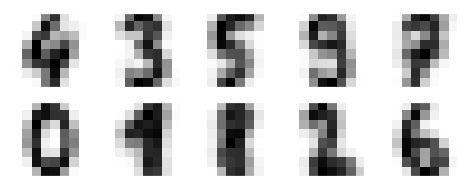
خروجی فوق نشان می دهد که K-means 10 خوشه با 64 ویژگی ایجاد کرده است.
|
1 2 3 4 5 |
from scipy.stats import mode labels = np.zeros_like(clusters) for i in range(10): mask = (clusters == i) labels[mask] = mode(digits.target[mask])[0] |
بعد ، می توانیم دقت را به شرح زیر بررسی کنیم –
|
1 2 |
from sklearn.metrics import accuracy_score accuracy_score(digits.target, labels) |
خروجی
|
1 |
0.7935447968836951 |
خروجی فوق نشان می دهد که دقت حدود 80٪ است.
مزایا و معایب
مزایا:
موارد زیر برخی از مزایای الگوریتم های خوشه بندی K-Means است –
- درک و اجرای آن بسیار آسان است.
- اگر تعداد متغیرهای زیادی داشته باشیم ، K-means سریعتر از خوشه بندی سلسله مراتبی است.
- در محاسبه مجدد centroids ، یک نمونه می تواند خوشه را تغییر دهد.
- خوشه های تنگتر در مقایسه با خوشه بندی سلسله مراتبی با K-means تشکیل می شوند.
معایب
موارد زیر برخی از معایب الگوریتم های خوشه بندی K-Means است –
- پیش بینی تعداد خوشه ها یعنی مقدار k کمی دشوار است.
- ورودی به شدت تحت تأثیر ورودی های اولیه مانند تعداد خوشه ها قرار می گیرد (مقدار k).
- ترتیب داده ها تأثیر زیادی بر خروجی نهایی خواهد داشت.
- نسبت به رسوب گیری بسیار حساس است. اگر داده های خود را با استفاده از نرمال سازی یا استاندارد سازی مجدداً جمع کنیم ، خروجی کاملاً تغییر می کند. خروجی نهایی.
- اگر خوشه ها شکل هندسی پیچیده ای داشته باشند در انجام کار خوشه بندی خوب نیست.
کاربردهای الگوریتم خوشه بندی K-Means
- برای دریافت یک شهود معنادار از داده هایی که ما با آنها کار می کنیم.
- خوشه سپس پیش بینی کنید که مدلهای مختلف برای زیرگروههای مختلف ساخته شود.
- برای تحقق اهداف فوق ، خوشه بندی K-means به اندازه کافی خوب عمل می کند. می تواند در برنامه های زیر استفاده شود –
- تقسیم بندی بازار
- خوشه بندی سند
- تقسیم تصویر
- فشرده سازی تصویر
- تقسیم بندی مشتری
- تجزیه و تحلیل روند داده های پویا
لیست جلسات قبل آموزش یادگیری ماشین با پایتون
- آموزش یادگیری ماشین با پایتون
- مبانی یادگیری ماشین با پایتون
- آموزش اکوسیستم یادگیری ماشین با پایتون
- آموزش متدها در یادگیری ماشین با پایتون
- آموزش بارگیری داده ها برای پروژه های یادگیری ماشین
- آموزش درک داده ها با آمار در یادگیری ماشین
- آموزش آماده سازی داده ها در یادگیری ماشین با پایتون
- آموزش انتخاب ویژگی داده ها در یادگیری ماشین با پایتون
- آموزش طبقه بندی در یادگیری ماشین با پایتون
- آموزش رگرسیون لجستیک در یادگیری ماشین با پایتون
- آموزش ماشین بردار پشتیبان در یادگیری ماشین با پایتون
- آموزش درخت تصمیم در یادگیری ماشین با پایتون
- آموزش Naïve Bayes در یادگیری ماشین با پایتون
- آموزش جنگل تصادفی در یادگیری ماشین با پایتون
- آموزش الگوریتم های رگرسیون در یادگیری ماشین با پایتون
- آموزش الگوریتم های خوشه بندی در یادگیری ماشین با پایتون



.svg)
دیدگاه شما