
آموزش خوشه بندی سلسله مراتبی در یادگیری ماشین با پایتون

آموزش خوشه بندی سلسله مراتبی در یادگیری ماشین با پایتون
در این درس از مجموعه آموزش برنامه نویسی سایت سورس باران، به آموزش خوشه بندی سلسله مراتبی در یادگیری ماشین با پایتون خواهیم پرداخت.
پیشنهاد ویژه : پکیج آموزش پروژه محور پایتون
مقدمه ای بر خوشه بندی سلسله مراتبی
خوشه بندی سلسله مراتبی یکی دیگر از الگوریتم های یادگیری بدون نظارت است که برای گروه بندی نقاط داده بدون برچسب با ویژگی های مشابه استفاده می شود. الگوریتم های خوشه بندی سلسله مراتبی به دو دسته زیر تقسیم می شوند –
الگوریتم های سلسله مراتبی تجمعی – در الگوریتم های سلسله مراتبی تجمعی ، هر نقطه داده به عنوان یک خوشه واحد در نظر گرفته می شود و سپس بطور متوالی جفت خوشه ها را ادغام یا جمع می کند (رویکرد از پایین به بالا). سلسله مراتب خوشه ها به عنوان یک دندروگرام یا ساختار درختی نشان داده می شود.
الگوریتم های سلسله مراتبی تقسیم کننده – از سوی دیگر ، در الگوریتم های سلسله مراتبی تقسیم پذیر ، تمام نقاط داده به عنوان یک خوشه بزرگ در نظر گرفته می شوند و روند خوشه بندی شامل تقسیم (رویکرد از بالا به پایین) خوشه بزرگ به خوشه های کوچک مختلف است.
مراحل انجام خوشه بندی سلسله مراتبی تجمعی
ما قصد داریم بیشترین کاربرد و مهم خوشه بندی سلسله مراتبی یعنی جمع را توضیح دهیم. مراحل انجام همان کار به شرح زیر است –
مرحله 1 – با هر نقطه داده به عنوان یک خوشه واحد رفتار کنید. از این رو، در ابتدا خوشه های K خواهیم گفت. تعداد نقاط داده نیز در شروع K خواهد بود.
مرحله 2 – اکنون، در این مرحله ما باید با پیوستن به دو پایگاه داده کمد ، یک خوشه بزرگ را تشکیل دهیم. این در مجموع خوشه های K-1 خواهد بود.
مرحله 3 – اکنون، برای تشکیل خوشه های بیشتر ، باید دو خوشه کمد را به هم متصل کنیم. این در مجموع خوشه های K-2 خواهد بود.
مرحله 4 – اکنون، برای تشکیل یک خوشه بزرگ ، سه مرحله فوق را تکرار کنید تا K 0 شود ، یعنی دیگر هیچ نقطه داده ای برای پیوستن باقی نماند.
مرحله 5 – سرانجام ، پس از ایجاد یک خوشه بزرگ ، از دندروگرام ها استفاده می شود تا بسته به مشکل به چند خوشه تقسیم شود.
نقش دندروگرام ها در خوشه بندی سلسله مراتبی تجمعی
همانطور که در مرحله آخر بحث کردیم، نقش dendrogram پس از تشکیل خوشه بزرگ شروع می شود. از Dendrogram بسته به مشکل ما برای تقسیم خوشه ها به چندین خوشه از نقاط داده مربوط استفاده می شود. با کمک مثال زیر قابل درک است –
مثال 1
برای درک، بیایید با وارد کردن کتابخانه های مورد نیاز به شرح زیر شروع کنیم –
|
1 2 3 4 |
%matplotlib inline import matplotlib.pyplot as plt import numpy as np |
در مرحله بعدی، نقشه های دیتا پوینتی را که برای این مثال گرفته ایم ترسیم خواهیم کرد –
|
1 2 3 4 5 6 7 8 |
X = np.array([[7,8],[12,20],[17,19],[26,15],[32,37],[87,75],[73,85], [62,80],[73,60],[87,96],]) labels = range(1, 11) plt.figure(figsize=(10, 7)) plt.subplots_adjust(bottom=0.1) plt.scatter(X[:,0],X[:,1], label='True Position') for label, x, y in zip(labels, X[:, 0], X[:, 1]): plt.annotate(label,xy=(x, y), xytext=(-3, 3),textcoords='offset points', ha='right', va='bottom') plt.show() |
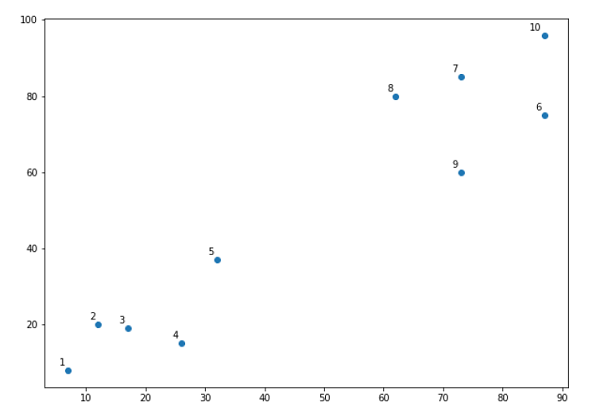
از نمودار بالا ، بسیار آسان می توان فهمید که ما دو خوشه در پایگاه داده داریم ، اما در داده های دنیای واقعی ، هزاران خوشه وجود دارد. در مرحله بعدی ، ما با استفاده از کتابخانه Scipy ، نقشه های dendrograms از داده های خود را ترسیم خواهیم کرد –
|
1 2 3 4 5 6 7 |
from scipy.cluster.hierarchy import dendrogram, linkage from matplotlib import pyplot as plt linked = linkage(X, 'single') labelList = range(1, 11) plt.figure(figsize=(10, 7)) dendrogram(linked, orientation='top',labels=labelList, distance_sort='descending',show_leaf_counts=True) plt.show() |
اکنون پس از تشکیل خوشه بزرگ، بیشترین فاصله عمودی انتخاب می شود. سپس از طریق آن یک خط عمودی رسم می شود همانطور که در نمودار زیر نشان داده شده است. با عبور خط افقی از خط آبی در دو نقطه، تعداد خوشه ها دو عدد خواهد بود.
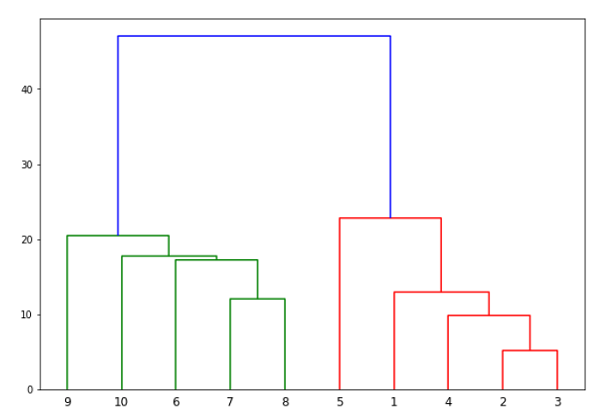
در مرحله بعد ، ما باید کلاس را برای خوشه بندی وارد کنیم و برای پیش بینی خوشه ، روش fit_predict آن را فراخوانی کنیم. ما در حال وارد کردن کلاس AgglomerativeClustering از کتابخانه sklearn.cluster هستیم –
|
1 2 3 |
from sklearn.cluster import AgglomerativeClustering cluster = AgglomerativeClustering(n_clusters=2, affinity='euclidean', linkage='ward') cluster.fit_predict(X) |
بعد، خوشه را با کمک کد زیر ترسیم کنید –
|
1 |
plt.scatter(X[:,0],X[:,1], c=cluster.labels_, cmap='rainbow') |
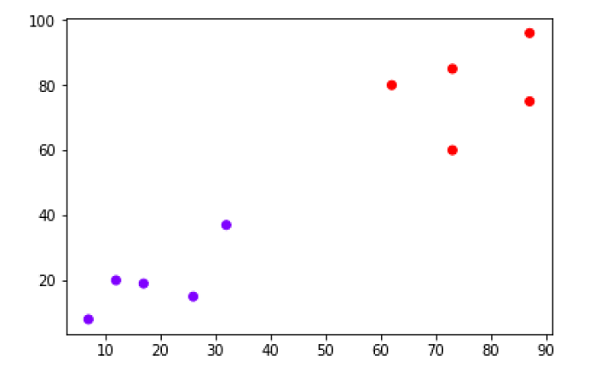
نمودار بالا دو خوشه از پایگاه داده ما را نشان می دهد.
مثال 2
همانطور که مفهوم dendrograms را از مثال ساده بحث شده در بالا درک کردیم ، بیایید به یک مثال دیگر برویم که در آن با استفاده از خوشه بندی سلسله مراتبی خوشه هایی از نقطه داده را در مجموعه داده های دیابت Pima Indian ایجاد می کنیم –
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import matplotlib.pyplot as plt import pandas as pd %matplotlib inline import numpy as np from pandas import read_csv path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=headernames) array = data.values X = array[:,0:8] Y = array[:,8] data.shape (768, 9) data.head() |
| slno. | preg | Plas | Pres | skin | test | mass | pedi | age | class |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33.6 | 0.627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26.6 | 0.351 | 31 | 0 |
| 2 | 8 | 183 | 64 | 0 | 0 | 23.3 | 0.672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28.1 | 0.167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43.1 | 2.288 | 33 | 1 |
|
1 2 3 4 5 |
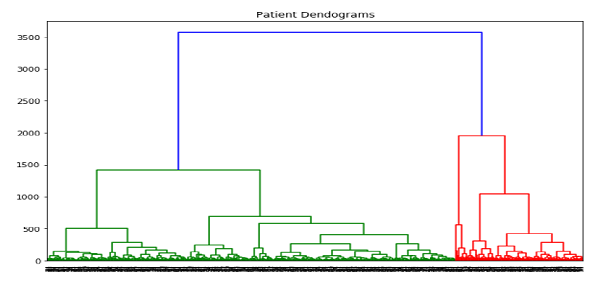
patient_data = data.iloc[:, 3:5].values import scipy.cluster.hierarchy as shc plt.figure(figsize=(10, 7)) plt.title("Patient Dendograms") dend = shc.dendrogram(shc.linkage(data, method='ward')) |
|
1 2 3 4 5 |
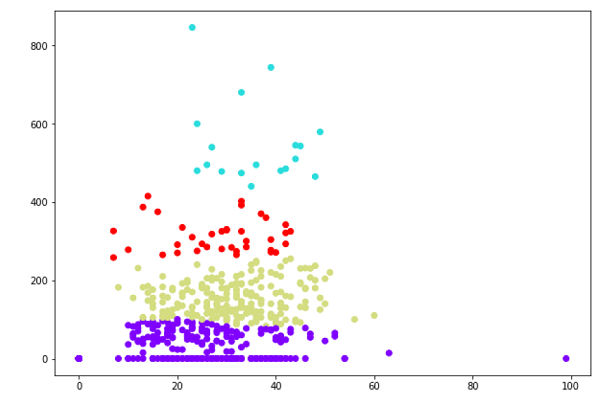
from sklearn.cluster import AgglomerativeClustering cluster = AgglomerativeClustering(n_clusters=4, affinity='euclidean', linkage='ward') cluster.fit_predict(patient_data) plt.figure(figsize=(10, 7)) plt.scatter(patient_data[:,0], patient_data[:,1], c=cluster.labels_, cmap='rainbow') |
لیست جلسات قبل آموزش یادگیری ماشین با پایتون
- آموزش یادگیری ماشین با پایتون
- مبانی یادگیری ماشین با پایتون
- آموزش اکوسیستم یادگیری ماشین با پایتون
- آموزش متدها در یادگیری ماشین با پایتون
- آموزش بارگیری داده ها برای پروژه های یادگیری ماشین
- آموزش درک داده ها با آمار در یادگیری ماشین
- آموزش آماده سازی داده ها در یادگیری ماشین با پایتون
- آموزش انتخاب ویژگی داده ها در یادگیری ماشین با پایتون
- آموزش طبقه بندی در یادگیری ماشین با پایتون
- آموزش رگرسیون لجستیک در یادگیری ماشین با پایتون
- آموزش ماشین بردار پشتیبان در یادگیری ماشین با پایتون
- آموزش درخت تصمیم در یادگیری ماشین با پایتون
- آموزش Naïve Bayes در یادگیری ماشین با پایتون
- آموزش جنگل تصادفی در یادگیری ماشین با پایتون
- آموزش الگوریتم های رگرسیون در یادگیری ماشین با پایتون
- آموزش الگوریتم های خوشه بندی در یادگیری ماشین با پایتون
- آموزش الگوریتم K-Means در یادگیری ماشین با پایتون
- آموزش الگوریتم تغییر میانگین در یادگیری ماشین با پایتون



.svg)
دیدگاه شما