
آموزش یافتن نزدیکترین همسایه در یادگیری ماشین با پایتون

آموزش یافتن نزدیکترین همسایه در یادگیری ماشین با پایتون
در این درس از مجموعه آموزش برنامه نویسی سایت سورس باران، به آموزش یافتن نزدیکترین همسایه در یادگیری ماشین با پایتون خواهیم پرداخت.
پیشنهاد ویژه : پکیج آموزش طراحی وب سایت با پایتون
معرفی نزدیکترین همسایه در یادگیری ماشین با پایتون
الگوریتم K-نزدیکترین همسایه (KNN) نوعی الگوریتم تحت نظارت ML است که می تواند هم برای طبقه بندی و هم برای مشکلات پیش بینی رگرسیون استفاده شود. با این حال ، عمدتا برای طبقه بندی مشکلات پیش بینی در صنعت استفاده می شود. دو ویژگی زیر KNN را به خوبی تعریف می کنند –
الگوریتم یادگیری تنبل – KNN یک الگوریتم یادگیری تنبل است زیرا فاز آموزشی خاصی ندارد و در هنگام طبقه بندی از تمام داده ها برای آموزش استفاده می کند.
الگوریتم یادگیری غیرپارامتری – KNN همچنین یک الگوریتم یادگیری غیرپارامتری است زیرا در مورد داده های اساسی چیزی فرض نمی کند.
کار الگوریتم KNN
الگوریتم K-نزدیکترین همسایه (KNN) از “شباهت ویژگی” برای پیش بینی مقادیر جدید پایگاه داده استفاده می کند که بیشتر بدان معنی است که به نقطه داده جدید یک مقدار اختصاص داده می شود بر اساس میزان مطابقت آن با نقاط مجموعه آموزش. ما می توانیم با کمک مراحل زیر کار آن را درک کنیم –
مرحله 1 – برای پیاده سازی هر الگوریتم، ما به مجموعه داده نیاز داریم. بنابراین در مرحله اول KNN ، ما باید آموزش و همچنین داده های آزمون را بارگیری کنیم.
مرحله 2 – بعد، ما باید مقدار K یعنی نزدیکترین نقاط داده را انتخاب کنیم. K می تواند هر عدد صحیحی باشد.
مرحله 3 – برای هر نقطه از داده های آزمون موارد زیر را انجام دهید –
3.1 – فاصله بین داده های آزمون و هر ردیف از داده های آموزش را با کمک هر یک از روش ها یعنی فاصله اقلیدسی ، منهتن یا همینگ محاسبه کنید. متداول ترین روش برای محاسبه فاصله اقلیدسی است.
3.2 – اکنون بر اساس مقدار فاصله ، آنها را به ترتیب صعودی مرتب کنید.
3.3 – بعد ، ردیف های بالای K را از آرایه مرتب شده انتخاب می کند.
3.4 – اکنون، یک کلاس را به نقطه آزمون بر اساس کلاس بیشتر از این ردیف ها اختصاص می دهد.
مرحله 4 – پایان
مثال
مثال زیر مثالی برای درک مفهوم K و کارکرد الگوریتم KNN است –
فرض کنید یک مجموعه داده داریم که می تواند به صورت زیر ترسیم شود –
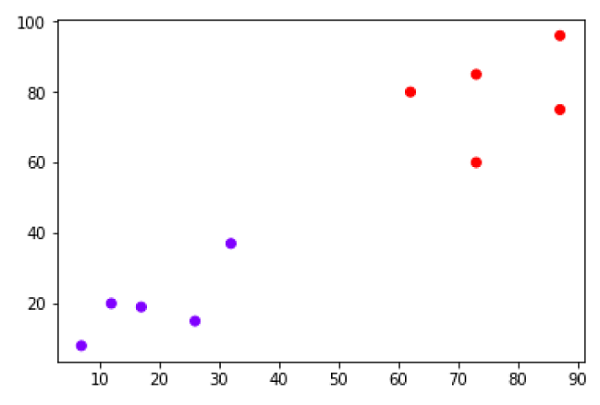
اکنون ما باید نقطه داده جدید را با نقطه سیاه (در نقطه 60،60) به کلاس آبی یا قرمز طبقه بندی کنیم. ما فرض می کنیم K = 3 یعنی سه نقطه داده نزدیک را پیدا می کند. این در نمودار بعدی نشان داده شده است –
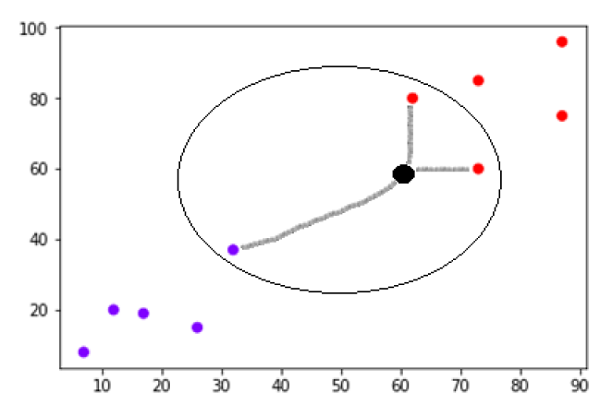
در نمودار بالا می توان سه نزدیکترین همسایه نقطه داده را با نقطه سیاه مشاهده کرد. در میان این سه ، دو مورد از آنها در کلاس Red قرار دارند ، بنابراین نقطه سیاه نیز در کلاس قرمز تعیین می شود.
پیاده سازی در پایتون
همانطور که می دانیم الگوریتم K-نزدیکترین همسایه (KNN) می تواند هم برای طبقه بندی و هم برای رگرسیون استفاده شود. در زیر دستورالعمل های موجود در پایتون برای استفاده از KNN به عنوان طبقه بندی و همچنین رگرسیون وجود دارد –
KNN به عنوان طبقه بندی کننده
ابتدا با وارد کردن بسته های لازم پایتون شروع کنید –
|
1 2 3 |
import numpy as np import matplotlib.pyplot as plt import pandas as pd |
سپس، مجموعه داده iris را از لینک وب خود به شرح زیر بارگیری کنید –
|
1 |
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data" |
در مرحله بعد، باید نام ستون ها را به شرح زیر به مجموعه داده اختصاص دهیم –
|
1 |
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data" |
اکنون ، ما باید مجموعه داده ها را برای pandas dataframe به شرح زیر بخوانیم –
|
1 |
headernames = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class'] |
| slno. | sepal-length | sepal-width | petal-length | petal-width | Class |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
پیش پردازش داده ها با کمک خطوط زیر انجام می شود –
|
1 2 |
X = dataset.iloc[:, :-1].values y = dataset.iloc[:, 4].values |
بعد ، ما داده ها را به تقسیم قطار و آزمون تقسیم می کنیم. کد زیر مجموعه داده را به 60٪ داده های آموزشی و 40٪ داده های آزمایش تقسیم می کند –
|
1 2 |
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.40) |
بعد مقیاس گذاری داده ها به شرح زیر انجام می شود –
|
1 2 3 4 5 |
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() scaler.fit(X_train) X_train = scaler.transform(X_train) X_test = scaler.transform(X_test) |
بعد مدل را با کمک کلاس KNeighboursClassifier از sklearn به شرح زیر آموزش دهید –
|
1 2 3 |
from sklearn.neighbors import KNeighborsClassifier classifier = KNeighborsClassifier(n_neighbors=8) classifier.fit(X_train, y_train) |
بالاخره ما باید پیش بینی کنیم. این را می توان با کمک اسکریپت زیر انجام داد –
|
1 |
y_pred = classifier.predict(X_test) |
بعد نتایج را به شرح زیر چاپ کنید –
|
1 2 3 4 5 6 7 8 9 |
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score result = confusion_matrix(y_test, y_pred) print("Confusion Matrix:") print(result) result1 = classification_report(y_test, y_pred) print("Classification Report:",) print (result1) result2 = accuracy_score(y_test,y_pred) print("Accuracy:",result2) |
خروجی
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Confusion Matrix: [[21 0 0] [ 0 16 0] [ 0 7 16]] Classification Report: precision recall f1-score support Iris-setosa 1.00 1.00 1.00 21 Iris-versicolor 0.70 1.00 0.82 16 Iris-virginica 1.00 0.70 0.82 23 micro avg 0.88 0.88 0.88 60 macro avg 0.90 0.90 0.88 60 weighted avg 0.92 0.88 0.88 60 Accuracy: 0.8833333333333333 |
KNN به عنوان Regressor
ابتدا با وارد کردن بسته های لازم پایتون شروع کنید –
|
1 2 |
import numpy as np import pandas as pd |
سپس ، مجموعه داده iris را از لینک وب خود به شرح زیر بارگیری کنید –
|
1 |
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data" |
در مرحله بعد ، باید نام ستون ها را به شرح زیر به مجموعه داده اختصاص دهیم –
|
1 |
headernames = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class'] |
اکنون ، ما باید مجموعه داده ها را برای pandas dataframe به شرح زیر بخوانیم –
|
1 2 3 4 5 6 7 |
data = pd.read_csv(url, names=headernames) array = data.values X = array[:,:2] Y = array[:,2] data.shape output:(150, 5) |
بعد ، KNeighbursRegressor را از sklearn وارد کنید تا متناسب با مدل باشد –
|
1 2 3 |
from sklearn.neighbors import KNeighborsRegressor knnr = KNeighborsRegressor(n_neighbors=10) knnr.fit(X, y) |
سرانجام ، ما می توانیم MSE را به شرح زیر پیدا کنیم –
|
1 |
print ("The MSE is:",format(np.power(y-knnr.predict(X),2).mean())) |
خروجی
|
1 |
The MSE is: 0.12226666666666669 |
جوانب مثبت و منفی KNN
جوانب مثبت
- درک و تفسیر آن الگوریتم بسیار ساده ای است.
- برای داده های غیرخطی بسیار مفید است زیرا در این الگوریتم هیچ فرضی در مورد داده وجود ندارد.
- این یک الگوریتم همه کاره است زیرا می توانیم از آن برای طبقه بندی و همچنین رگرسیون استفاده کنیم.
- این دقت نسبتاً بالایی دارد اما مدلهای یادگیری تحت نظارت بسیار بهتری نسبت به KNN وجود دارد.
جوانب منفی
- از نظر محاسباتی الگوریتمی کمی گران است زیرا تمام داده های آموزش را در خود ذخیره می کند.
- ذخیره سازی حافظه بالا در مقایسه با سایر الگوریتم های یادگیری تحت نظارت مورد نیاز است.
- در صورت بزرگ بودن N پیش بینی کند است.
- نسبت به مقیاس داده ها و همچنین ویژگی های نامرتبط بسیار حساس است.
کاربردهای KNN
موارد زیر برخی از مناطقی است که می توان KNN را با موفقیت به کار برد –
سیستم بانکی
از KNN می توان در سیستم بانکی برای پیش بینی شرایط مناسب برای تأیید وام استفاده کرد؟ آیا آن فرد دارای خصوصیاتی مشابه ویژگی پیش فرض است؟
محاسبه رتبه بندی اعتبار
از الگوریتم های KNN می توان با مقایسه با افراد دارای صفات مشابه ، رتبه اعتباری فرد را پیدا کرد.
سیاست
با کمک الگوریتم های KNN ، ما می توانیم یک رأی دهنده بالقوه را در کلاس های مختلف مانند “رأی می دهد” ، “رأی نمی دهد” ، “رأی به حزب” کنگره “،” رأی به حزب “BJP” طبقه بندی می کنیم.
زمینه های دیگر که می توان از الگوریتم KNN در آنها استفاده کرد ، گفتار ، تشخیص دست خط ، تشخیص تصویر و تشخیص فیلم است.
لیست جلسات قبل آموزش یادگیری ماشین با پایتون
- آموزش یادگیری ماشین با پایتون
- مبانی یادگیری ماشین با پایتون
- آموزش اکوسیستم یادگیری ماشین با پایتون
- آموزش متدها در یادگیری ماشین با پایتون
- آموزش بارگیری داده ها برای پروژه های یادگیری ماشین
- آموزش درک داده ها با آمار در یادگیری ماشین
- آموزش آماده سازی داده ها در یادگیری ماشین با پایتون
- آموزش انتخاب ویژگی داده ها در یادگیری ماشین با پایتون
- آموزش طبقه بندی در یادگیری ماشین با پایتون
- آموزش رگرسیون لجستیک در یادگیری ماشین با پایتون
- آموزش ماشین بردار پشتیبان در یادگیری ماشین با پایتون
- آموزش درخت تصمیم در یادگیری ماشین با پایتون
- آموزش Naïve Bayes در یادگیری ماشین با پایتون
- آموزش جنگل تصادفی در یادگیری ماشین با پایتون
- آموزش الگوریتم های رگرسیون در یادگیری ماشین با پایتون
- آموزش الگوریتم های خوشه بندی در یادگیری ماشین با پایتون
- آموزش الگوریتم K-Means در یادگیری ماشین با پایتون
- آموزش الگوریتم تغییر میانگین در یادگیری ماشین با پایتون
- آموزش خوشه بندی سلسله مراتبی در یادگیری ماشین با پایتون



.svg)
دیدگاه شما