
آموزش معیارهای عملکرد در یادگیری ماشین با پایتون

آموزش معیارهای عملکرد در یادگیری ماشین با پایتون
در این درس از مجموعه آموزش برنامه نویسی سایت سورس باران، به آموزش معیارهای عملکرد در یادگیری ماشین با پایتون خواهیم پرداخت.
پیشنهاد ویژه : پکیج آموزش پایتون مختص بازار کار
معیارهای مختلفی وجود دارد که می توانیم برای ارزیابی عملکرد الگوریتم های ML ، طبقه بندی و همچنین الگوریتم های رگرسیون استفاده کنیم. ما باید با دقت معیارهای ارزیابی عملکرد ML را انتخاب کنیم زیرا –
نحوه اندازه گیری و مقایسه عملکرد الگوریتم های ML کاملاً به معیاری که شما انتخاب می کنید بستگی خواهد داشت.
اینکه شما چگونه اهمیت ویژگیهای مختلف را در نتیجه وزن می کنید کاملاً تحت تأثیر معیاری قرار می گیرد که انتخاب می کنید.
معیارهای عملکرد در یادگیری ماشین با پایتون برای مشکلات طبقه بندی
ما در درس های قبلی در مورد طبقه بندی و الگوریتم های آن بحث کرده ایم. در اینجا، ما می خواهیم معیارهای مختلف عملکردی را که می تواند برای ارزیابی پیش بینی مشکلات طبقه بندی استفاده شود ، مورد بحث قرار دهیم.
ماتریس سردرگمی
این ساده ترین راه برای اندازه گیری عملکرد یک مشکل طبقه بندی است که در آن خروجی می تواند از دو یا چند نوع کلاس باشد. ماتریس سردرگمی چیزی نیست جز یک جدول با دو بعد یعنی. “واقعی” و “پیش بینی شده” و بعلاوه ، هر دو بعد دارای “مثبت مثبت (TP)” ، “منفی واقعی (TN)” ، “مثبت کاذب (FP)” ، “منفی کاذب (FN)” هستند که در زیر نشان داده شده است –
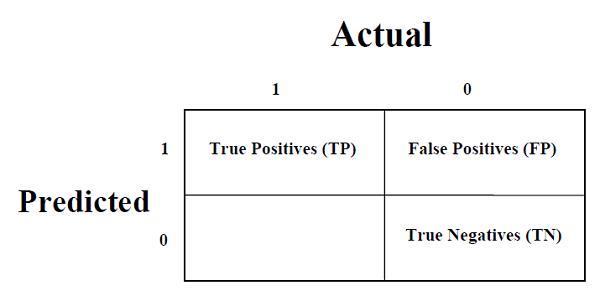
توضیح اصطلاحات مرتبط با ماتریس سردرگمی به شرح زیر است –
مثبت های واقعی (TP) – این مورد زمانی است که هر دو کلاس واقعی و کلاس پیش بینی شده از نقطه داده 1 باشد.
منفی واقعی (TN) – این مورد زمانی است که هر دو کلاس واقعی و کلاس پیش بینی شده داده ها 0 باشد.
مثبت کاذب (FP) – این موردی است که کلاس واقعی نقطه داده 0 و کلاس پیش بینی شده نقطه 1 باشد.
منفی های کاذب (FN) – این مورد زمانی است که کلاس واقعی نقطه داده 1 و کلاس پیش بینی شده نقطه 0 باشد.
ما می توانیم از تابع confusion_matrix sklearn.metrics برای محاسبه ماتریس سردرگمی مدل طبقه بندی خود استفاده کنیم.
دقت طبقه بندی
این متداول ترین معیار عملکرد برای الگوریتم های طبقه بندی است. این ممکن است به عنوان تعداد پیش بینی های صحیح ساخته شده به عنوان نسبت تمام پیش بینی های انجام شده تعریف شود. ما می توانیم به راحتی با کمک فرمول زیر آن را با ماتریس سردرگمی محاسبه کنیم –
Accuracy=TP+TNTP+FP+FN+TN
ما می توانیم برای محاسبه دقت مدل طبقه بندی خود از عملکرد Scorearn.metore sklearn.metrics استفاده کنیم.
گزارش طبقه بندی
این گزارش از امتیازات دقیق ، فراخوان ، F1 و پشتیبانی تشکیل شده است. آنها به شرح زیر توضیح داده می شوند –
دقت
دقت، مورد استفاده در بازیابی اسناد ، ممکن است به عنوان تعداد اسناد صحیح برگشتی توسط مدل ML ما تعریف شود. ما می توانیم به راحتی با کمک فرمول زیر آن را با ماتریس سردرگمی محاسبه کنیم –
Precision=TPTP+FP
یادآوری یا حساسیت
یادآوری ممکن است به عنوان تعداد مثبت برگردانده شده توسط مدل ML ما تعریف شود. ما می توانیم به راحتی با کمک فرمول زیر آن را با ماتریس سردرگمی محاسبه کنیم –
Recall=TPTP+FN
ویژگی
ویژگی برخلاف یادآوری ، ممکن است به عنوان تعداد منفی برگردانده شده توسط مدل ML ما تعریف شود. ما می توانیم به راحتی با کمک فرمول زیر آن را با ماتریس سردرگمی محاسبه کنیم –
Specificity=TNTN+FP
پشتیبانی
پشتیبانی ممکن است به عنوان تعدادی از نمونه های پاسخ واقعی که در هر کلاس از مقادیر هدف نهفته است ، تعریف شود.
نمره F1
این نمره میانگین هارمونیک دقت و یادآوری را به ما می دهد. از نظر ریاضی ، نمره F1 میانگین وزنی دقت و فراخوان است. بهترین مقدار F1 1 و بدترین مقدار 0 خواهد بود. ما می توانیم نمره F1 را با کمک فرمول زیر محاسبه کنیم –
𝑭𝟏 = 𝟐 ∗ (𝒑𝒓𝒆𝒄𝒊𝒔𝒊𝒐𝒏 ∗ 𝒓𝒆𝒄𝒂𝒍𝒍) / (𝒑𝒓𝒆𝒄𝒊𝒔𝒊𝒐𝒏 + 𝒓𝒆𝒄𝒂𝒍𝒍)
نمره F1 دارای سهم نسبی برابر با دقت و فراخوان است.
برای بدست آوردن گزارش طبقه بندی مدل طبقه بندی خود می توانیم از تابع classification_report از sklearn.metrics استفاده کنیم.
AUC (منطقه تحت منحنی ROC)
AUC (Area under Curve) -ROC (مشخصه عملیاتی گیرنده) معیار عملکردی است که بر اساس مقادیر آستانه متفاوت برای مشکلات طبقه بندی تنظیم شده است. همانطور که از نامش پیداست ، ROC یک منحنی احتمال است و AUC قابلیت تفکیک را اندازه گیری می کند. به عبارت ساده تر ، معیار AUC-ROC در مورد توانایی مدل در تشخیص کلاس ها به ما می گوید. AUC بالاتر ، مدل بهتر است.
از نظر ریاضی ، می توان با رسم TPR (نرخ مثبت واقعی) یعنی حساسیت یا فراخوان در مقابل FPR (نرخ مثبت کاذب) یعنی 1-ویژگی ، در مقادیر مختلف آستانه. در زیر نمودار ROC ، AUC با TPR در محور y و FPR در محور x نشان داده شده است –
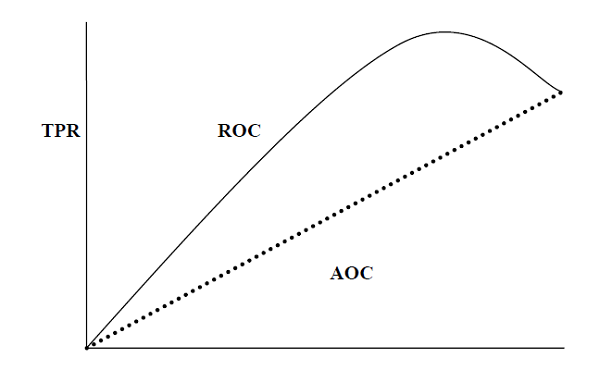
برای محاسبه AUC-ROC می توانیم از تابع roc_auc_score sklearn.metrics استفاده کنیم.
LOGLOSS
همچنین به آن افت رگرسیون لجستیک یا از بین رفتن آنتروپی متقابل می گویند. این اساساً بر اساس تخمین احتمالات تعریف شده و عملکرد یک مدل طبقه بندی را اندازه گیری می کند که در آن ورودی یک مقدار احتمال بین 0 تا 1 است. با تمایز با دقت، می توان آن را به وضوح درک کرد. همانطور که می دانیم دقت، تعداد پیش بینی ها (مقدار پیش بینی شده = مقدار واقعی) در مدل ما است در حالیکه Log Loss میزان عدم اطمینان پیش بینی ما بر اساس میزان تفاوت آن با برچسب واقعی است. با کمک مقدار Log Loss، می توانیم بیشتر داشته باشیم
مثال
در زیر یک دستورالعمل ساده در پایتون وجود دارد که به ما درک می کند که چگونه می توانیم از معیارهای عملکرد توضیح داده شده در بالا در مدل طبقه بندی باینری استفاده کنیم –
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
from sklearn.metrics import confusion_matrix from sklearn.metrics import accuracy_score from sklearn.metrics import classification_report from sklearn.metrics import roc_auc_score from sklearn.metrics import log_loss X_actual = [1, 1, 0, 1, 0, 0, 1, 0, 0, 0] Y_predic = [1, 0, 1, 1, 1, 0, 1, 1, 0, 0] results = confusion_matrix(X_actual, Y_predic) print ('Confusion Matrix :') print(results) print ('Accuracy Score is',accuracy_score(X_actual, Y_predic)) print ('Classification Report : ') print (classification_report(X_actual, Y_predic)) print('AUC-ROC:',roc_auc_score(X_actual, Y_predic)) print('LOGLOSS Value is',log_loss(X_actual, Y_predic)) |
خروجی
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Confusion Matrix : [ [3 3] [1 3] ] Accuracy Score is 0.6 Classification Report : precision recall f1-score support 0 0.75 0.50 0.60 6 1 0.50 0.75 0.60 4 micro avg 0.60 0.60 0.60 10 macro avg 0.62 0.62 0.60 10 weighted avg 0.65 0.60 0.60 10 AUC-ROC: 0.625 LOGLOSS Value is 13.815750437193334 |
معیارهای عملکرد در یادگیری ماشین با پایتون برای مشکلات رگرسیون
ما در درس های گذشته در مورد رگرسیون و الگوریتم های آن بحث کرده ایم. در اینجا ، ما می خواهیم معیارهای مختلف عملکردی را که می تواند برای ارزیابی پیش بینی مشکلات رگرسیون استفاده شود ، مورد بحث قرار دهیم.
میانگین خطای مطلق (MAE)
این ساده ترین معیار خطا است که در مشکلات رگرسیون استفاده می شود. در اصل مجموع میانگین اختلاف مطلق بین مقادیر پیش بینی شده و واقعی است. به عبارت ساده تر ، با MAE می توان تصور کرد که پیش بینی ها چقدر اشتباه بوده است. MAE جهت مدل را نشان نمی دهد ، یعنی هیچ نشانه ای در مورد کم عملکرد یا عملکرد بیش از حد مدل وجود ندارد. فرمول زیر برای محاسبه MAE است:
MAE=1n∑|Y−Y^|
در اینجا ، 𝑌 = مقادیر واقعی خروجی
و Y ^ = مقادیر خروجی پیش بینی شده.
برای محاسبه MAE می توانیم از تابع error_absolute_error sklearn.metrics استفاده کنیم.
خطای میانگین مربع (MSE)
MSE مانند MAE است ، اما تنها تفاوت این است که تفاوت مقادیر واقعی و پیش بینی شده خروجی را قبل از جمع کردن همه به جای استفاده از مقدار مطلق ، مربع می کند. تفاوت را می توان در معادله زیر مشاهده کرد –
MSE = 1n∑ (Y − Y ^)
در اینجا ، 𝑌 = مقادیر واقعی خروجی
و Y ^ = مقادیر خروجی پیش بینی شده.
برای محاسبه MSE می توانیم از تابع error_squared_error sklearn.metrics استفاده کنیم.
R مربع (R2)
متریک R Squared به طور کلی برای اهداف توضیحی استفاده می شود و نشانه ای از خوبی یا تناسب مجموعه ای از مقادیر خروجی پیش بینی شده با مقادیر خروجی واقعی را ارائه می دهد. فرمول زیر به ما در درک آن کمک می کند –
R2 = 1−1n∑ni = 1 (Yi − Yi ^) 21n∑ni = 1 (Yi − Yi) 2¯
در معادله فوق ، عدد MSE و مخرج واریانس مقادیر است.
ما می توانیم از تابع r2_score sklearn.metrics برای محاسبه مقدار مربع R استفاده کنیم.
مثال
در زیر یک دستورالعمل ساده در پایتون وجود دارد که به ما درک می کند که چگونه می توانیم از معیارهای عملکرد توضیح داده شده در بالا در مدل رگرسیون استفاده کنیم –
|
1 2 3 4 5 6 7 8 |
from sklearn.metrics import r2_score from sklearn.metrics import mean_absolute_error from sklearn.metrics import mean_squared_error X_actual = [5, -1, 2, 10] Y_predic = [3.5, -0.9, 2, 9.9] print ('R Squared =',r2_score(X_actual, Y_predic)) print ('MAE =',mean_absolute_error(X_actual, Y_predic)) print ('MSE =',mean_squared_error(X_actual, Y_predic)) |
خروجی
|
1 2 3 |
R Squared = 0.9656060606060606 MAE = 0.42499999999999993 MSE = 0.5674999999999999 |
لیست جلسات قبل آموزش یادگیری ماشین با پایتون
- آموزش یادگیری ماشین با پایتون
- مبانی یادگیری ماشین با پایتون
- آموزش اکوسیستم یادگیری ماشین با پایتون
- آموزش متدها در یادگیری ماشین با پایتون
- آموزش بارگیری داده ها برای پروژه های یادگیری ماشین
- آموزش درک داده ها با آمار در یادگیری ماشین
- آموزش آماده سازی داده ها در یادگیری ماشین با پایتون
- آموزش انتخاب ویژگی داده ها در یادگیری ماشین با پایتون
- آموزش طبقه بندی در یادگیری ماشین با پایتون
- آموزش رگرسیون لجستیک در یادگیری ماشین با پایتون
- آموزش ماشین بردار پشتیبان در یادگیری ماشین با پایتون
- آموزش درخت تصمیم در یادگیری ماشین با پایتون
- آموزش Naïve Bayes در یادگیری ماشین با پایتون
- آموزش جنگل تصادفی در یادگیری ماشین با پایتون
- آموزش الگوریتم های رگرسیون در یادگیری ماشین با پایتون
- آموزش الگوریتم های خوشه بندی در یادگیری ماشین با پایتون
- آموزش الگوریتم K-Means در یادگیری ماشین با پایتون
- آموزش الگوریتم تغییر میانگین در یادگیری ماشین با پایتون
- آموزش خوشه بندی سلسله مراتبی در یادگیری ماشین با پایتون
- آموزش یافتن نزدیکترین همسایه در یادگیری ماشین با پایتون
یک دیدگاه
-
shahla
3 سال پیشمطالب خوب و مفیدی بود.ممنون از زحمات شما



.svg)
دیدگاه شما