
آموزش گردش کار خودکار در یادگیری ماشین با پایتون

آموزش گردش کار خودکار در یادگیری ماشین با پایتون
در این درس از مجموعه آموزش برنامه نویسی سایت سورس باران، به آموزش گردش کار خودکار در یادگیری ماشین با پایتون خواهیم پرداخت.
پیشنهاد ویژه : پکیج آموزش صفر تا صد پایتون
معرفی گردش کار خودکار در یادگیری ماشین با پایتون
برای اجرای موفقیت آمیز و تولید نتایج ، یک مدل یادگیری ماشین باید برخی از گردش های استاندارد را خودکار کند. روند خودکار سازی این گردش کار استاندارد با کمک Scikit-learn Pipelines انجام می شود. از دیدگاه دانشمند داده ، خط لوله یک مفهوم تعمیم یافته ، اما بسیار مهم است. در اصل اجازه می دهد تا جریان داده ها از قالب خام خود به برخی از اطلاعات مفید برسد. کار خطوط لوله را می توان با کمک نمودار زیر درک کرد –
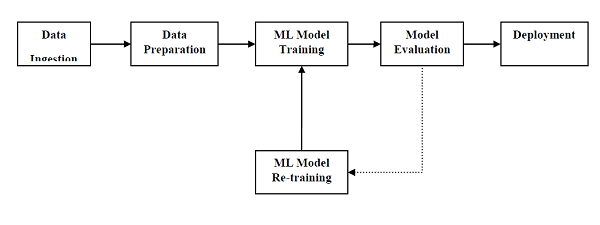
بلوک های خطوط لوله ML به شرح زیر است –
مصرف داده – همانطور که از نام آن مشخص است ، این فرآیند وارد کردن داده ها برای استفاده در پروژه ML است. داده ها را می توان در زمان واقعی یا دسته ای از سیستم های تک یا چندگانه استخراج کرد. این یکی از چالش برانگیزترین مراحل است زیرا کیفیت داده می تواند کل مدل ML را تحت تأثیر قرار دهد.
آماده سازی داده ها – پس از وارد کردن داده ها ، ما باید داده ها را برای استفاده برای مدل ML آماده کنیم. پیش پردازش داده ها یکی از مهمترین تکنیک های آماده سازی داده ها است.
آموزش مدل ML – گام بعدی آموزش مدل ML است. ما الگوریتم های مختلف ML داریم مانند تقویت شده تحت نظارت ، بدون نظارت ، برای استخراج ویژگی ها از داده ها و پیش بینی ها.
ارزیابی مدل – بعد ، ما باید مدل ML را ارزیابی کنیم. در صورت خط لوله AutoML ، مدل ML را می توان با کمک روشهای آماری مختلف و قوانین تجاری ارزیابی کرد.
آموزش مجدد مدل ML – در صورت خط لوله AutoML ، لازم نیست که مدل اول بهترین باشد. اولین مدل به عنوان یک مدل پایه در نظر گرفته می شود و ما می توانیم آن را تکرار کنیم تا دقت مدل را افزایش دهیم.
استقرار – سرانجام ما باید مدل را مستقر کنیم. این مرحله شامل استفاده و انتقال مدل به عملیات تجاری برای استفاده از آنها است.
چالش های همراه خطوط لوله ML
به منظور ایجاد خطوط لوله ML، دانشمندان داده با چالش های زیادی روبرو هستند. این چالش ها به سه دسته زیر تقسیم می شوند –
کیفیت داده ها
موفقیت هر مدل ML بستگی زیادی به کیفیت داده ها دارد. اگر داده هایی که ما به مدل ML ارائه می دهیم دقیق ، قابل اعتماد و قوی نباشند ، ما با خروجی اشتباه یا گمراه کننده به پایان خواهیم رسید.
قابلیت اطمینان داده ها
چالش دیگر مرتبط با خطوط لوله ML قابلیت اطمینان داده هایی است که ما در مدل ML ارائه می دهیم. همانطور که می دانیم ، منابع مختلفی می تواند وجود داشته باشد که دانشمند داده می تواند از آنها داده بدست آورد اما برای گرفتن بهترین نتیجه ، باید اطمینان داشت که منابع داده قابل اعتماد و قابل اعتماد هستند.
قابلیت دسترسی به داده ها
برای به دست آوردن بهترین نتیجه از خطوط لوله ML ، داده ها باید خود قابل دسترسی باشند که به تلفیق، پاکسازی و نظارت بر داده ها نیاز دارد. در نتیجه ویژگی دسترسی به داده ها ، فراداده ها با برچسب های جدید به روز می شوند.
مدل سازی خط لوله ML و آماده سازی داده ها
نشت داده ها، رخ داده از مجموعه داده های آموزشی به آزمایش مجموعه داده ها ، مسئله مهمی است که دانشمند داده باید هنگام تهیه داده ها برای مدل ML با آن مقابله کند. به طور کلی ، در زمان آماده سازی داده ها ، دانشمند داده قبل از یادگیری از تکنیک هایی مانند استاندارد سازی یا عادی سازی روی کل مجموعه داده استفاده می کند. اما این تکنیک ها نمی توانند ما را از نشت داده ها یاری دهند زیرا مجموعه داده های آموزشی تحت تأثیر مقیاس داده های مجموعه داده های آزمایشی قرار گرفته اند.
با استفاده از خطوط لوله ML ، می توانیم از این نشت داده جلوگیری کنیم ، زیرا خطوط لوله اطمینان می دهند که آماده سازی داده ها مانند استاندارد در هر یک از مراحل اعتبار سنجی ما محدود شده است.
مثال
مثال زیر مثالی در پایتون است که آماده سازی داده ها و روند کار ارزیابی مدل را نشان می دهد. برای این منظور ، ما از مجموعه داده های Pima Indian Diabetes از Sklearn استفاده می کنیم. ابتدا خط لوله ای ایجاد خواهیم کرد که داده ها را استاندارد کند. سپس یک مدل تجزیه و تحلیل افتراقی خطی ایجاد می شود و در آخر خط لوله با استفاده از اعتبار صلیبی 10 برابر ارزیابی می شود.
ابتدا بسته های مورد نیاز را به شرح زیر وارد کنید –
|
1 2 3 4 5 6 |
from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.preprocessing import StandardScaler from sklearn.pipeline import Pipeline from sklearn.discriminant_analysis import LinearDiscriminantAnalysis |
اکنون، ما باید مجموعه داده های دیابت پیما را بارگیری کنیم ، همانطور که در مثال های قبلی انجام شد –
|
1 2 3 4 |
path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=headernames) array = data.values |
بعد ما با کمک کد زیر خط لوله ایجاد خواهیم کرد –
|
1 2 3 4 |
estimators = [] estimators.append(('standardize', StandardScaler())) estimators.append(('lda', LinearDiscriminantAnalysis())) model = Pipeline(estimators) |
سرانجام ما می خواهیم این خط لوله را ارزیابی کنیم و صحت آن را به شرح زیر تولید کنیم –
|
1 2 3 |
kfold = KFold(n_splits=20, random_state=7) results = cross_val_score(model, X, Y, cv=kfold) print(results.mean()) |
خروجی
|
1 |
0.7790148448043184 |
خروجی فوق خلاصه ای از صحت تنظیمات روی مجموعه داده است.
مدل سازی خط لوله ML و استخراج ویژگی
نشت داده همچنین می تواند در مرحله استخراج ویژگی مدل ML رخ دهد. به همین دلیل روش های استخراج ویژگی نیز باید محدود شود تا نشت داده ها در مجموعه داده های آموزشی ما متوقف شود. همانطور که در مورد تهیه داده ها ، با استفاده از خطوط لوله ML ، می توانیم از این نشت داده ها نیز جلوگیری کنیم. FeatureUnion ، ابزاری که توسط خطوط لوله ML ارائه می شود می تواند برای این منظور استفاده شود.
مثال
مثال زیر مثالی در پایتون است که استخراج ویژگی و گردش کار ارزیابی مدل را نشان می دهد. برای این منظور ، ما از مجموعه داده های Pima Indian Diabetes از Sklearn استفاده می کنیم.
ابتدا 3 ویژگی با PCA (تجزیه و تحلیل مonلفه اصلی) استخراج می شود. سپس ، 6 ویژگی با تجزیه و تحلیل آماری استخراج خواهد شد. پس از استخراج ویژگی ، نتیجه انتخاب چندین ویژگی و روش های استخراج با استفاده از ترکیب می شود
ابزار FeatureUnion. سرانجام ، یک مدل رگرسیون لجستیک ایجاد می شود و خط لوله با استفاده از اعتبار صحیح 10 برابر ارزیابی می شود.
ابتدا بسته های مورد نیاز را به شرح زیر وارد کنید –
|
1 2 3 4 5 6 7 8 |
from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.pipeline import Pipeline from sklearn.pipeline import FeatureUnion from sklearn.linear_model import LogisticRegression from sklearn.decomposition import PCA from sklearn.feature_selection import SelectKBest |
اکنون، ما باید مجموعه داده های دیابت پیما را بارگیری کنیم ، همانطور که در مثال های قبلی انجام شد –
|
1 2 3 4 |
path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=headernames) array = data.values |
بعد ، اتحادیه ویژگی ها به شرح زیر ایجاد می شود –
|
1 2 3 4 |
features = [] features.append(('pca', PCA(n_components=3))) features.append(('select_best', SelectKBest(k=6))) feature_union = FeatureUnion(features) |
بعد خط لوله با کمک خطوط زیر اسکریپت ایجاد می کند –
|
1 2 3 4 |
estimators = [] estimators.append(('feature_union', feature_union)) estimators.append(('logistic', LogisticRegression())) model = Pipeline(estimators) |
سرانجام ، ما می خواهیم این خط لوله را ارزیابی کنیم و صحت آن را به شرح زیر تولید کنیم –
|
1 2 3 |
kfold = KFold(n_splits=20, random_state=7) results = cross_val_score(model, X, Y, cv=kfold) print(results.mean()) |
خروجی
|
1 |
0.7789811066126855 |
خروجی فوق خلاصه ای از صحت تنظیمات روی مجموعه داده است.
لیست جلسات قبل آموزش یادگیری ماشین با پایتون
- آموزش یادگیری ماشین با پایتون
- مبانی یادگیری ماشین با پایتون
- آموزش اکوسیستم یادگیری ماشین با پایتون
- آموزش متدها در یادگیری ماشین با پایتون
- آموزش بارگیری داده ها برای پروژه های یادگیری ماشین
- آموزش درک داده ها با آمار در یادگیری ماشین
- آموزش آماده سازی داده ها در یادگیری ماشین با پایتون
- آموزش انتخاب ویژگی داده ها در یادگیری ماشین با پایتون
- آموزش طبقه بندی در یادگیری ماشین با پایتون
- آموزش رگرسیون لجستیک در یادگیری ماشین با پایتون
- آموزش ماشین بردار پشتیبان در یادگیری ماشین با پایتون
- آموزش درخت تصمیم در یادگیری ماشین با پایتون
- آموزش Naïve Bayes در یادگیری ماشین با پایتون
- آموزش جنگل تصادفی در یادگیری ماشین با پایتون
- آموزش الگوریتم های رگرسیون در یادگیری ماشین با پایتون
- آموزش الگوریتم های خوشه بندی در یادگیری ماشین با پایتون
- آموزش الگوریتم K-Means در یادگیری ماشین با پایتون
- آموزش الگوریتم تغییر میانگین در یادگیری ماشین با پایتون
- آموزش خوشه بندی سلسله مراتبی در یادگیری ماشین با پایتون
- آموزش یافتن نزدیکترین همسایه در یادگیری ماشین با پایتون
- آموزش معیارهای عملکرد در یادگیری ماشین با پایتون



.svg)
دیدگاه شما